
EDA 是数据科学工作流程的关键步骤,Pandas-profiling可以通过一行代码快速完成EDA报告,并且能够提供有意义的见解。
在我们上次介绍EDA工具时,一直将Pandas Profiling用作处理结构化表格数据的工具。但是在现实世界的应用中,我们日常生活中最长接触到的是时间序列数据:日常行动轨迹数据,电力和水资源消耗数据,它们都有一个共同点——对时间的依赖性。

由于时间序列数据的性质,在探索数据集时分析的复杂性随着在同一数据集中添加实体个数的增加而增加。在这篇文章中,我将利用 pandas-profiling 的时间序列特性,介绍EDA中的一些关键步骤。
我们这里使用的数据集是美国的空气质量数据集,可以从 EPA 网站下载。本文完整的代码和示例可以在 GitHub 中找到。
分析时间序列数据集中的多个实体
我们用的这个数据集是在美国、波多黎各和美属维尔京群岛的户外监测器上收集的空气质量数据。有了这些信息,我们就知道这是一个多元时间序列数据,其中有几个我们需要考虑的实体。
知道了这一点,就产生了一些后续问题:在涉及污染物措施方面,有多少个地点可用?所有传感器是否在同一时间跨度内收集相同数量的数据?收集到的措施在时间和地点上是如何分布的?
其中一些问题可以通过将所有测量值和位置与时间进行比较的热图回答,如下面的代码片段和图像所示:
from pandas_profiling.visualisation.plot import timeseries_heatmap
timeseries_heatmap(dataframe=df, entity_column='Site Num', sortby='Date Local')

上面的图表显示了每个实体随时间变化的数据点。我们看到并不是所有的气象站都在同一时间开始收集数据,根据热图的强度,我们可以看到在给定的时间段内,一些气象站比其他气象站拥有更多的数据点。这意味着在建模时间序列时,如果为训练和测试数据集提供动态时间戳可能比预先确定的时间戳更好。另外在EDA时还将进一步调查缺失的记录和记录的归属范围。”
有了对实体时间分布的基本理解之后,我们就可以开始深入研究数据分析以获得更多见解。因为有多个时间序列,让我们看看每个实体的行为。
深入了解时间序列指标
如果你已经在使用 pandas-profiling,可能知道如何生成报告。
在生成报告时可以通过传递参数 tsmode=true 来启用对时间序列的支持,并且该库将自动识别具有自相关性的特征(稍后会详细介绍)。为了使分析正常工作,df要按实体列和时间排序,或者利用 sortby 参数来自定义排序规则。
