
Pycaret是Python中的一个开源可自动化机器学习工作流程的低代码机学习库。它是一种端到端的机器学习和模型管理工具。要了解有关Pycaret的更多信息,可以查看官方网站或GitHub。
1、与最新版本的Scikit-Learn完全兼容
Pycaret 2.x需要Scikit-Learn 0.23.2,如果您想在同一Python环境中使用Scikit-Learn和Pycaret的最新版本是不可能的,但是 Pycaret 3.0将与Scikit-Learn的最新版本完全兼容。
2、面向对象的API
PyCaret很棒,但缺乏面向对象的思想。通过加入类和对象,PyCaret改变了从1.0开始的工作方式,
# Functional API (Existing)
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup
from pycaret.classification import *
s = setup(data, target = 'Purchase', session_id = 123)
# compare models
best = compare_models()
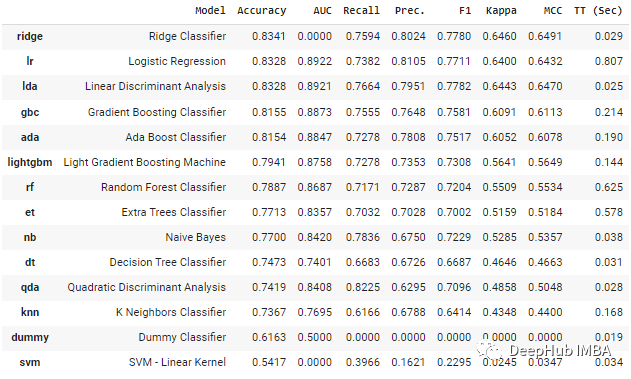
这很方便,但如果现在你想在同一个notebook上运行不同参数的多个实验,你可能就会遇到参数被覆盖的问题,并且因为是变量的形式,这些参数被覆盖了你也很难发现他们。现在有了新的面向对象的API,参数保存在对象中,不会产生多余的变量,简化了操作。
