

KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中最简单的算法之一,其指导思想是”近朱者赤,近墨者黑“,即由你的邻居来推断出你的类别。
介绍算法的例子

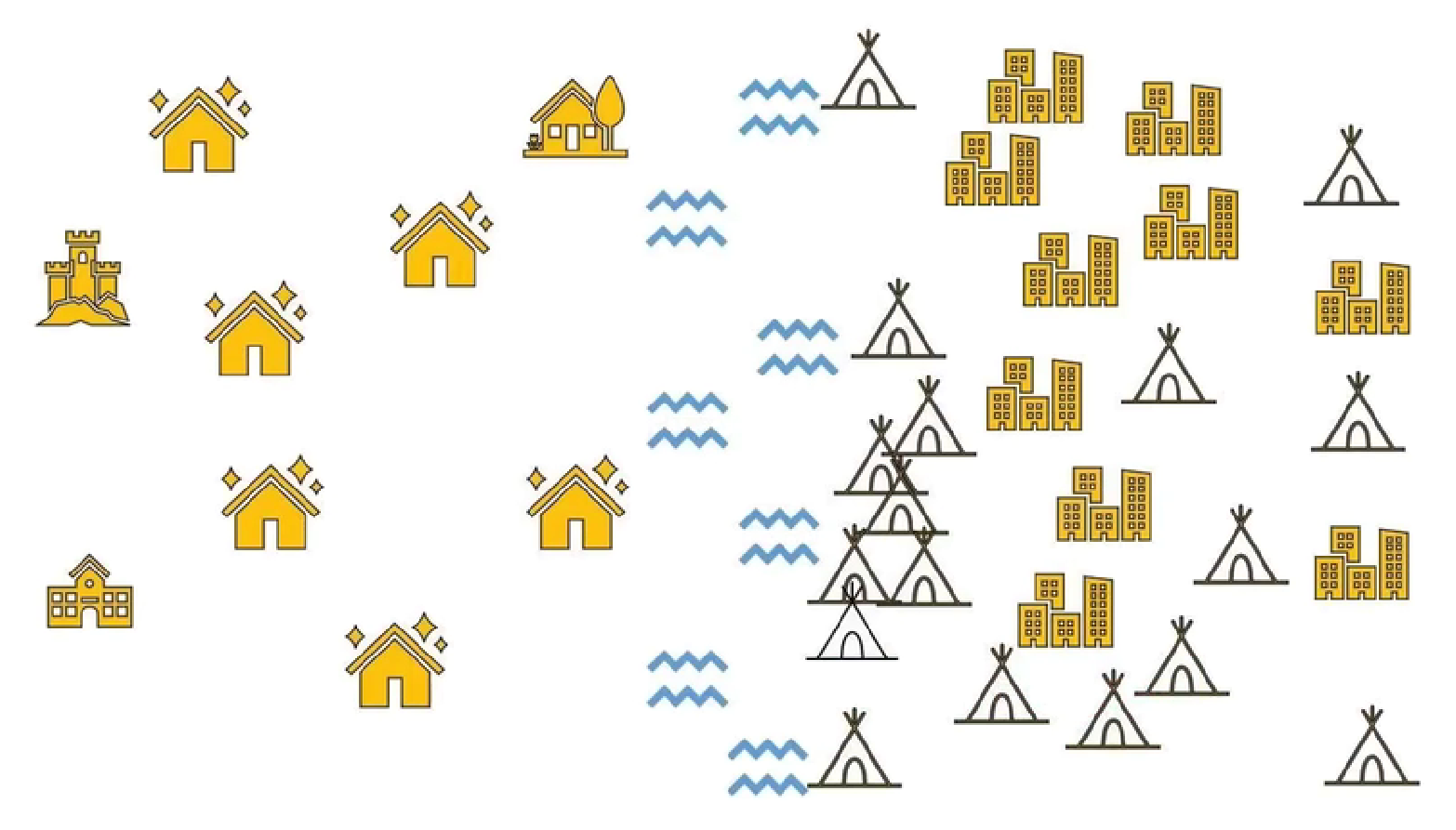
小河的左侧是有钱人的别墅,右侧是普通的居民,
如果左侧搬来了一家房屋,能确定他是有钱人吗?
KNN算法原理
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
一句话解释KNN算法原理:

KNN算法的关键:
(1) 样本的所有特征都要做可比较的量化
若是样本特征中存在非数值的类型,必须采取手段将其量化为数值。例如样本特征中包含颜色,可通过将颜色转换为灰度值来实现距离计算。
(2) 样本特征要做归一化处理
样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些 scale 处理,最简单的方式就是所有特征的数值都采取归一化处置。
(3) 需要一个距离函数以计算两个样本之间的距离
通常使用的距离函数有:**欧氏距离、余弦距离、汉明距离、曼哈顿距离**等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
算法的优点:

