
Deephub
更多文章请关注公众号:Deephub-IMBA

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。

对OpenAI CEO奥特曼突然被解雇事件的一些分析
今天也来凑个热闹,说说OpenAI的事。
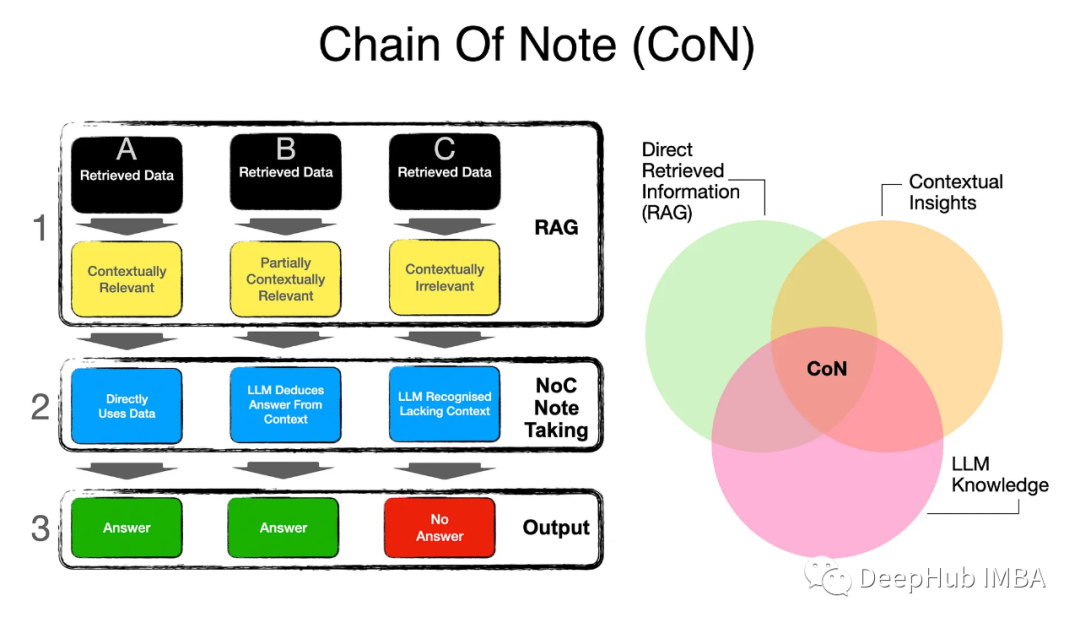
Chain-Of-Note:解决噪声数据、不相关文档和域外场景来改进RAG的表现
这是腾讯实验室在11月最新发布的一篇论文,CoN的核心思想是生成连续的阅读笔记对于检索到的文档,能够对其与给出问题并综合这些信息来形成最终的答案,提高了RAG的表现。

Python中的实例属性和类属性
在这篇文章中,我们将探讨Python中的类是如何工作的,主要介绍实例和类的属性。这些属性是什么,它们之间的区别,以及创建和利用它们的python方法。
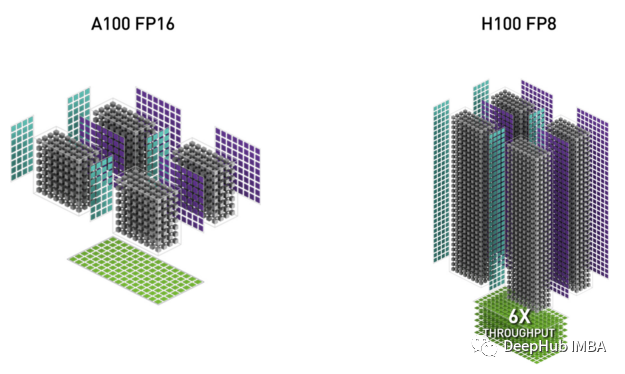
