
Deephub
更多文章请关注公众号:Deephub-IMBA

Jupyter Notebook的10个常用扩展介绍
在本文中,我们将探索Jupyter Notebook提升我们数据科学经验的强大扩展组件。
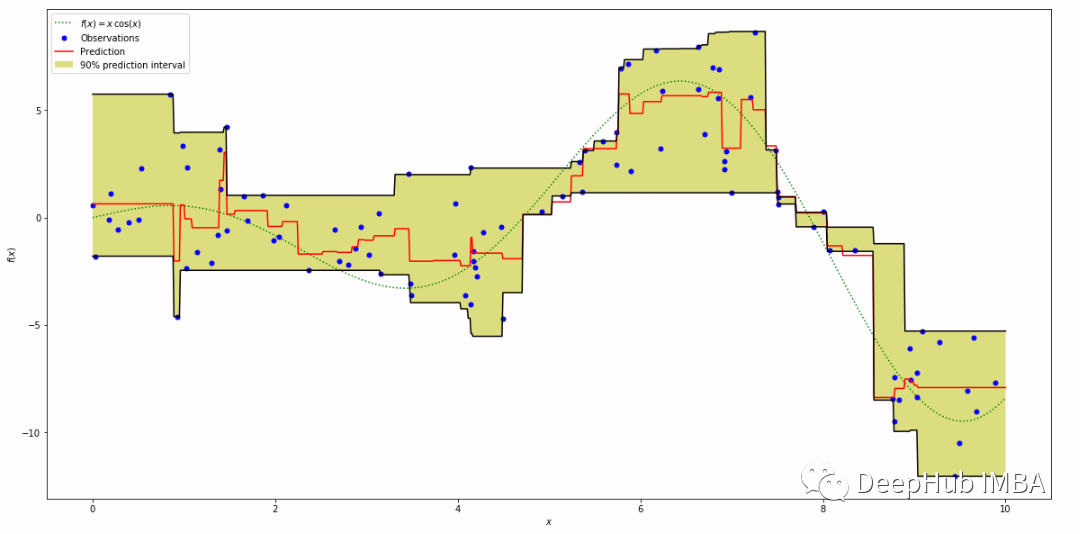
神经网络中的分位数回归和分位数损失
在分位数回归中,我们不仅关注预测的中心趋势(如均值),还关注在分布的不同分位数处的预测准确性。Quantile loss允许我们根据所关注的分位数来量化预测的不确定性。

使用LOTR合并检索提高RAG性能
RAG结合了两个关键元素:检索和生成。本文将介绍使用使用Merge retriver改进RAG的性能
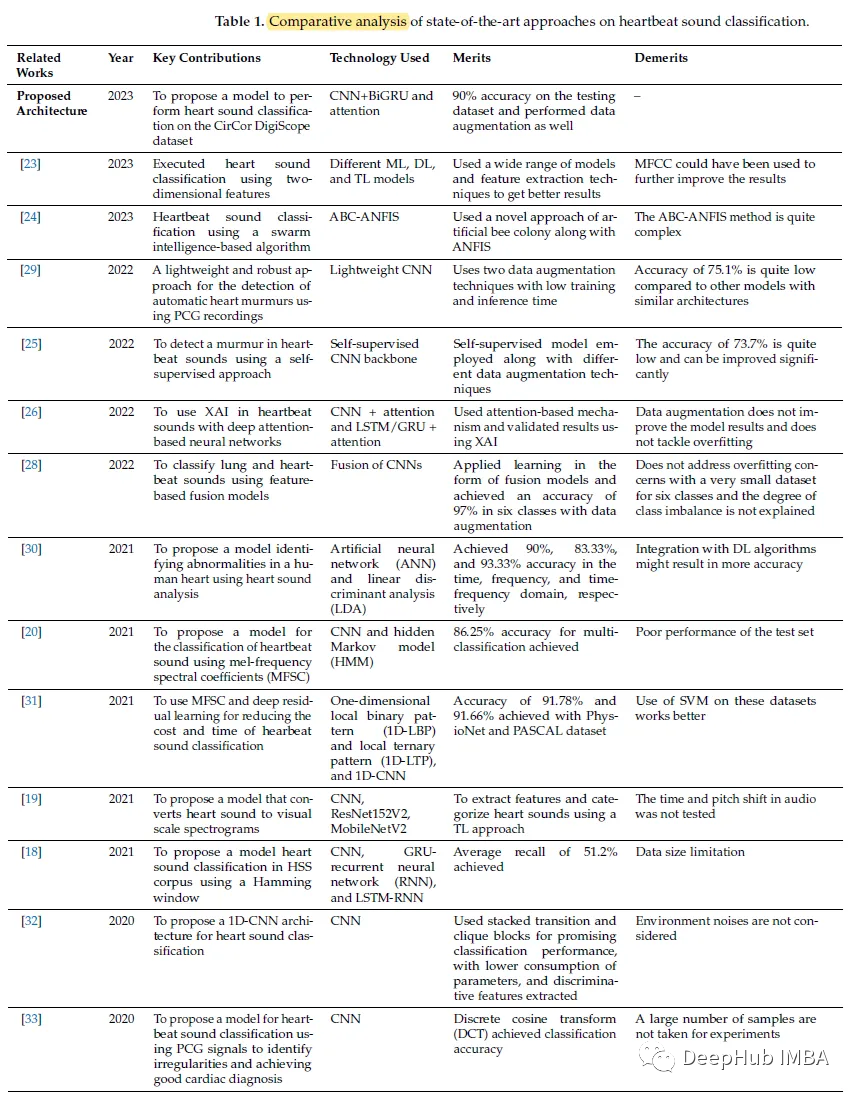
基于CNN和双向gru的心跳分类系统
论文,提出了基于卷积神经网络和双向门控循环单元(CNN + BiGRU)注意力的心跳声分类,论文不仅显示了模型还构建了完整的系统。

