
Deephub
更多文章请关注公众号:Deephub-IMBA
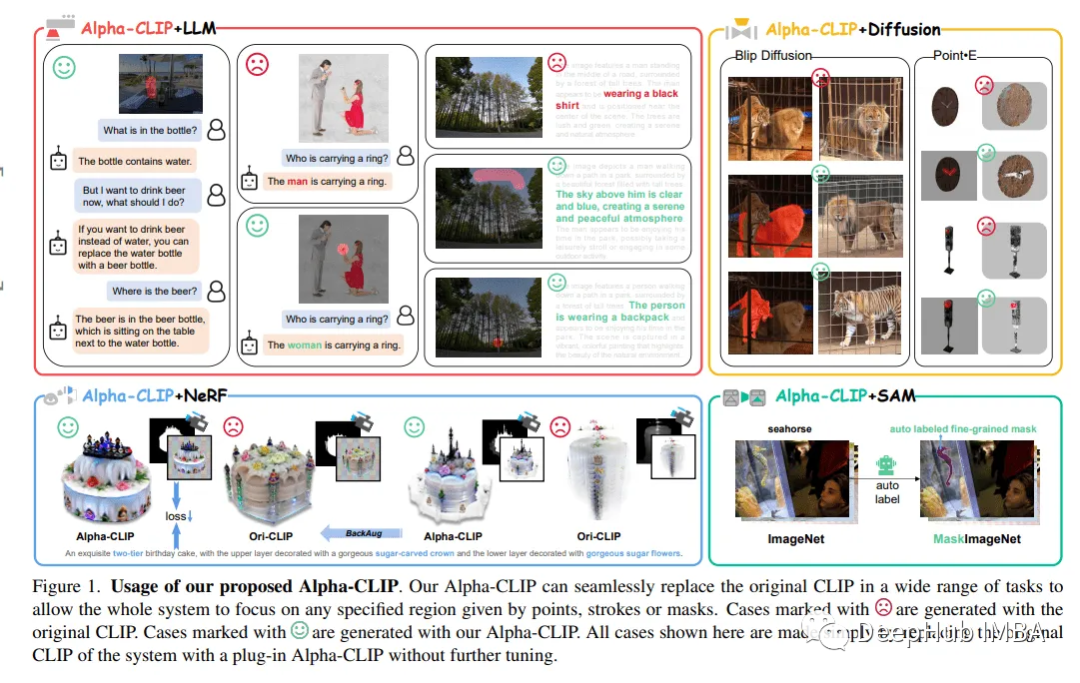
CLIP的升级版Alpha-CLIP:区域感知创新与精细控制
Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。
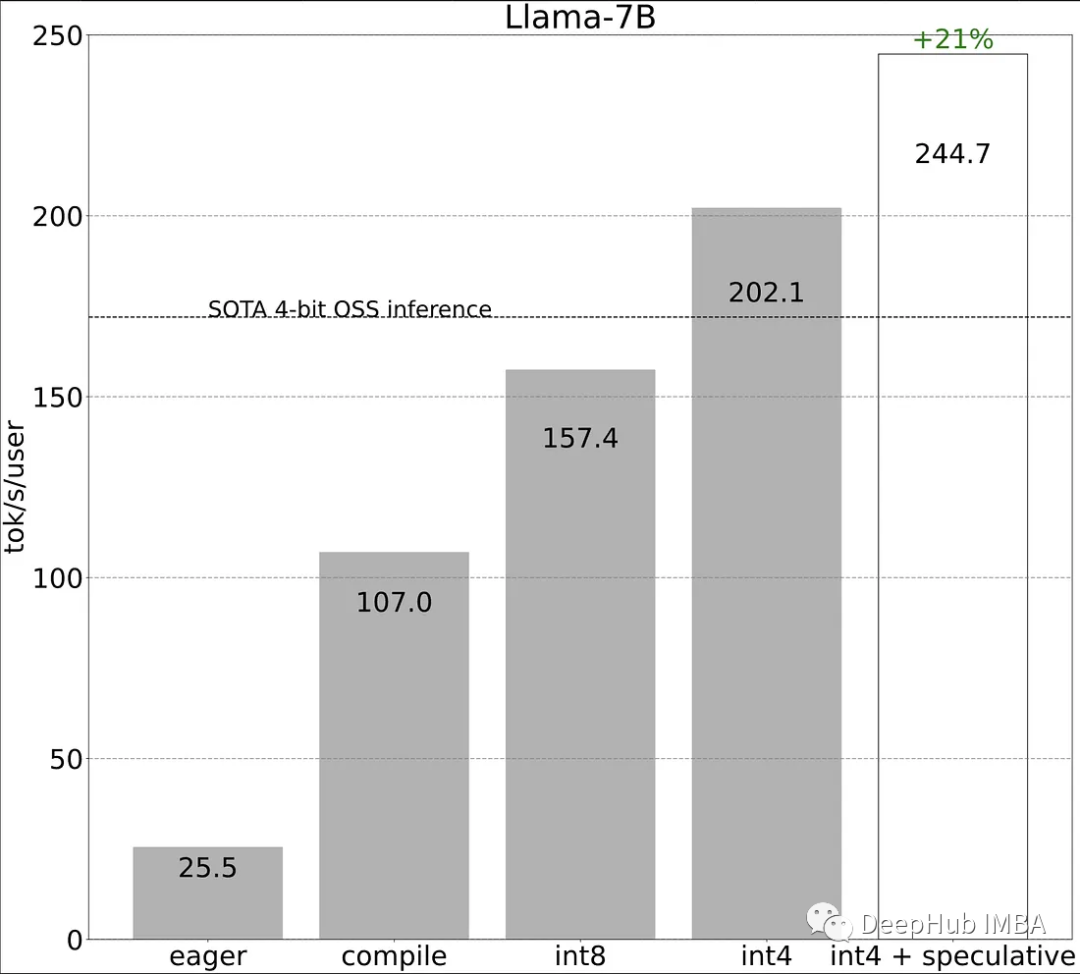
使用PyTorch II的新特性加快LLM推理速度
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法
System 2 Attention:可以提高不同LLM问题的推理能力
