
Python 3.11 pre-release已经发布。更新日志中提到:
Python 3.11 is up to 10–60% faster than Python 3.10. On average, we measured a 1.25x speedup on the standard benchmark suite. See Faster CPython for details. — Python 3.11 Changelog.
Python 在生产系统上的速度一直是被新手对比和吐槽。,因为真的并不块,为了解决性能问题,我们总是需要使用 Cython 或 Tuplex 转换关键代码。
Python 3.11中特意强了这个优化,我们可以实际验证下到底有没有官方说的平均1.25倍的提升呢?
作为数据科学来说,我更期待的是看看它在 Pandas 处理DF方面是否有任何改进。
首先,让我们尝试一些斐波那契数列。
安装Python 3.11 pre-release
windows的话可以在官方下载安装文件,ubuntu可以用apt命令进行安装
sudo apt install Python3.11
我们在工作中还不能直接使用3.11。所以需要创建单独的虚拟环境来保存两个 Python 版本。
$ virtualenv env10 --python=3.10
$ virtualenv env11 --python=3.11
# To activate v11 you can run,
$ source env11/bin/activate
Python 3.11 与 Python 3.10 相比有多快?
我创建了一个小函数来生成一些斐波那契数。
def fib(n: int) -> int:
return n if n < 2 else fib(n - 1) + fib(n - 2)
用 Timeit 运行上面的斐波那契数生成器来确定执行时间。以下命令将重复生成过程十次并显示最佳执行时间。
# To generate the (n)th Fibonacci number
python -m timeit -n 10 "from fib import fib;fib(n)"
以下是 Python 3.10 和 Python 3.11 上的结果
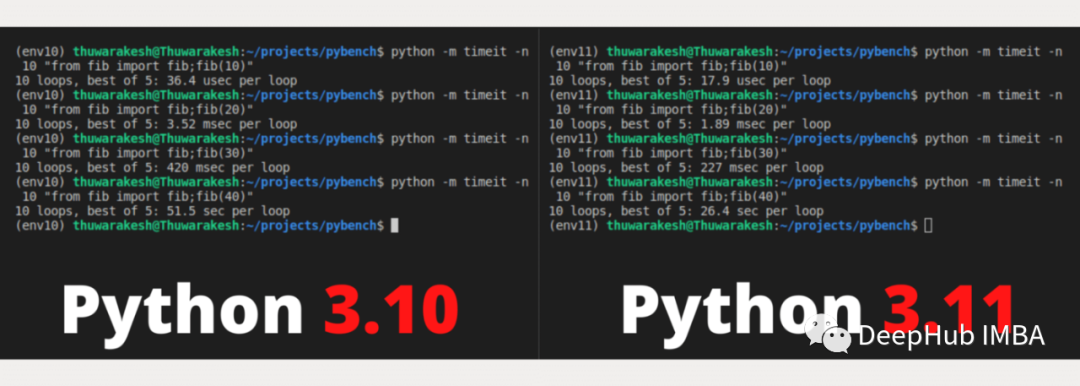
Python 3.11 在每次运行中都优于 Python 3.10。执行时间大约是 3.11 版本的一半。
我其实是想确认它在 Pandas 任务上的表现。但不幸的是,到目前为止Numpy 和 Pandas 还没有支持 Python 3.11 的版本。
冒泡排序
由于无法对 Pandas 进行基准测试,因此我们试试一般常见的计算时的性能对比,测量对一百万个数字进行排序所花费的时间。排序是日常使用的最多也是最常用的一个操作了,相信它的结果可以为我们提供一个很好的参考。
import random
from timeit import timeit
from typing import List
def bubble_sort(items: List[int]) -> List[int]:
n = len(items)
for i in range(n - 1):
for j in range(0, n - i - 1):
if items[j] > items[j + 1]:
items[j], items[j + 1] = items[j + 1], items[j]
numbers = [random.randint(1, 10000) for i in range(1000000)]
print(timeit(lambda:bubble_sort(numbers),number=5))
上面的代码生成了一百万个随机数。timeit 函数被设置为仅测量冒泡排序函数执行的持续时间。
结果如下

Python 3.11 只用了 21 秒来排序,而 3.10 对应的用时 39 秒。
I/O 操作是否存在性能差异?
这两个版本在磁盘上读写信息的速度有差异吗。在pandas读取df还有深度学习读取数据时 I/O 性能至关重要。
这里准备了2个程序 第一个将一百万个文件写入磁盘。
from timeit import timeit
statement = """
for i in range(100000):
with open(f"./data/a{i}.txt", "w") as f:
f.write('a')
"""
print(timeit(statement, number=10))
我们使用 timeit 函数来打印持续时间。可以多次重复该任务并通过设置 number 参数取平均值。
第二个程序也使用 timeit 函数。但它只读取一百万个文件。
from glob import glob
from timeit import timeit
file_paths = glob("./data/*.txt")
statement = f"""
for path in {file_paths}:
with open(path, "r") as f:
f.read()
"""
print(timeit(statement, number=10))
下面是我们运行两个版本的输出。

虽然看起来 Python 3.10 比 Python 3.11 有优势,但并不重要。因为多次运行这个实验会得出不同的结论,但是能够肯定的是I/O方面并没有提升。
总结
Python 3.11 仍然是一个预发布版本。3但它似乎是 Python 历史上一个了不起的版本。它比之前的版本快了 60%,这个判断还是没毛病的,我们上面的一些实验也证明了 Python 3.11 确实更快。
译者注:前几天刚把以前项目升级到了3.6,新项目都使用3.9开发了,现在3.11又马上要发布了,而且还说性能有大幅提升,龟叔你这是要闹哪样😂
作者:Thuwarakesh Murallie