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup 1
from pycaret.classification import ClassificationExperiment
exp1 = ClassificationExperiment()
exp1.setup(data, target = 'Purchase', session_id = 123)
# compare models init 1
best = exp1.compare_models()
# init setup 2
exp2 = ClassificationExperiment()
exp2.setup(data, target = 'Purchase', normalize = True, session_id = 123)
# compare models init 2
best2 = exp2.compare_models()
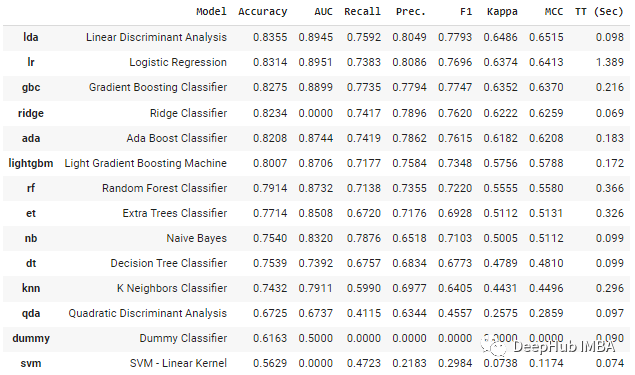
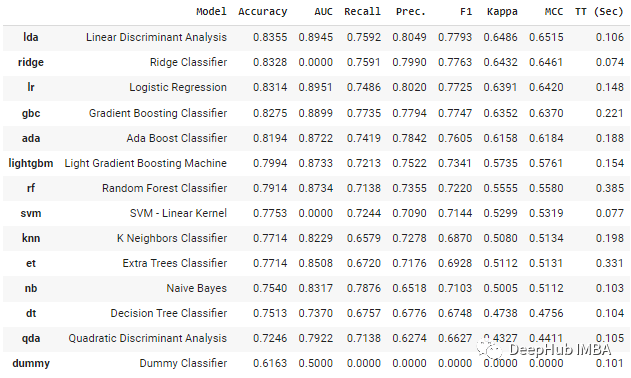
你还可以使用get_leaderboard函数为每个实验生成结果列表,然后进行比较。
# generate leaderboard
leaderboard_exp1 = exp1.get_leaderboard()
leaderboard_exp2 = exp2.get_leaderboard()
lb = pd.concat([leaderboard_exp1, leaderboard_exp2])