S2A是LLM推理方法发展的一个重要里程碑。该方法与人类推理非常相似,避免了干扰。我们应该期待S2A在最近几个月成为推理研究的重要基线。
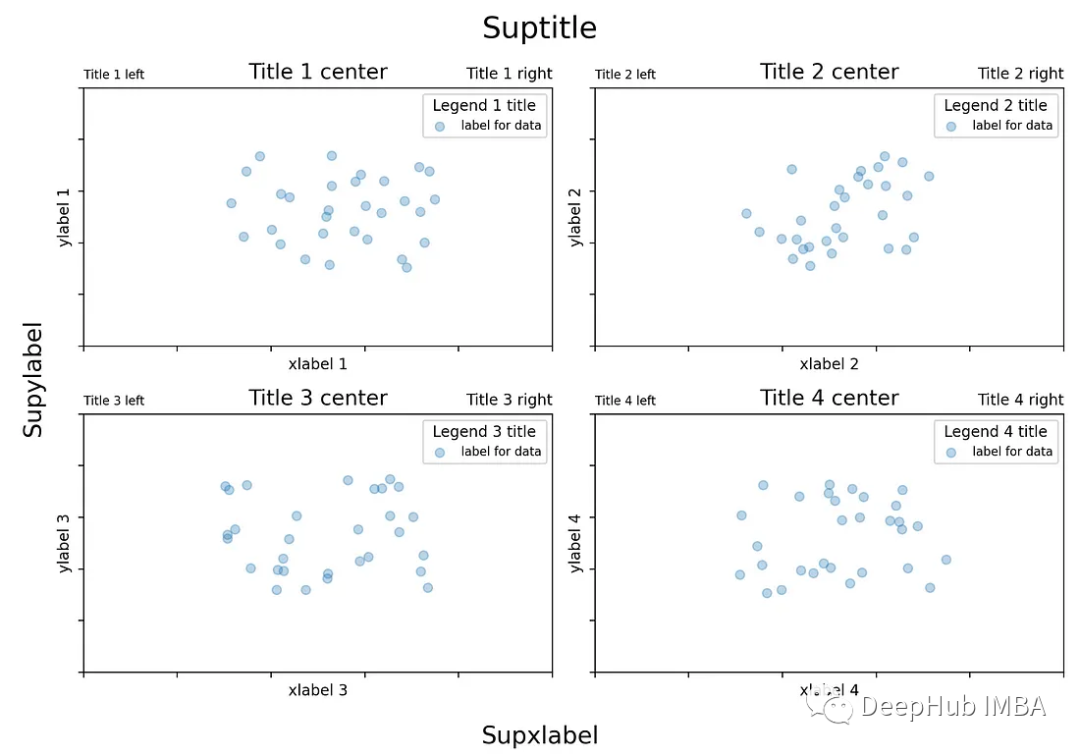
Matplotlib中的titles(标题)、labels(标签)和legends(图例)
本文讨论Python的Matplotlib绘图库中可用的不同标记选项。
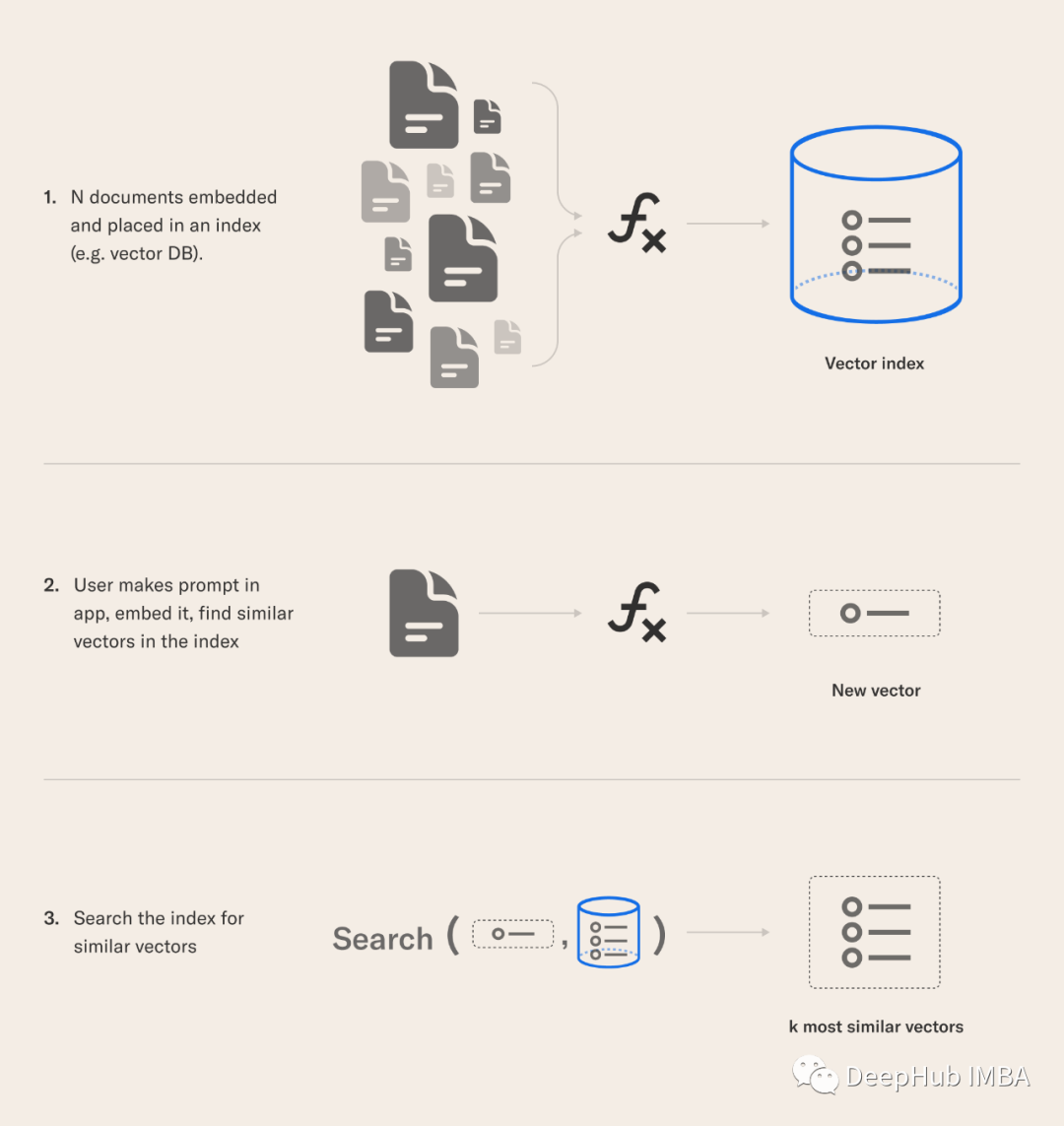
RAG应用程序的12种调优策略:使用“超参数”和策略优化来提高检索性能