使用FP8加速PyTorch训练
在这篇文章中,我们将介绍如何修改PyTorch训练脚本,利用Nvidia H100 GPU的FP8数据类型的内置支持。
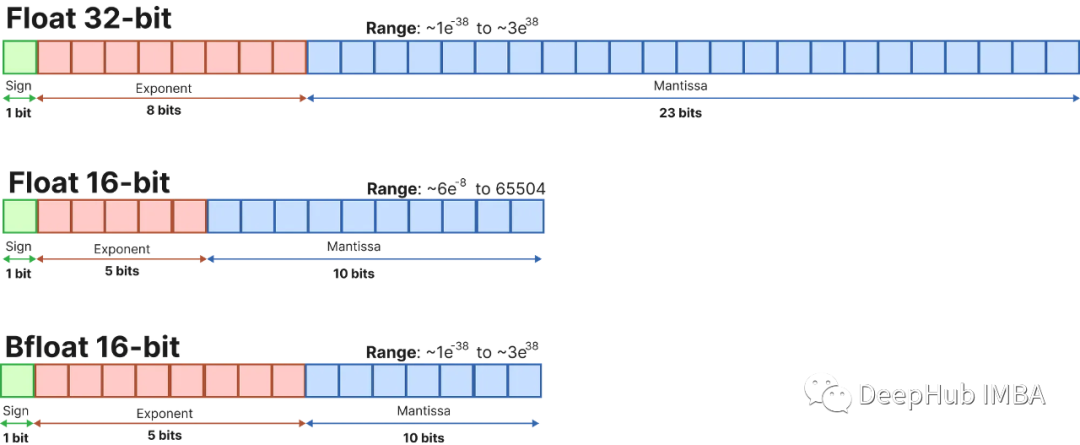
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
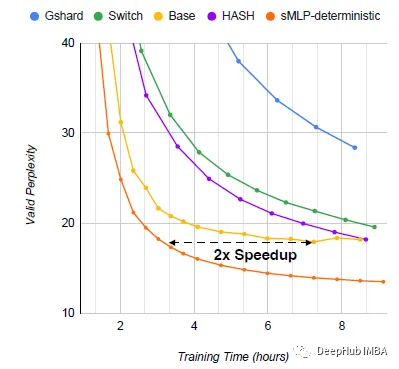
sMLP:稀疏全mlp进行高效语言建模
论文提出了sMLP,通过设计确定性路由和部分预测来解决下游任务方面的问题。

神经网络中的量化与蒸馏
本文将深入研究深度学习中精简模型的技术:量化和蒸馏
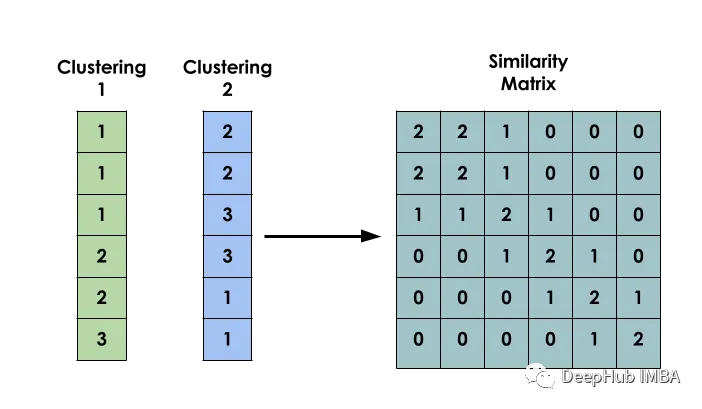
无监督学习的集成方法:相似性矩阵的聚类
在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。