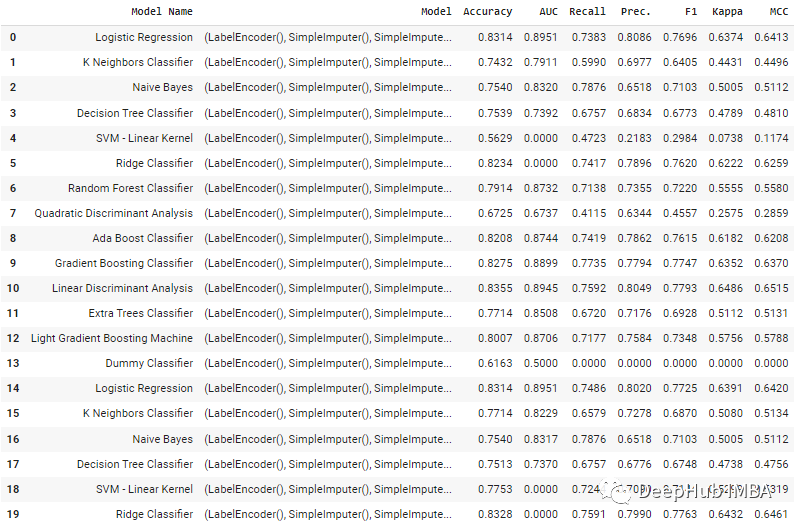
# print pipeline steps
print(exp1.pipeline.steps)
print(exp21.pipeline.steps)

还可以根据需要在函数式API和面向对象API之间进行切换。
# set current experiment to exp1
from pycaret.classificatiom import set_current_experiment
set_current_experiment(exp1)
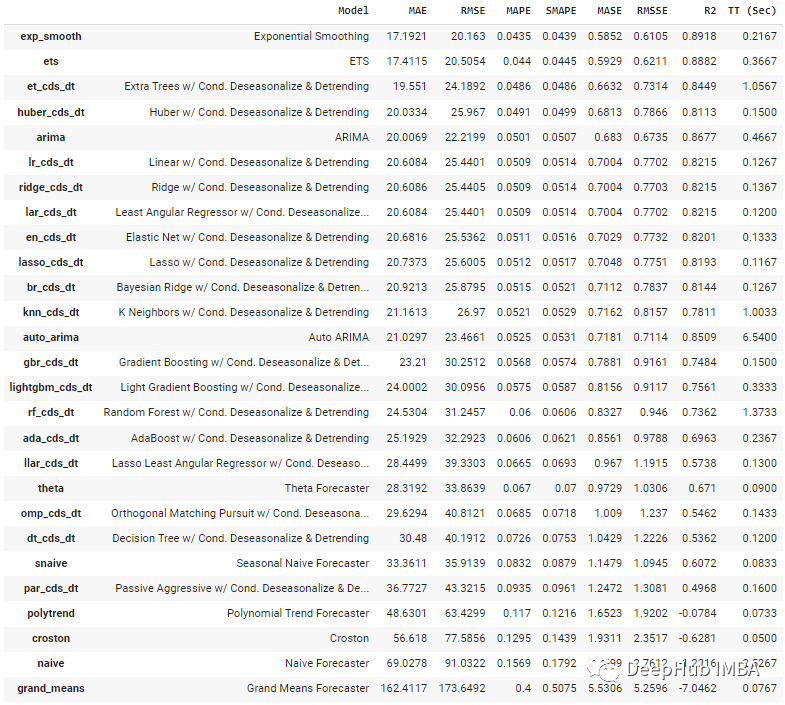
3、时间序列模块
很长一段时间以来,PyCaret的时间序列模块一直是一个单独的PyPI库(PyCaret-ts-alpha)。现在PyCaret 3.0终于将他们整合在一起。
# load dataset
from pycaret.datasets import get_data
data = get_data('airline')
# init setup
from pycaret.time_series import *
s = setup(data, fh = 12, session_id = 123)
# compare models
best = compare_models()
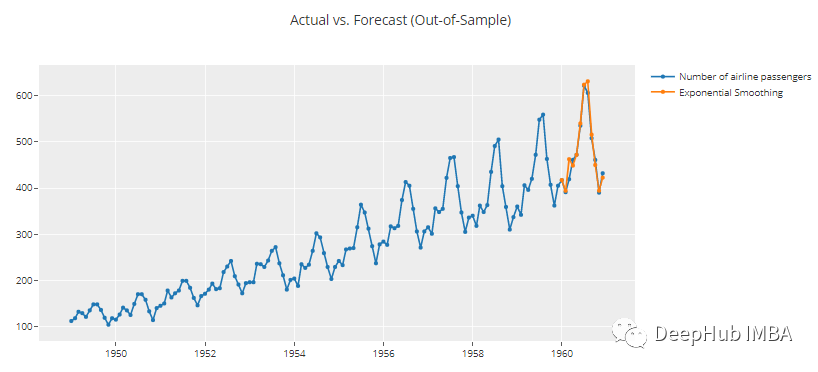