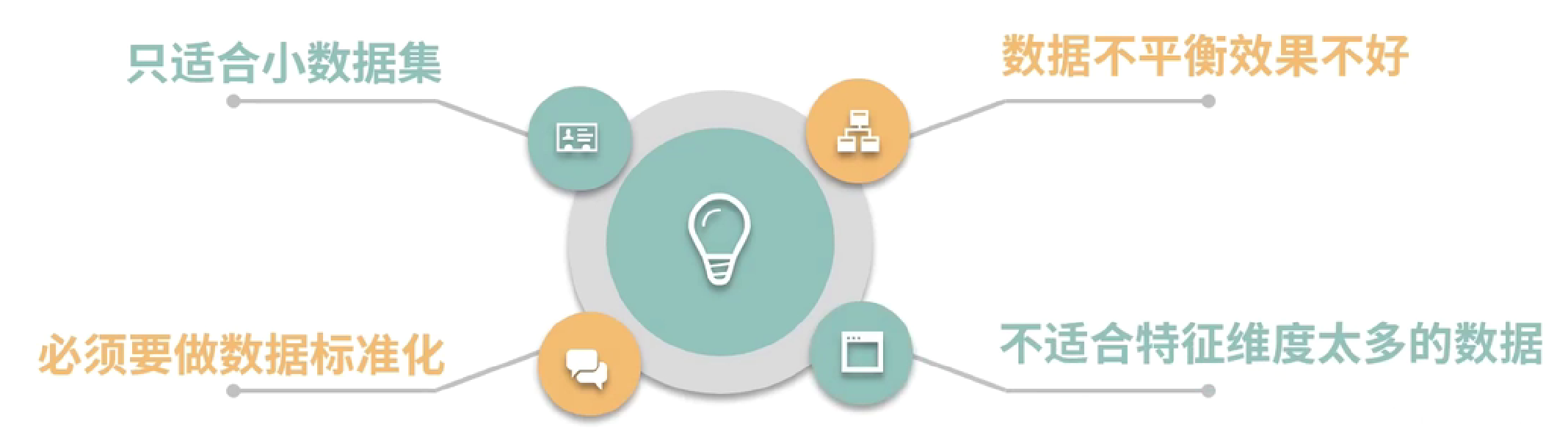
算法的缺点:
关于k值的选取
K值的选取会影响到模型的效果
K越小的时候容易过拟合,K越大的时候容易欠拟合。
合适的K值需要根据经验和效果去进行尝试。
代码实现
先导入sklearn的数据集。
和sklearn的KNN模块。
from sklearn import datasets #sklearn的数据集
from sklearn.neighbors import KNeighborsClassifier #sklearn模块的KNN类
import numpy as np #矩阵运算库numpy
np.random.seed(0)
#设置随机种子,不设置的话默认是按系统时间作为参数,设置后可以保证我们每次产生的随机数是一样的
获取数据集,并且对数据集进行分类为训练集和测试集。
iris=datasets.load_iris()#获取鸢尾花数据集
iris_x=iris.data #数据部分
iris_y=iris.target #类别部分
#从150条数据中选140条作为训练集,10条作为测试集。permutation接收一个数作为参数(这里为数据集长度150),产生一个0-149乱序一维数组
randomarr=np.random.permutation(len(iris_x))
iris_x_train= iris_x[randomarr[:-10]]#训练集数据
iris_y_train= iris_y[randomarr[:-10]]#训练集标签
iris_x_test = iris_x[randomarr[-10:]]#测试集数据
iris_y_test = iris_y[randomarr[-10:]]#测试集标签
#定义一个knn分类器对象
knn = KNeighborsClassifier()
#调用该对象的训练方法,主要接收两个参数:训练数据集及其类别标签
knn.fit(iris_x_train, iris_y_train)
#调用预测方法,主要接收一个参数:测试数据集
iris_y_predict= knn.predict(iris_x_test)
输出测试的结果:
#计算各测试样本预测的概率值这里我们没有用概率值,但是在实际工作中可能会参考概率值来进行最后结果的筛选,而不是直接使用给出的预测标签
probility=knn.predict_proba(iris_x_test)
#计算与最后一个测试样本距离最近的5个点,返回的是这些样本的序号组成的数组
neighborpoint=knn.kneighbors([iris_x_test[-1]],5)
#调用该对象的打分方法,计算出准确率
score=knn.score(iris_x_test,iris_y_test,sample_weight=None)
#输出测试的结果
print('iris_y_predict=')
print(iris_y_predict)
#输出原始测试数据集的正确标签,以方便对比print('iris_y_test=')
print(iris_y_test)
Accuracy: 0.9
总结
1、介绍了KNN分类算法原理和重点。
2、从一个例子开始,引入了它的原理,并希望你能了解它的优缺点写出了一段简单的代码。
本文转载自: https://blog.csdn.net/lxwssjszsdnr_/article/details/127550222
版权归原作者 Lingxw_w 所有, 如有侵权,请联系我们删除。
版权归原作者 Lingxw_w 所有, 如有侵权,请联系我们删除。