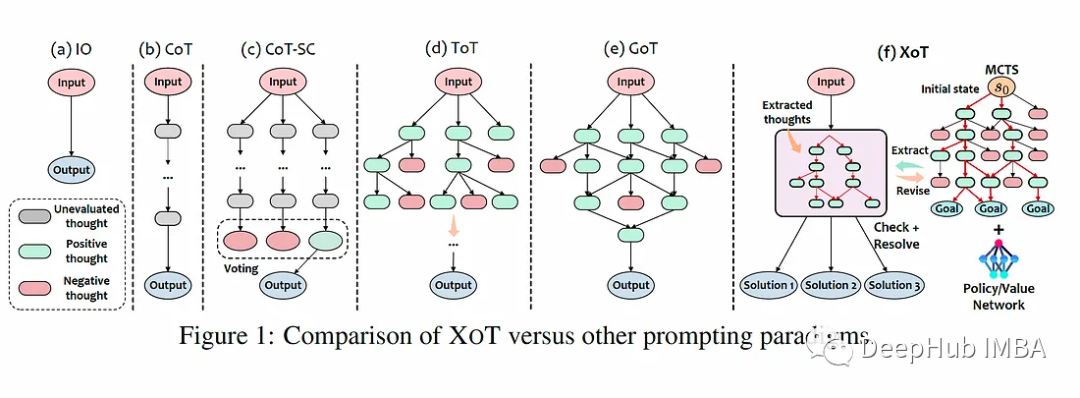
XoT:一种新的大语言模型的提示技术
这是微软在11月最新发布的一篇论文,它增强了像GPT-3和GPT-4这样的大型语言模型(llm)解决复杂问题的潜力。
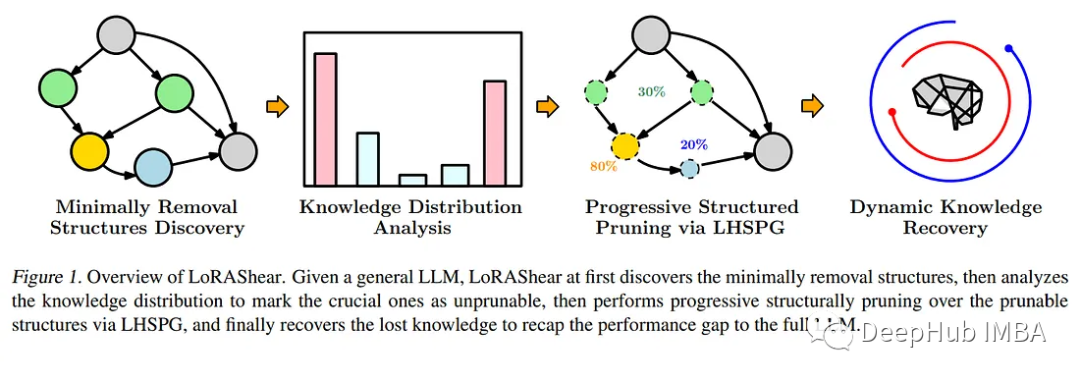
LoRAShear:微软在LLM修剪和知识恢复方面的最新研究
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。
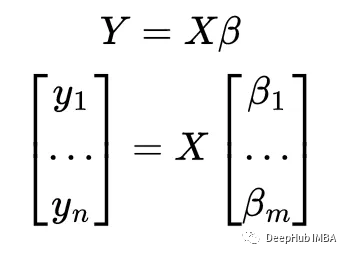
线性回归,核技巧和线性核
在这篇文章中,我想展示一个有趣的结果:线性回归与无正则化的线性核ridge回归是等 价的。
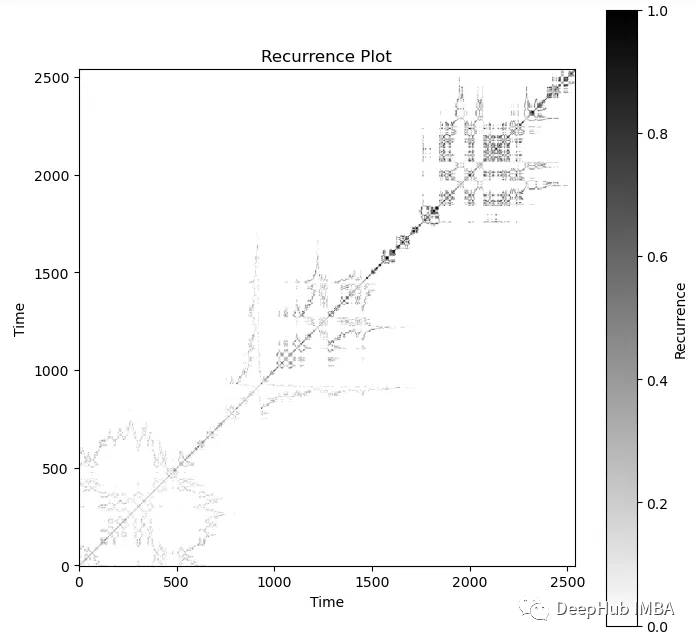