# forecast plot
plot_model(best, plot = 'forecast')
4、管道流水线的改进
预处理模块为了与scikit-learn最新版本完全兼容并提高效率和性能,已经完全进行了重写。在Pycaret 3.0中引入了几种新的预处理函数不同类型的分类编码。 在2.x之前只有One-Hot-Encoding编码。
下面比较了使用相同random_state的各种模型的表现
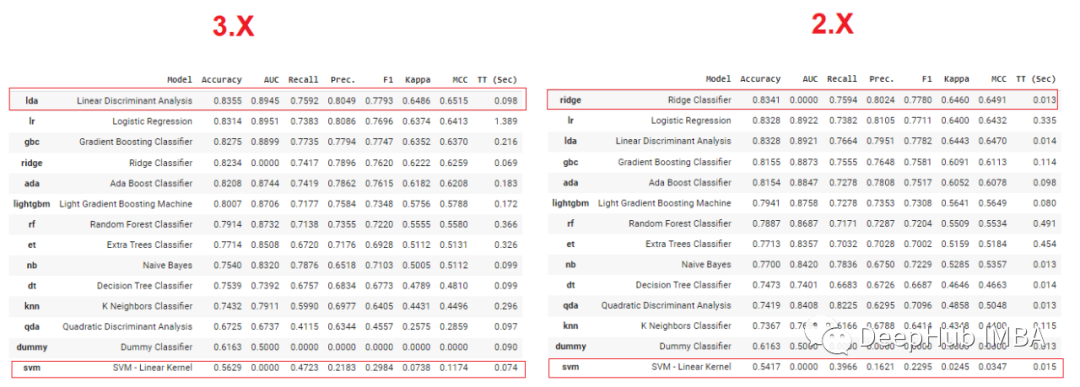
3.0中可用的一些新功能是:
- 新的分类编码技术
- 可以处理文本建模
- 加入了检测异常值的新技术
- 加入了特征选择的新技术
- 保证避免目标泄漏
4、模块化和轻量化
Pycaret 3.0进行了模块化的重构并减少了依赖, 相比于2.x 减少了33%依赖项,并且在安装的时间方面有了很大的缩减。此外还可以单独安装不同的模块,例如Pycaret [NLP]将安装与NLP相关的依赖关系。
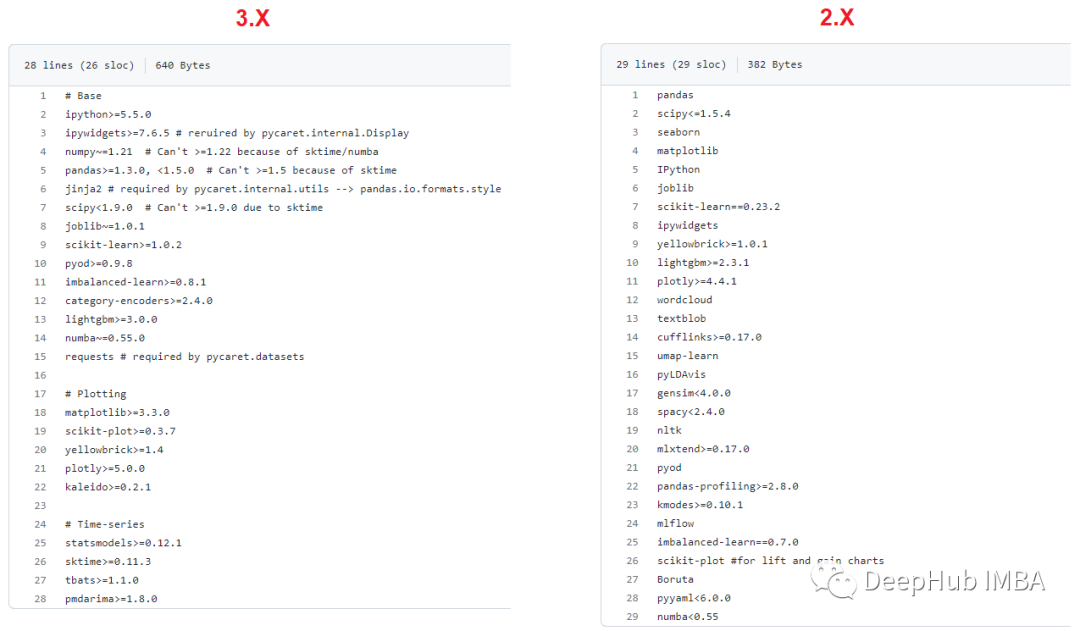
5、自动数据类型处理
Pycaret 3.0不需要对数据类型进行确认,因为它能够自动的处理。但是仍然可以使用numeric_features和centorical_features参数覆盖数据类型。
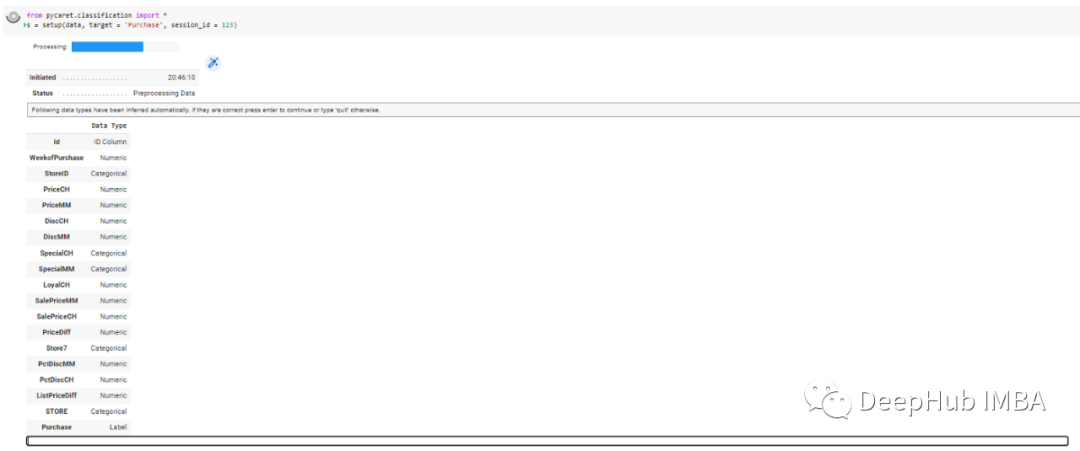
6、文本特征工程
PyCaret 3.0将能够处理文本输入。如果数据集中有一个文本列,设置中有两个新参数,可以从文本中提取特征用于模型训练。

作者:Moez Ali