本文从数据科学家的角度来研究检索增强生成(retrieve - augmented Generation, RAG)管道。讨论潜在的“超参数”,这些参数都可以通过实验来提高RAG管道的性能。
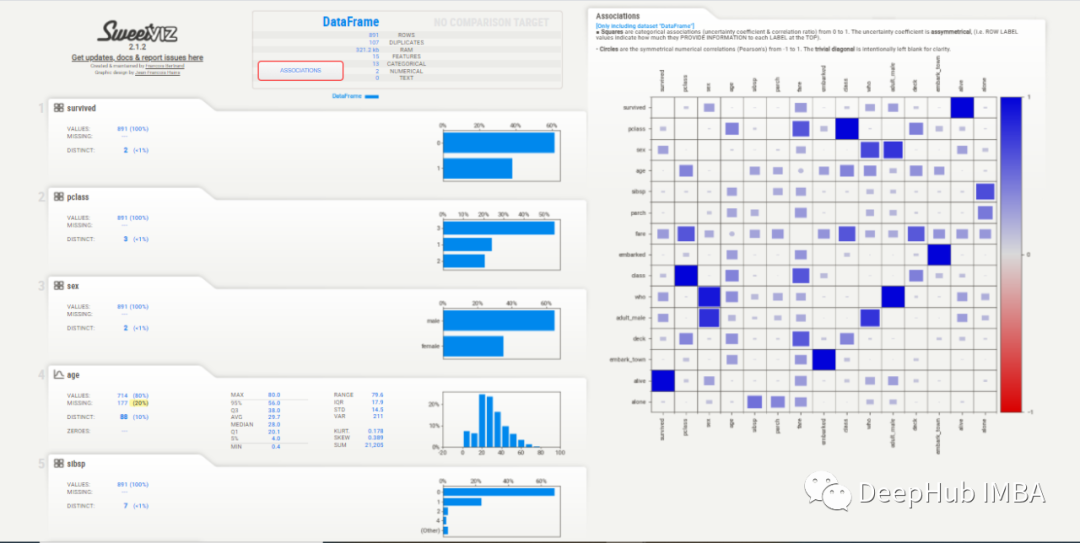
2023年5个自动化EDA库推荐
EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。
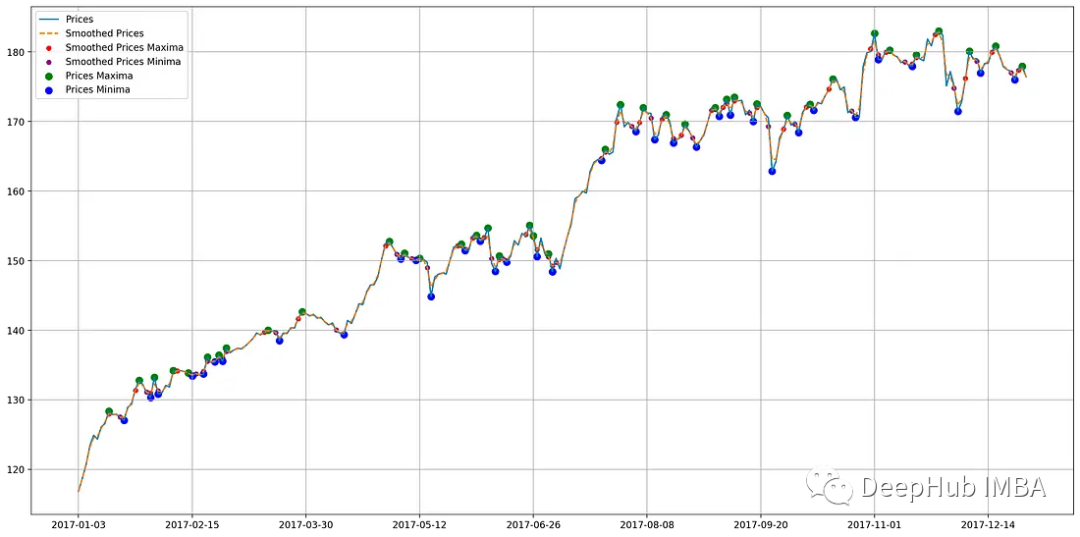
使用Python代码识别股票价格图表模式
在股票市场交易的动态环境中,技术和金融的融合催生了分析市场趋势和预测未来价格走势的先进方法。本文将使用Python进行股票模式识别。
