
文章目录
一,前言
1.1 本文基于原理
大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的数值表示。
大部分情况下,收集得到的数据需要经过处理后才能够为算法所使用。通常情况下,一个数据集当中存在很多种不同的特征,其中一些可能是多余的或者与我们要预测的值无关的,可通过数据处理和可视化进行筛选。
特征选择技术的必要性也体现在简化模型、减少训练时间、避免维度爆炸和提升泛化性避免过拟合。
1.2 目的
1.熟悉机器学习之数据处理与可视化方法
2.使用数据处理与可视化方法分析数据特征
1.3 目标以及内容
1.安装scikit-learn机器学习及其相关的python包;
2.在程序里下载鸢尾花数据集;
3.使用matplotlib对鸢尾花数据集的特征两两对比绘图;
4.对绘出的鸢尾花可视化图分析哪些特征可明显区分出鸢尾花类别;
1.4 本文基于环境
1.PC机
2.Windows10
3.Scikit-learn安装包
4.jupyter编辑器或pycharm等python编辑器
二,实验过程
2.1 安装scikit-learn机器学习相关的模块
安装过程略,直接安装scikit-learn模块,可以采用国内镜像安装,比较节省时间。
输入
pip show scikit-learn
检测一下本机环境是否成功安装【scikit-learn】本模块。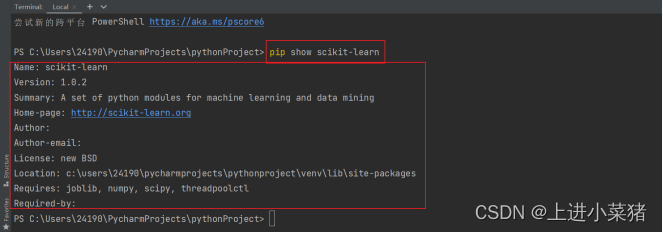
2.2 在程序里下载鸢尾花数据集
我们这里采用load_iris数据集,一共包括150行记录,其中前四列为花萼长度,花萼宽度,花瓣长度,花瓣宽度4个识别鸢尾花的属性,‘sepal_len’,‘sepal_wid’,‘petal_len’,‘petal_wid’。
第5列为鸢尾花的类别(包括Setosa,Versicolour,Virginica三类)
代码如下
1.import matplotlib.pyplot asplt2.from sklearn.datasets import load_iris
3.iris =load_iris()4.X = iris.data
5.print(X.shape, X)
我们输出X来看一下这150组数据: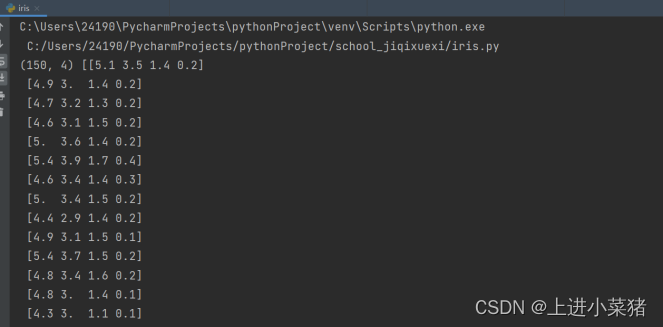
2.3 使用matplotlib对鸢尾花数据集的特征两两对比绘图
因为我们会使用figure方法,我们先定义一下大小,让16个子图可以合适的输出。如下代码:
plt.figure(figsize=(44,44))
我们需要输出16个子图,设置变量为4,遍历俩次。
feature_max_num=4
遍历俩次,如下:
for feature inrange(feature_max_num):for feature_other inrange(feature_max_num):
可以想象一下:
分别是 0-0,0-1,0-2,0-3,1-0,1-1……
有16种组合,还需取特征值要用。
我们需要设置一下每个子图的位置,可以依次画出这些子图,优点是简单明了,缺点是略显麻烦。
如下代码:
plt.subplot(feature_max_num,feature_max_num,feature*feature_max_num+feature_other +1,frame_on= True)
我们需要思考一下,如果0-0,1-1,2-2,这种属于特殊情况,我们分别处理一下。
plt.scatter的属性我们需要了解一下:如下
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None,
vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, hold=None, data=None, **kwargs)
- x, y → 散点的坐标
- s → 散点的面积
- c → 散点的颜色(默认值为蓝色,‘b’,其余颜色同plt.plot( ))
- marker→ 散点样式(默认值为实心圆,‘o’,其余样式同plt.plot( )) alpha → 散点透明度([0,1]之间的数,0表示完全透明,1则表示完全不透明)
- linewidths →散点的边缘线宽 edgecolors → 散点的边缘颜色
if feature==feature_other: #特殊情况
如果,feature==feature_other,遍历值相同的话,x, y → 散点的坐标是相同的,这不是很直观,我们直接把x散点的坐标设置一个自增变量,让它从0到49自增。
plt.scatter([i for i inrange(50)],X[0:50,feature],color='green',marker='o',label='setosa')......