from pandas_profiling import ProfileReport
profile = ProfileReport(filtered_time_series_data, tsmode=True, sortby="Date Local")
profile.to_file('profile_report.html')
下面是使用时间序列模式的输出报告:
季节性和平稳性警报
要快速掌握时间序列,最简单的方法是查看报告的警告部分,可以发现两个新的警告-非平稳和季节性。对于这个特定的用例,每个概要报告将描述每个美国地点在污染物测量方面的特定行为。
以下是我们报告中的警告:
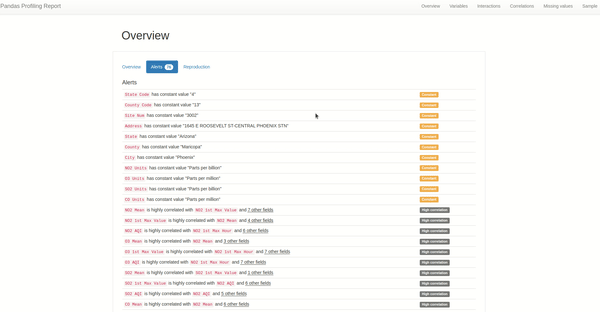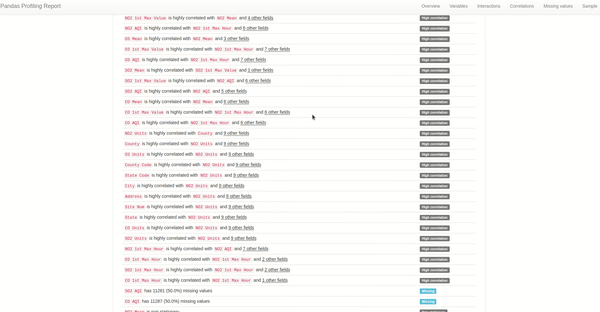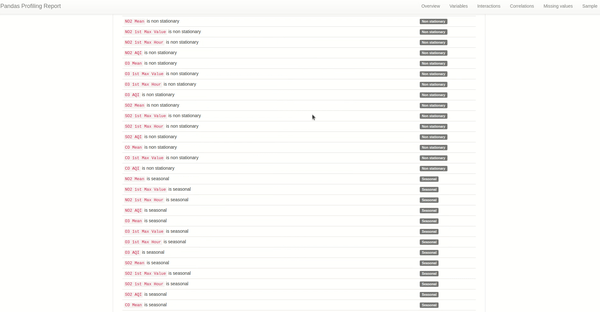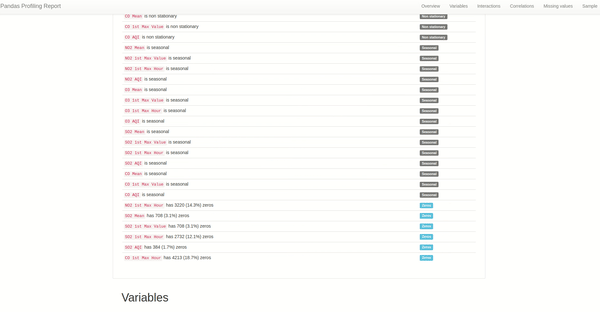
当时间序列的统计属性(例如均值和方差)不随时间序列的观察时间而变化时,就称该时间序列是平稳的。相反当时间序列的统计属性取决于时间时,它是非平稳的。例如具有趋势和季节性的时间序列(稍后会详细介绍)不是平稳的——这些现象会影响不同时间的时间序列的值。
平稳过程相对更容易分析,因为时间和变量之间存在静态关系。事实上平稳性已成为大多数时间序列分析的常见假设。
虽然有用于非平稳时间序列的模型,但大多数 ML 算法确实期望输入特征和输出之间存在静态关系。当时间序列不是平稳的时,从数据建模的模型准确性将在不同的点发生变化。这意味着建模选择会受到时间序列的平稳/非平稳性质的影响,并且当要将时间序列转换为平稳时,还需要额外的数据准备步骤。
总之,这个警报是非常重要的,因为它可以将帮助识别此类列并相应地预处理时间序列。
时间序列中的季节性是另一种场景,其中数据在定义的周期内重复出现的定期且可预测的变化。这种季节性可能会掩盖我们希望在时间序列建模时建模的信号,更糟糕的是它可能会为模型提供强烈的信号。
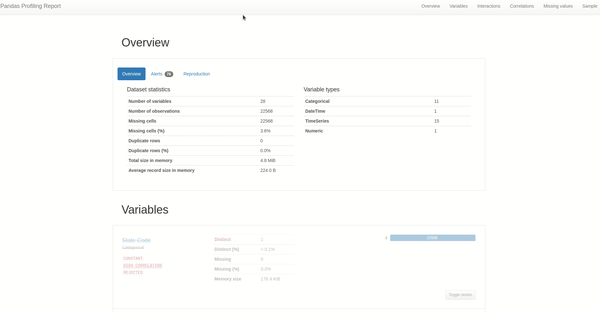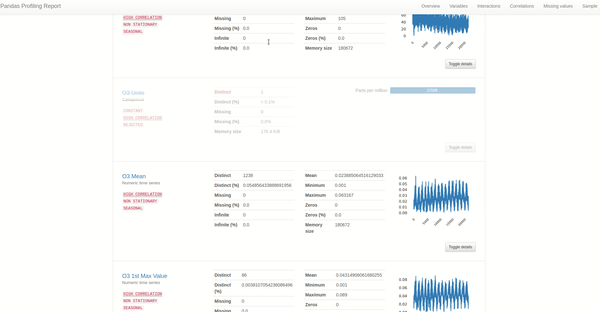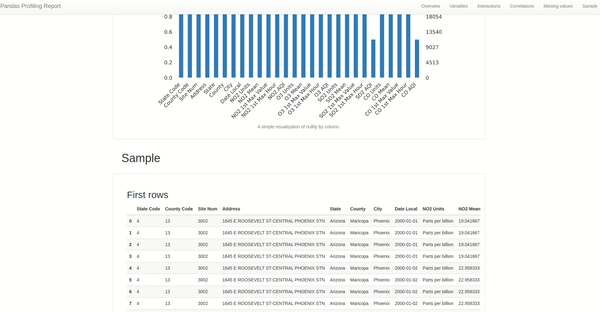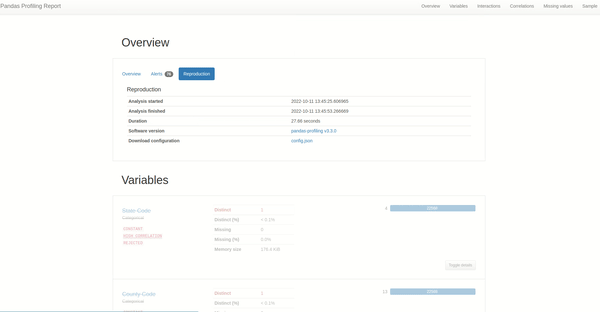