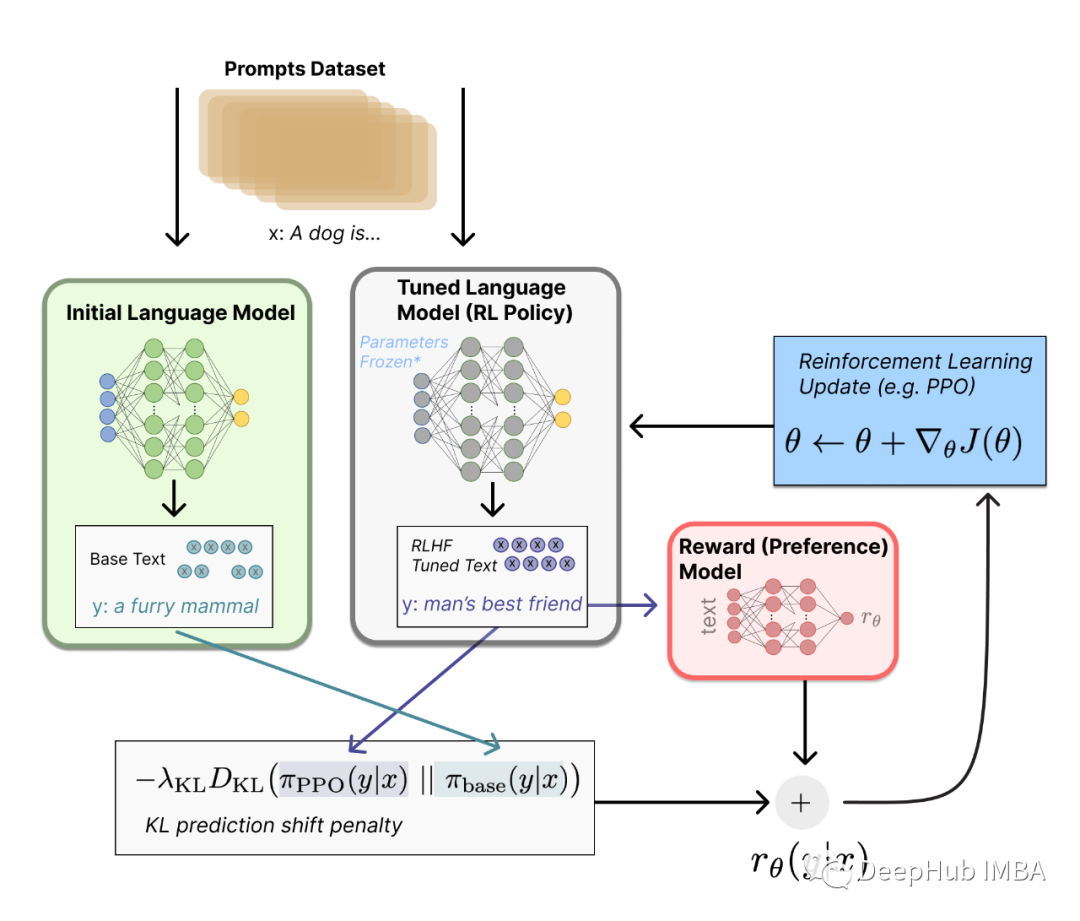
使用Huggingface创建大语言模型RLHF训练流程的完整教程
在本文中,我们将使用Huggingface来进行完整的RLHF训练。

11月推荐阅读的12篇大语言模型相关论文
现在已经是12月了,距离2024年只有一个月了,本文总结了11月的一些比较不错的大语言模型相关论文

4个解决特定的任务的Pandas高效代码
在本文中,我将分享4个在一行代码中完成的Pandas操作。这些操作可以有效地解决特定的任务,并以一种好的方式给出结果。
高斯混合模型:GMM和期望最大化算法的理论和代码实现
