
今天文章代码不涉密,数据不涉密,使用的是网上开源代码,做了修改,主要介绍如何实现的,另外,数据使用开放数据VisDrone的小部分数据来测试~
今天的文章很短,主要附带一个视频讲解运行过程,我修改的地方就不必说了,代码在文末,可以一键运行。
环境:需要安装:protobuf==3.20.1 其他库见官方yolo所需的环境;
运行顺序:第一步 原始训练,得到一个最优mAP等评价指标,记录在小本本上。
第二步:通过调整BN稀疏值(main 参数中的sr),运行train_sparity.py稀疏训练得到一个稍微小一点点的模型(和原始的精度比较,看看哪个稀疏值最好~)
第三步:将上一步的训练好的last.pt 放到prune.py 中进行剪枝,控制剪枝率;剪枝好的模型,在根目录下:pruned_model.pt 是fp32的,你除以2会得到最后的模型大小
第四步:Finetune,用刚刚的pruned模型重新训练,得到最优模型,就是最小且最快,且最好的啦~(和原始和稀疏训练的比较一下哦)
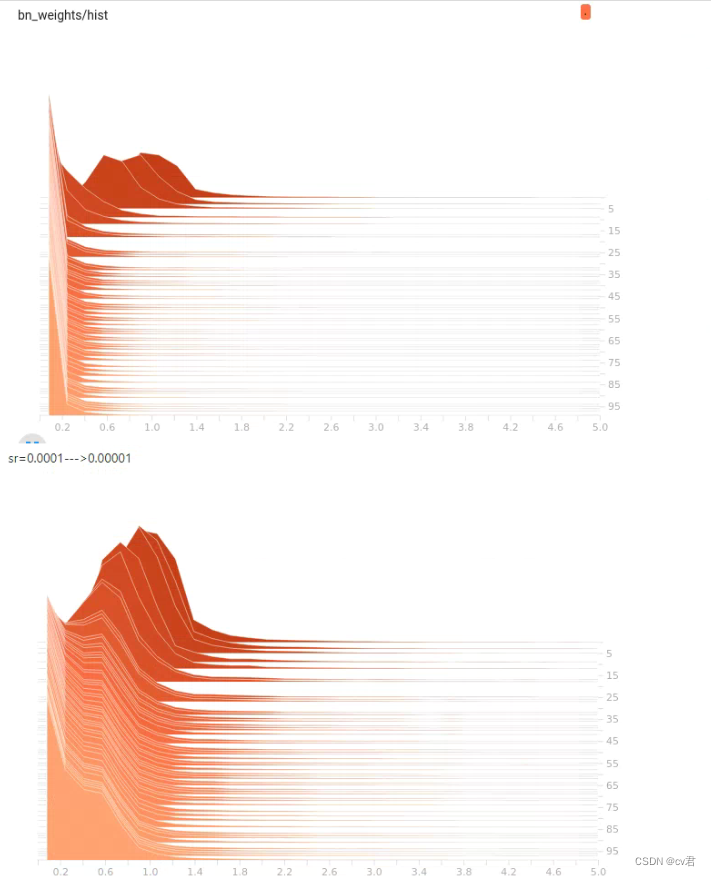
上面是俩个BN的可视化,我们调整稀疏训练里的st值,运行训练,然后用tensorboard可视化,看值即可~
当然如果你的稀疏训练效果和最优模型一样,那不用看tensorboarder,直接用这个训好的last.pt,去运行prune就好~
完整视频介绍:
《模型轻量化-剪枝蒸馏量化系列》YOLOv5无损剪枝(附源码)
稀疏训练部分代码
# # ============================= sparsity training ========================== #
srtmp = opt.sr*(1 - 0.9*epoch/epochs)
if opt.st:
ignore_bn_list = []
for k, m in model.named_modules():
if isinstance(m, Bottleneck):
if m.add:
ignore_bn_list.append(k.rsplit(".", 2)[0] + ".cv1.bn")
ignore_bn_list.append(k + '.cv1.bn')
ignore_bn_list.append(k + '.cv2.bn')
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
# # ============================= sparsity training ========================== #
# Optimize
# if ni - last_opt_step >= accumulate:
optimizer.step()
# scaler.step(optimizer) # optimizer.step
# scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
# last_opt_step = ni
# Log
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
核心部分:
就是把稀疏加权到原有值中,让这些BN不发挥作用。
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
Prune剪枝部分代码
这边我改过部分,因为每层bn都必须有至少一个维度,所以,剪枝率过高,会全部干掉,就会报错。
所以我代码中修改后,大家正常运行就行,不会出现了~
model_list = {}
ignore_bn_list = []
for i, layer in model.named_modules():
# if isinstance(layer, nn.Conv2d):
# print("@Conv :",i,layer)
if isinstance(layer, Bottleneck):
if layer.add:
ignore_bn_list.append(i.rsplit(".",2)[0]+".cv1.bn")
ignore_bn_list.append(i + '.cv1.bn')
ignore_bn_list.append(i + '.cv2.bn')
if isinstance(layer, torch.nn.BatchNorm2d):
if i not in ignore_bn_list:
model_list[i] = layer
# print(i, layer)
# bnw = layer.state_dict()['weight']
model_list = {k:v for k,v in model_list.items() if k not in ignore_bn_list}
# print("prune module :",model_list.keys())
prune_conv_list = [layer.replace("bn", "conv") for layer in model_list.keys()]
# print(prune_conv_list)
bn_weights = gather_bn_weights(model_list)
sorted_bn = torch.sort(bn_weights)[0]
# print("model_list:",model_list)
# print("bn_weights:",bn_weights)
# 避免剪掉所有channel的最高阈值(每个BN层的gamma的最大值的最小值即为阈值上限)
highest_thre = []
for bnlayer in model_list.values():
highest_thre.append(bnlayer.weight.data.abs().max().item())
# print("highest_thre:",highest_thre)
highest_thre = min(highest_thre)
# 找到highest_thre对应的下标对应的百分比
percent_limit = (sorted_bn == highest_thre).nonzero()[0, 0].item() / len(bn_weights)
print(f'Suggested Gamma threshold should be less than {highest_thre:.4f}.')
print(f'The corresponding prune ratio is {percent_limit:.3f}, but you can set higher.')