使用递归图 recurrence plot 表征时间序列
在本文中,我将展示如何使用递归图 Recurrence Plots 来描述不同类型的时间序列。
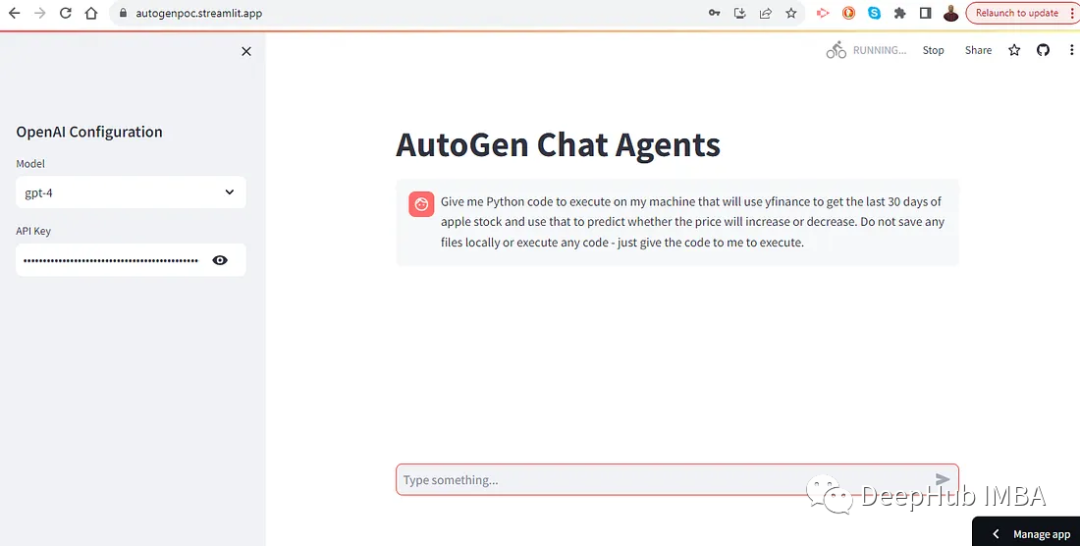
使用Streamlit创建AutoGen用户界面
我们来对AutoGen进行改造,使用Streamlit创建一个web界面,这样可以让我们更好的与其交互。
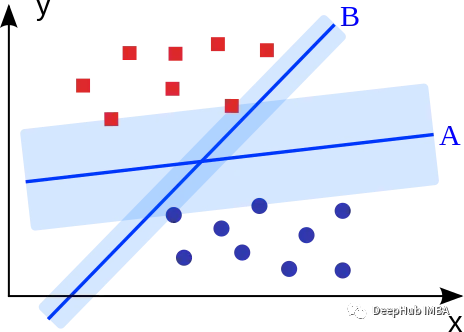
使用Python从零实现多分类SVM
本文将首先简要概述支持向量机及其训练和推理方程,然后将其转换为代码以开发支持向量机模型。之后然后将其扩展成多分类的场景,并通过使用Sci-kit Learn测试我们的模型来结束。
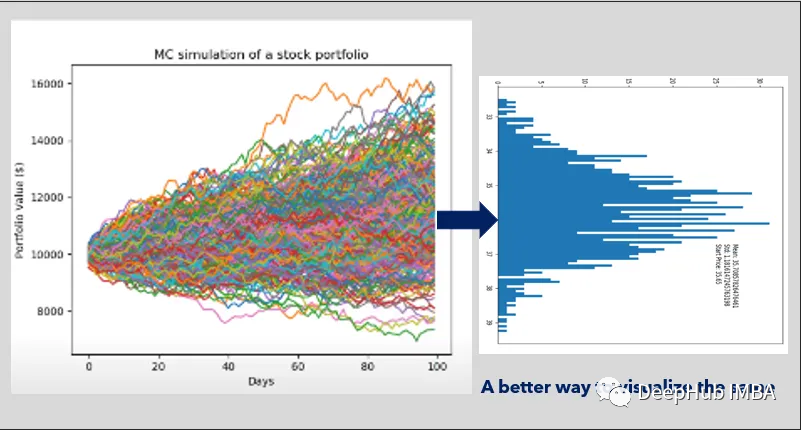
使用蒙特卡罗模拟的投资组合优化