高斯混合模型(gmm)是将数据表示为高斯(正态)分布的混合的统计模型。这些模型可用于识别数据集中的组,并捕获数据分布的复杂、多模态结构。
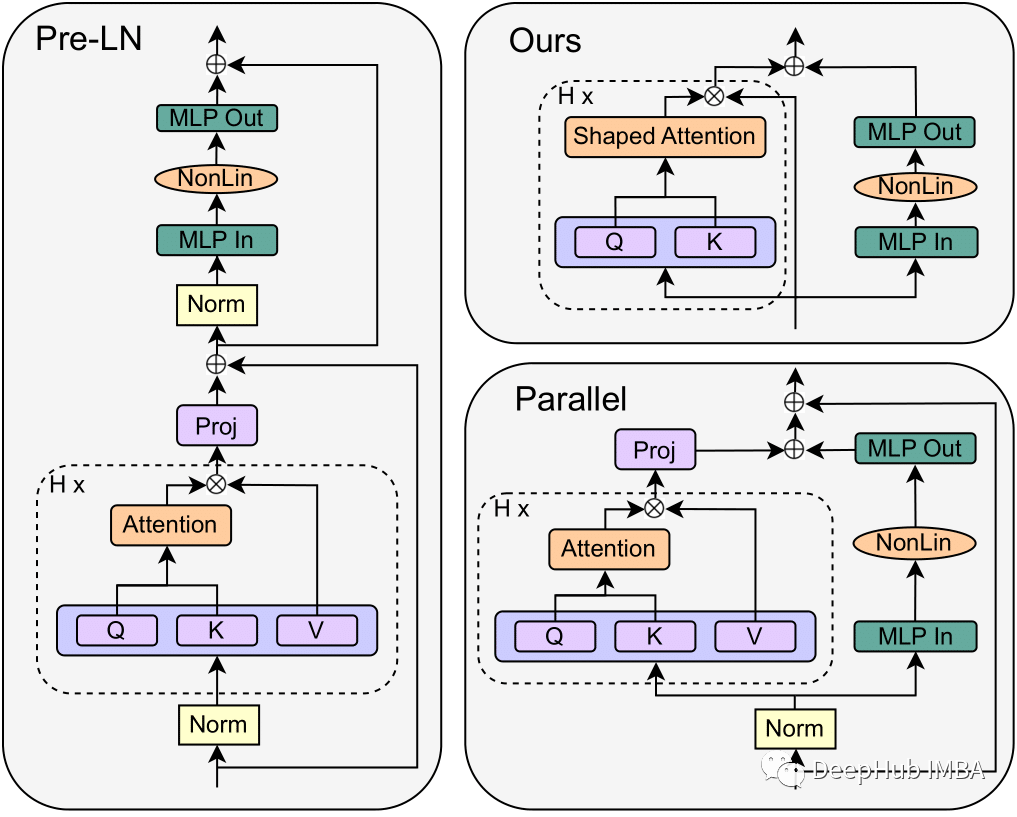
简化版Transformer :Simplifying Transformer Block论文详解
在这篇文章中我将深入探讨来自苏黎世联邦理工学院计算机科学系的Bobby He和Thomas Hofmann在他们的论文“Simplifying Transformer Blocks”中介绍的Transformer技术的进化步骤。这是自Transformer 开始以来,我看到的最好的改进。