# assert opt.percent < percent_limit, f"Prune ratio should less than {percent_limit}, otherwise it may cause error!!!"
# model_copy = deepcopy(model)
thre_index = int(len(sorted_bn) * opt.percent)
thre = sorted_bn[thre_index]
print(f'Gamma value that less than {thre:.4f} are set to zero!')
print("=" * 94)
print(f"|\t{'layer name':<25}{'|':<10}{'origin channels':<20}{'|':<10}{'remaining channels':<20}|")
remain_num = 0
modelstate = model.state_dict()
mask掉部分channel
maskbndict = {}
for bnname, bnlayer in model.named_modules():
if isinstance(bnlayer, nn.BatchNorm2d):
bn_module = bnlayer
mask = obtain_bn_mask(bn_module, thre)
if bnname in ignore_bn_list:
mask = torch.ones(bnlayer.weight.data.size()).cuda()
maskbndict[bnname] = mask
# print("mask:",mask)
remain_num += int(mask.sum())
bn_module.weight.data.mul_(mask)
bn_module.bias.data.mul_(mask)
# print("bn_module:", bn_module.bias)
print(f"|\t{bnname:<25}{'|':<10}{bn_module.weight.data.size()[0]:<20}{'|':<10}{int(mask.sum()):<20}|")
assert int(mask.sum()) > 0, "Current remaining channel must greater than 0!!! please set prune percent to lower thesh, or you can retrain a more sparse model..."
print("=" * 94)
# print(maskbndict.keys())
pruned_model = ModelPruned(maskbndict=maskbndict, cfg=pruned_yaml, ch=3).cuda()
# Compatibility updates
for m in pruned_model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
m.inplace = True # pytorch 1.7.0 compatibility
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
from_to_map = pruned_model.from_to_map
pruned_model_state = pruned_model.state_dict()
通道改变要修改:
changed_state = []
for ((layername, layer),(pruned_layername, pruned_layer)) in zip(model.named_modules(), pruned_model.named_modules()):
assert layername == pruned_layername
if isinstance(layer, nn.Conv2d) and not layername.startswith("model.24"):
convname = layername[:-4]+"bn"
if convname in from_to_map.keys():
former = from_to_map[convname]
if isinstance(former, str):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
w = layer.weight.data[:, in_idx, :, :].clone()
if len(w.shape) ==3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(former, list):
orignin = [modelstate[i+".weight"].shape[0] for i in former]
formerin = []
for it in range(len(former)):
name = former[it]
tmp = [i for i in range(maskbndict[name].shape[0]) if maskbndict[name][i] == 1]
if it > 0:
tmp = [k + sum(orignin[:it]) for k in tmp]
formerin.extend(tmp)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
pruned_layer.weight.data = w[:,formerin, :, :].clone()
changed_state.append(layername + ".weight")
else:
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
assert len(w.shape) == 4
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(layer,nn.BatchNorm2d):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[out_idx].clone()
pruned_layer.bias.data = layer.bias.data[out_idx].clone()
pruned_layer.running_mean = layer.running_mean[out_idx].clone()
pruned_layer.running_var = layer.running_var[out_idx].clone()
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
changed_state.append(layername + ".running_mean")
changed_state.append(layername + ".running_var")
changed_state.append(layername + ".num_batches_tracked")
if isinstance(layer, nn.Conv2d) and layername.startswith("model.24"):
former = from_to_map[layername]
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[:, in_idx, :, :]
pruned_layer.bias.data = layer.bias.data
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
missing = [i for i in pruned_model_state.keys() if i not in changed_state]
pruned_model.eval()
pruned_model.names = model.names
# =============================================================================================== #
torch.save({"model": model}, "orign_model.pt")
model = pruned_model
torch.save({"model":model}, "pruned_model.pt")
model.cuda().eval()
v5s:14mb ——> 90%剪枝:2.4mb左右
v5n: 3.6mb ——>80%剪枝: 700kb左右,6w张数据中精度无损哦, 95%剪枝掉了5个点左右,小问题
最后,至于说,让自己模型无损,那就不断地尝试:稀疏训练完是无损的,且prune完的嘛模型去Finetune完也是无损的,就成功!
另外prune.py运行时的剪枝完的模型, P R mAP 都是0哦,需要finetune完,才恢复精度
更改算法后,如何剪枝?
可以剪,按原套路做,不过会有坑,后续大家进交流群一起讨论解决吧~
完整代码:
链接:https://pan.baidu.com/s/1YnJWHHsvlX4ZLhUf6IxT8Q
提取码:ug6l
目前我的DeepAI 视界社区大升级,目前在计算机视觉算法优化、算法部署、模型轻量化、多模态算法都会大大提高未来也会写更多,新方向的文章,大家欢迎mark,转发,三连
ps(文章目前免费~,大约数个星期后会移入我的付费专栏)
我的微信群:(过期后加我微信:zxx15277368495z)
版权归原作者 cv君 所有, 如有侵权,请联系我们删除。