其他情况的话:x, y → 散点的坐标是不同,正常进行绘制即可
else:
plt.scatter(X[0:50,feature],X[0:50,feature_other],color='green',marker='o',label='setosa')......
上述代码解释:
X[0:50,feature],X[0:50,feature_other]
分别代表x, y → 散点的坐标,因为上文我们有150组目标数据,我们根据不同的特征值从数据集里获取到我们需要目标数据集。进行绘图处理。
需要了解语法:
a[:,1]的含义,即可看懂。
下面我们需要设置X轴和Y轴的标签。语法如下:
xlabel(xlabel, fontdict=None, labelpad=None, *, loc=None, **kwargs)
- xlabel:类型为字符串,即标签的文本。
- fontdict: dict, 一个字典用来控制标签的字体样式
- labelpad:类型为浮点数,默认值为None,即标签与坐标轴的距离。
- loc:取值范围为{‘left’, ‘center’, ‘right’},默认值为rcParams[“xaxis.labellocation”](‘center’),即标签的位置。
- **kwargs:Text 对象关键字属性,用于控制文本的外观属性,如字体、文本颜色等。
plt.xlabel(iris.feature_names[feature])
plt.vlabel(iris.feature_names[feature_other])
最后设置图例位置,输出图像。
plt.legend(loc='best')
plt.show()
效果图如下: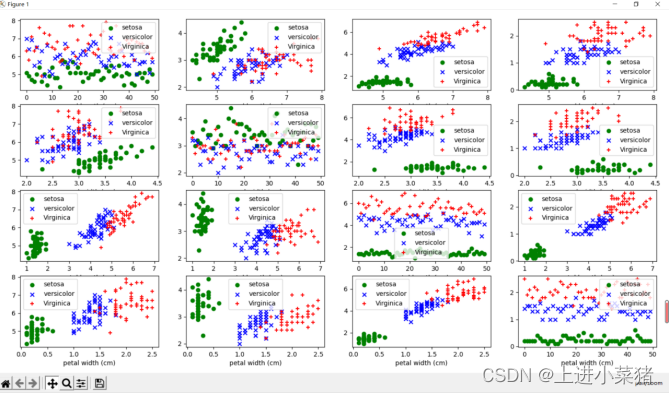
2.4 对绘出的鸢尾花可视化图分析哪些特征可明显区分出鸢尾花类别
根据图0-2 ,1-3层次分明。
可以看出萼片长度和花瓣长度,萼片宽度和花瓣宽度特征可明显区分出鸢尾花类别。
三,附本文涉及到的源码
本文涉及到的源码如下,可以直接运行:
import matplotlib.pyplot aspltfrom sklearn.datasets import load_iris
iris =load_iris()
X =iris.data
print(X.shape, X)
plt.figure(figsize=(44,44))
feature_max_num=4for feature inrange(feature_max_num):for feature_other inrange(feature_max_num):
plt.subplot(feature_max_num,feature_max_num,feature*feature_max_num+feature_other +1,frame_on= True)if feature==feature_other:
plt.scatter([i for i inrange(50)],X[0:50,feature],color='green',marker='o',label='setosa')
plt.scatter([i for i inrange(50)],X[50:100,feature],color='blue',marker='x',label='versicolor')
plt.scatter([i for i inrange(50)],X[100:,feature],color='red',marker='+',label='Virginica')else:
plt.scatter(X[0:50,feature],X[0:50,feature_other],color='green',marker='o',label='setosa')
plt.scatter(X[50:100,feature],X[50:100,feature_other],color='blue',marker='x',label='versicolor')
plt.scatter(X[100:,feature],X[100:,feature_other],color="red",marker='+',label='Virginica')
plt.xlabel(iris.feature_names[feature])
plt.vlabel(iris.feature_names[feature_other])
plt.legend(loc='best')
plt.show()
版权归原作者 上进小菜猪 所有, 如有侵权,请联系我们删除。