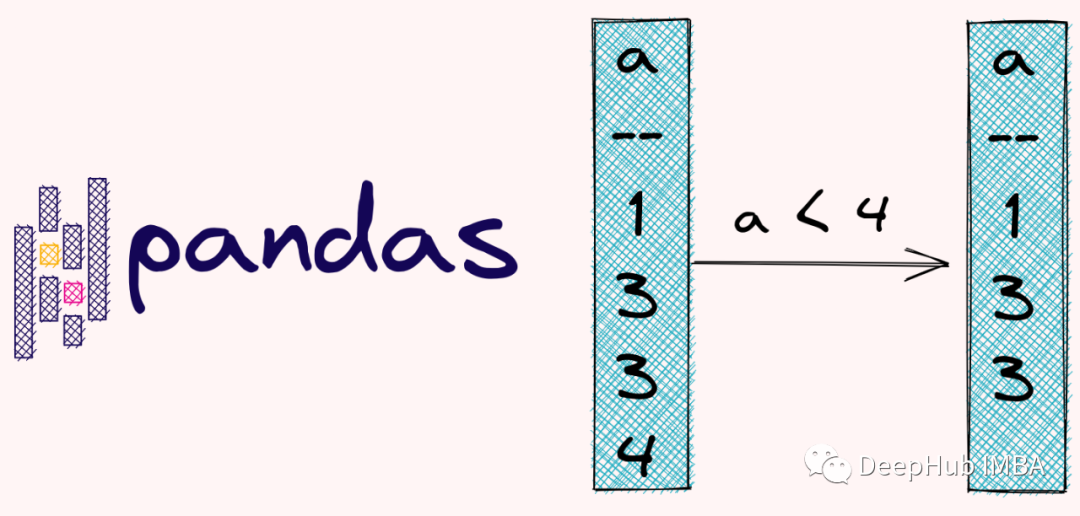
Pandas中选择和过滤数据的终极指南
本文将介绍使用pandas进行数据选择和过滤的基本技术和函数。无论是需要提取特定的行或列,还是需要应用条件过滤,pandas都可以满足需求。

使用Accelerate库在多GPU上进行LLM推理
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
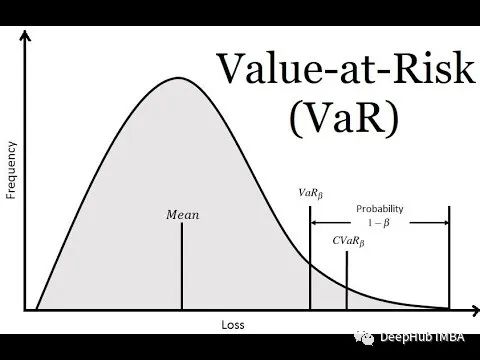
三种常用的风险价值(VaR)计算方法总结