在上面的pandas-profiling图中你会注意到的第一个区别是线图将替换被识别为时间相关的列的直方图。使用折线图,我们可以更好地了解所选列的轨迹和性质。对于这个平均线图,我们可以看到轨迹呈下降趋势,具有连续的季节性变化,最大值记录出现在系列的初始阶段。
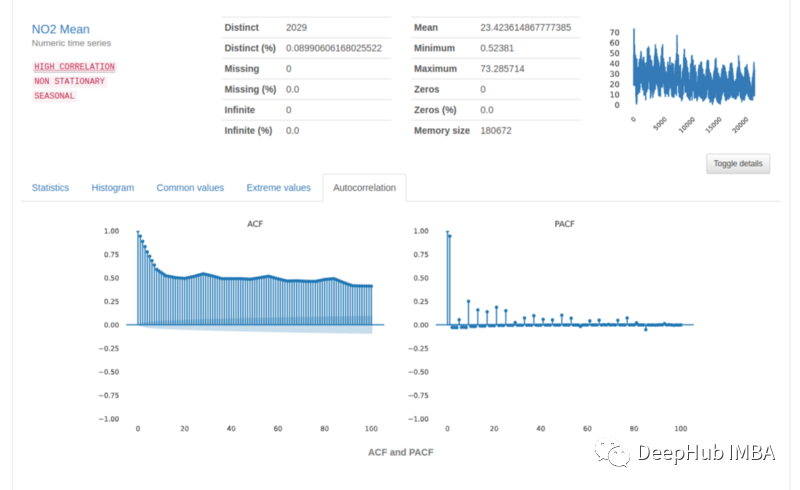
接下来,当切换该列的更多详细信息时(如上图所示),我们将看到一个带有自相关和偏自相关图的新选项卡。
对于时间序列,自相关显示时间序列现值处与其先前值的关系。偏自相关是去除先前时间滞后的影响后时间序列的自相关。这意味着这些图对于提供有关被分析序列的自相关度以及移动平均度的信息至关重要。
上面的 ACF 和 PACF 图有点模棱两可。但是在查看警告时可以看到 NO2 均值是一个非平稳时间变量,它消除了这些图的可解释性。ACF 图有助于确认我们怀疑的东西——NO2 平均值是非平稳的——因为 ACF 图值下降非常缓慢,而不是像平稳序列情况下所预期的那样快速下降到零。
从数据剖析中收集的信息、时间序列的性质以及非平稳和季节性等警报可以让你了解手头的时间序列数据。但这并不意味着已经完成了探索性数据分析——我们的目标是使用这些见解作为起点,进行进一步深入的数据分析和进一步的数据准备步骤。
通过分析空气质量数据集,我们看到有几列是恒定的,在建模时可能不会增加太多价值。从缺失值图表中还可以看到 SO2 和 CO2 空气质量指数存在缺失数据——所以应该进一步探索其影响以及插补或完全删除这些列的范围。发现有几列带有非平稳和季节性警报,所以数据处理的下一步是使它们平稳或确保我们的模型可以处理非平稳的数据点。
作为数据科学家,重要的是使用分析工具快速获取数据的整体视图(在我们的案例中是时间序列),并进一步检查数据预处理和建模阶段并做出明智的决策。
总结
正如Pandas Profiling 的口号那样:“读取数据,暂停并生成 Pandas 分析报告。检查数据,然后开始清理并重新探索数据。”
尽管结构化表格数据是最常见的数据,但时间序列数据也被广泛使用,并且是许多业务和高级数据驱动解决方案开发的核心。由于时间序列的性质以及记录是依赖于时间并影响未来的事件的,所以数据科学家需要在在探索性数据分析阶段找到不同的见解。
Pandas Profiling 可以从用户获取特定于时间序列的分析报告 - 包括提示数据要点的新警报、特定于时间序列分析的线图和相关图,这对于我们分析时间序列数据是非常有用的。
本文代码 https://github.com/ydataai/pandas-profiling/tree/master/examples/usaairquality
作者:Fabiana Clemente