
为什么要增加训练数据
机器学习中的数据增强主要通过人工构建数据,增加训练集的大小使模型达到更好的泛化特性。这是一个在机器学习学科中进行的广泛研究的研究领域。
数据增强的主要作用如下:
- 增加了模型的概括功能;
- 对于不平衡数据集很有用;
- 可以最大程度地减少标注工作;
- 提高了针对对抗性攻击的健壮性;
一般情况下文本分类中的数据增强会产生更好的模型,因为模型在训练过程中会看到更多的语言模式。但是现在这种数据增强的工作是通过在大型预训练语言模型上的迁移学习来管理的,因为这些模型对于我们使用的各种转换已经不敏感了。事实上,数据增强方法只有在创造出以前从未见过的新的语言模式时才会有益。
文本分类中数据增强方法的分类
本文整理了用于文本分类的数据增强方法,来自论文《 A Survey on Data Augmentation for Text Classification》。一般情况下我们都会结合几种数据增强方法来实现更多样化的实例。
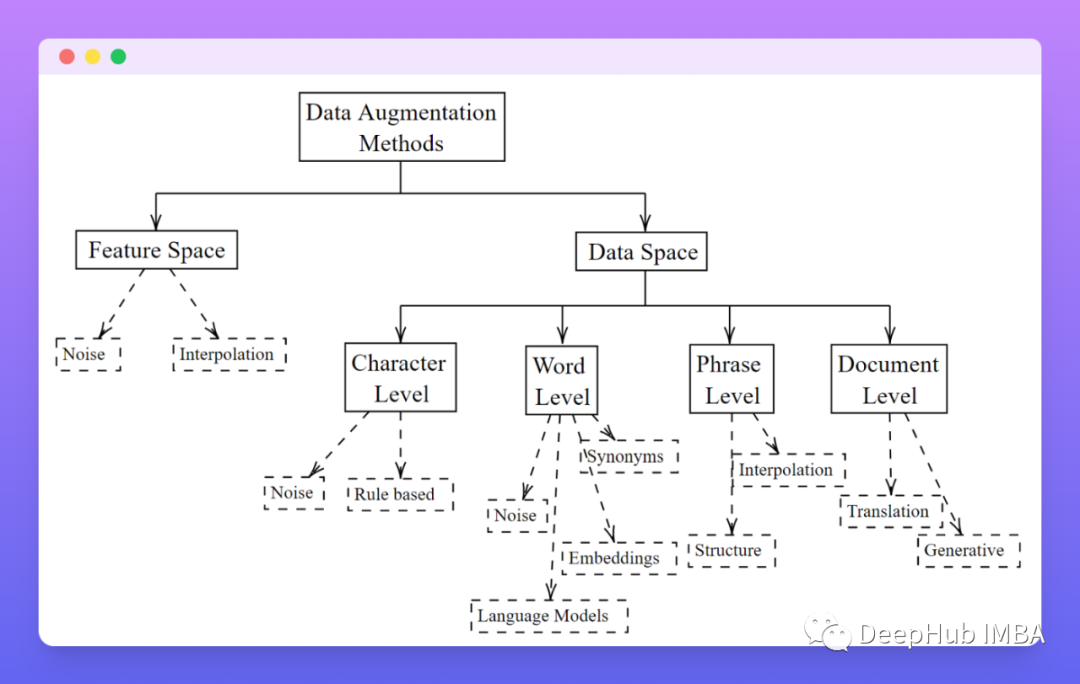
一般情况下文本有四种类型的数据增强:字符级、单词级、短语和句子级、文档级。
字符级
这种类型的数据增强处理通过改变现有的训练样本单个字符创建新的训练样本。主要包括:随机字符删除、交换和插入。和基于规则的转换,比如通过使用正则表达式(比如插入拼写错误、数据更改、实体名称和缩写)实现有效的转换。
单词级
这种类型的数据增增强一般会改变单个训练样本的单词。
- 添加噪声:使用“ Unigram Noising”,输入数据中的单词在一定概率下被另一个单词替换。或通过“空白噪声”的方法,单词被“ _”取代。其他噪声的技术是随机单词交换和删除。
- 同义词替代:这种是非常流行的形式。同义词替代通常是使用WordNet等现有的知识库来进行。
- 嵌入替代:与同义词替代类似,嵌入替换方法通过搜索的方法找到适合上下文的单词。为了实现这一目标,单词被投影到一个潜在的表示空间中,在该空间中相似上下文的单词更加紧密,然后用一个在该空间中接近的单词进行替换。
- 语言模型替代:语言模型根据之前或周围的上下文预测后面或缺失的单词,模型可以用来过滤不合适的词。与考虑全局上下文的单词嵌入嵌入替换相比,语言模型支持更本地化的替换。
短语和句子级
这种类型的数据增强处理通过改变句子结构创建新的训练样本。
- 基于结构的数据扩充方法可以利用某些结构化特性或组件来生成修改过的文本。这种结构化可以基于语法形式,例如依赖语法或POS-TAG。比如说一些句子可以通过把重点放在主语和宾语上来裁剪某些句子。
- 内插方法通过替换具有相同标签的训练示例的子结构来工作。例如,一个实例中的句子子结构“a [DT] cake [NN]”(其中[DT]和[NN]为英语词性标签,分别为限定词和单数名词)可以替换为另一个实例的新句子子结构“a [DT] dog [NN]”。
文档级
这种类型的数据增强通过更改文档中的整个句子来创建的新训练样本。
往返翻译:往返翻译将 单词,短语,句子或文档被翻译成另一种语言(正向翻译),然后转换回源语言(反向翻译)。
相似生成:随着语言生成能力的显著提高,当前的模型能够通过合并的信息创建非常多样化的文本,文档级数据增强的生成方法包括训练语言模型(VAEs、rnn、transformer),可以生成与训练数据中相似的文档。
特征空间中的数据增强
特征空间中的数据增强处理的是将输入数据以其特征形式转换为输入的潜在向量表示。在特征空间中有两种类型的数据增强:
噪声:与数据一样,也可以在特征空间中引入噪声。例如,可以将随机噪声预特征表示进行乘和加的操作。
插值:将两句话的隐藏状态进行插值生成一个新的句子,包含原句和原句的意思。
总结
本文概述了适合文本领域的数据增强方法。数据增强有助于实现许多目标,包括正规化、最小化标签工作量、降低对真实数据的使用(尤其是在隐私敏感领域)、平衡不平衡的数据集,以及增加对抗攻击的健壮性。
除了将数据增广应用到数据以外,还可以将其应用到特征空间。最后如果你想查看 A Survey on Data Augmentation for Text Classification这篇论文,可以看以下的连接
https://arxiv.org/pdf/2107.03158.pdf
作者:Fabio Chiusano