风险价值(VaR)是金融领域广泛使用的风险度量,它量化了在特定时间范围内和给定置信度水平下投资或投资组合的潜在损失。
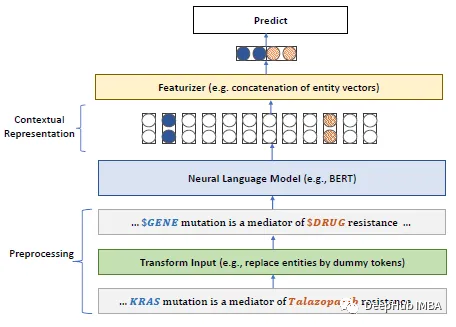
PubMedBERT:生物医学自然语言处理领域的特定预训练模型
语言模型并不一定就是最优的解决方案,“小”模型也有一定的用武之地
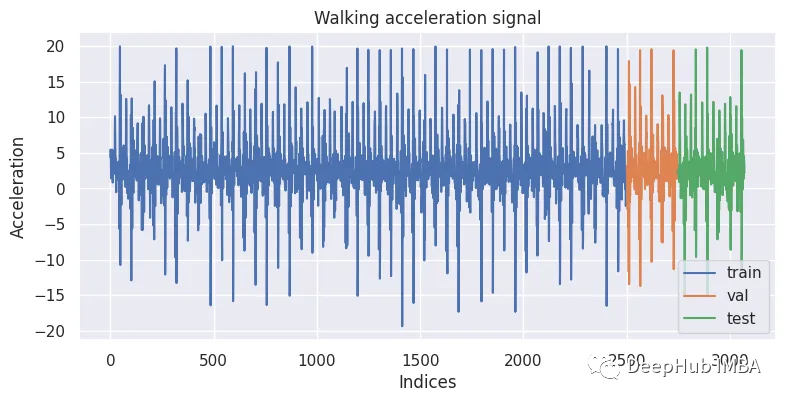
使用skforecast进行时间序列预测
在本文中,将介绍skforecast并演示了如何使用它在时间序列数据上生成预测。skforecast库的一个有价值的特性是它能够使用没有日期时间索引的数据进行训练和预测。