在金融市场中,优化投资组合对于实现风险与回报之间的预期平衡至关重要。蒙特卡罗模拟提供了一个强大的工具来评估不同的资产配置策略及其在不确定市场条件下的潜在结果。
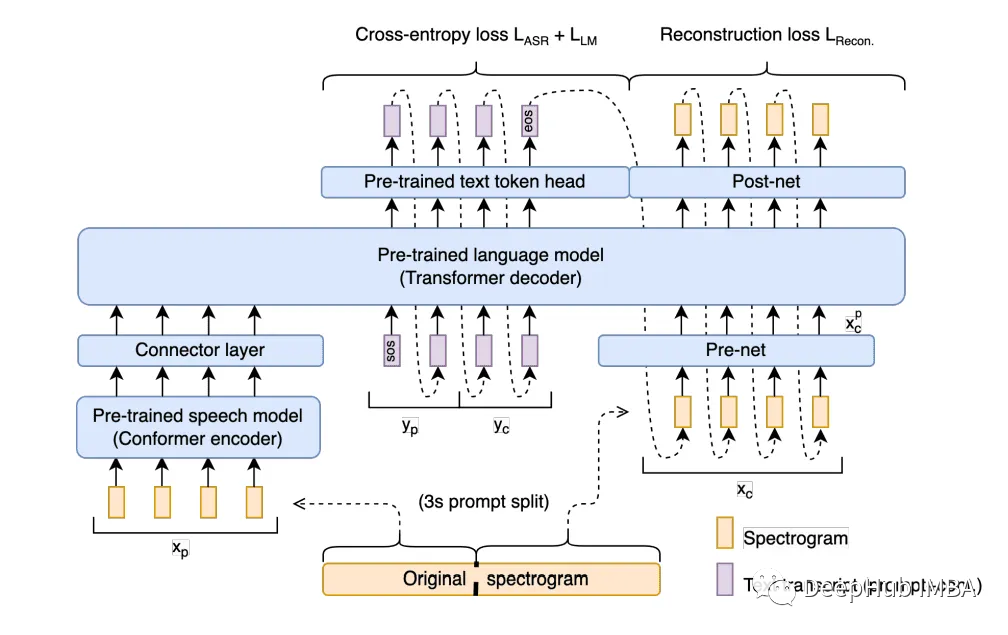
Spectron: 谷歌的新模型将语音识别与语言模型结合进行端到端的训练
Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差,增强表征保真度,提高音频生成质量。
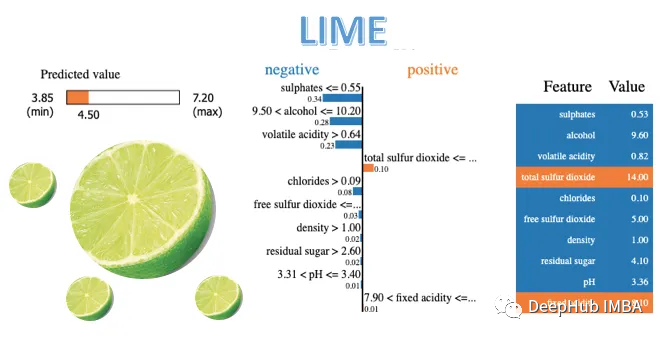
使用LIME解释各种机器学习模型代码示例
在本文中,我们将介绍LIME,并使用它来解释各种常见的模型。
10月发布的5篇人工智能论文推荐
10月发布的5篇人工智能论文推荐

数据抽样技术全面概述
抽样是研究和数据收集中不可或缺的方法,能够从更大数据中获得有意义的见解并做出明智的决定的子集。不同的研究领域采用了不同的抽样技术,每种技术都有其独特的优点和局限性。