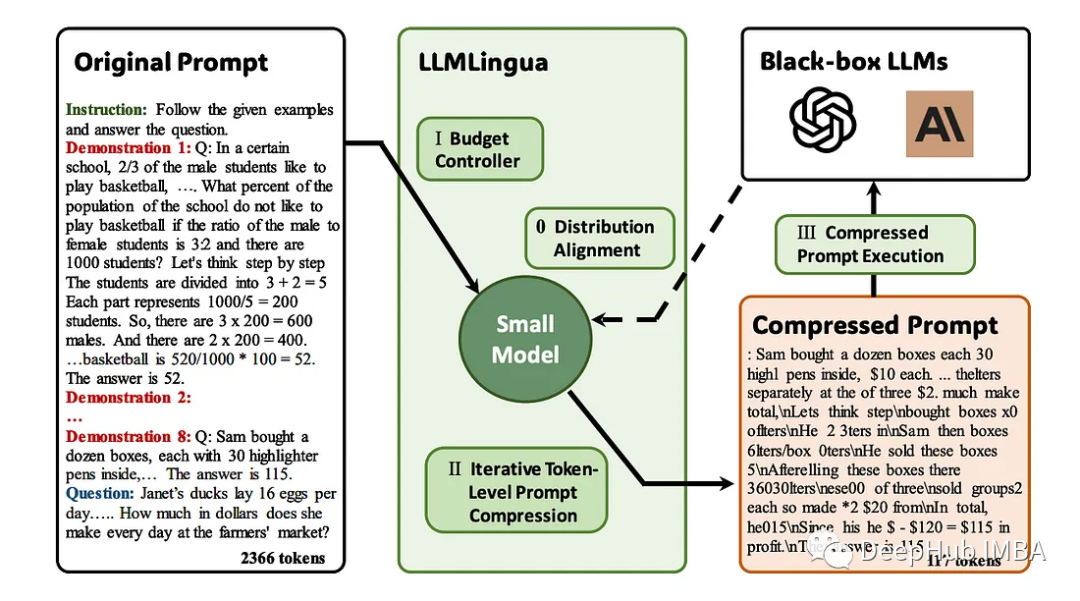
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。
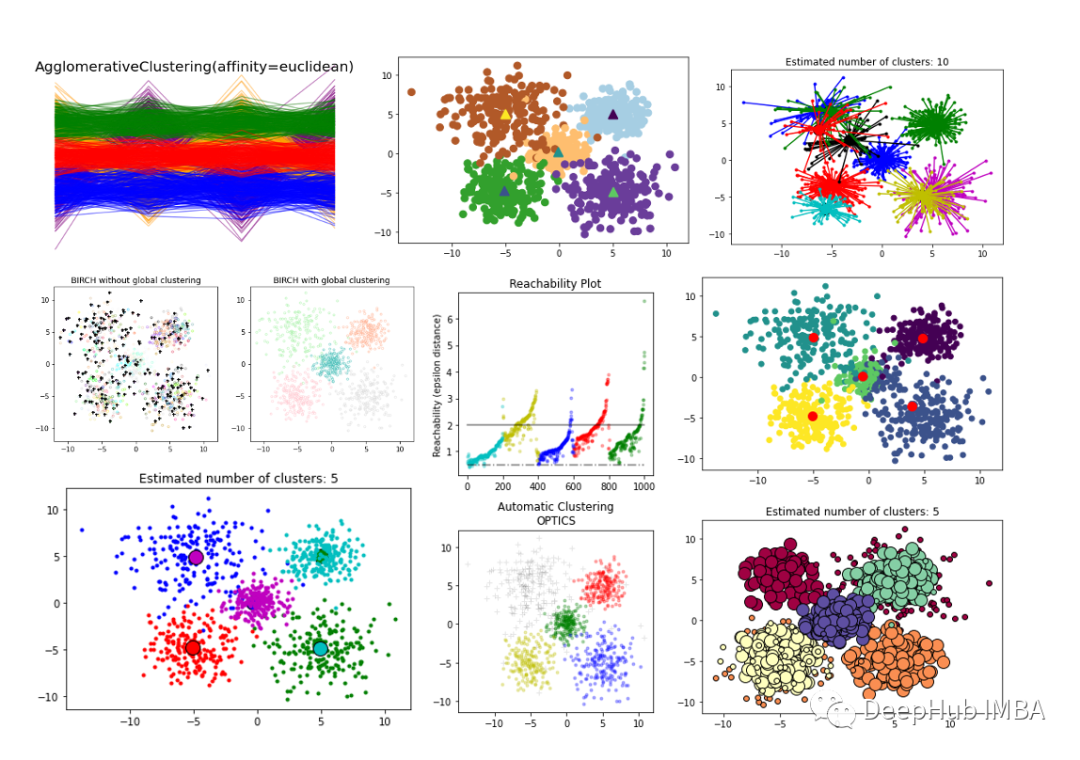
6个常用的聚类评价指标
评估聚类结果的有效性,即聚类评估或验证,对于聚类应用程序的成功至关重要。
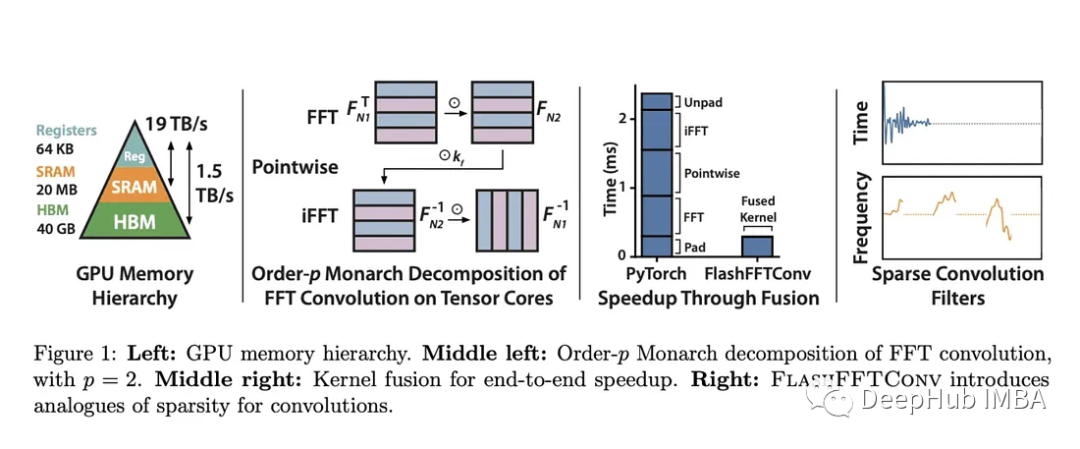
斯坦福大学引入FlashFFTConv来优化机器学习中长序列的FFT卷积
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质量和效率。