人工智能生成文本检测在实践中使用有效性探讨
本文介绍了关于如何检测ai生成文本的思路。希望这有助于理解检测人工智能生成文本背后的细节。

一文读懂分类模型评估指标
模型评估是深度学习和机器学习中非常重要的一部分,用于衡量模型的性能和效果。本文将逐步分解混淆矩阵,准确性,精度,召回率和F1分数。
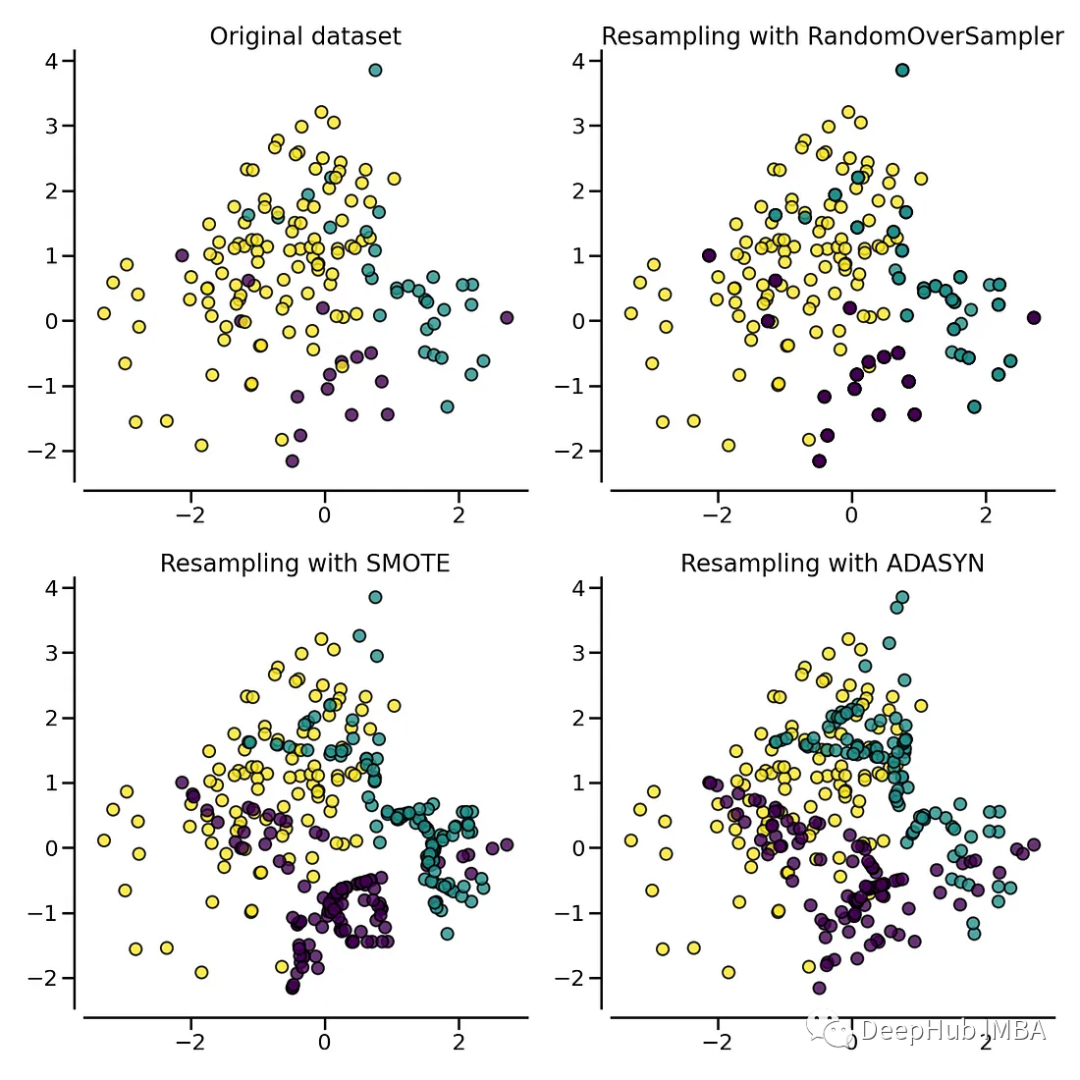
处理不平衡数据的过采样技术对比总结
在不平衡数据上训练的分类算法往往导致预测质量差。过采样提供了一种在模型训练开始之前重新平衡类的方法。
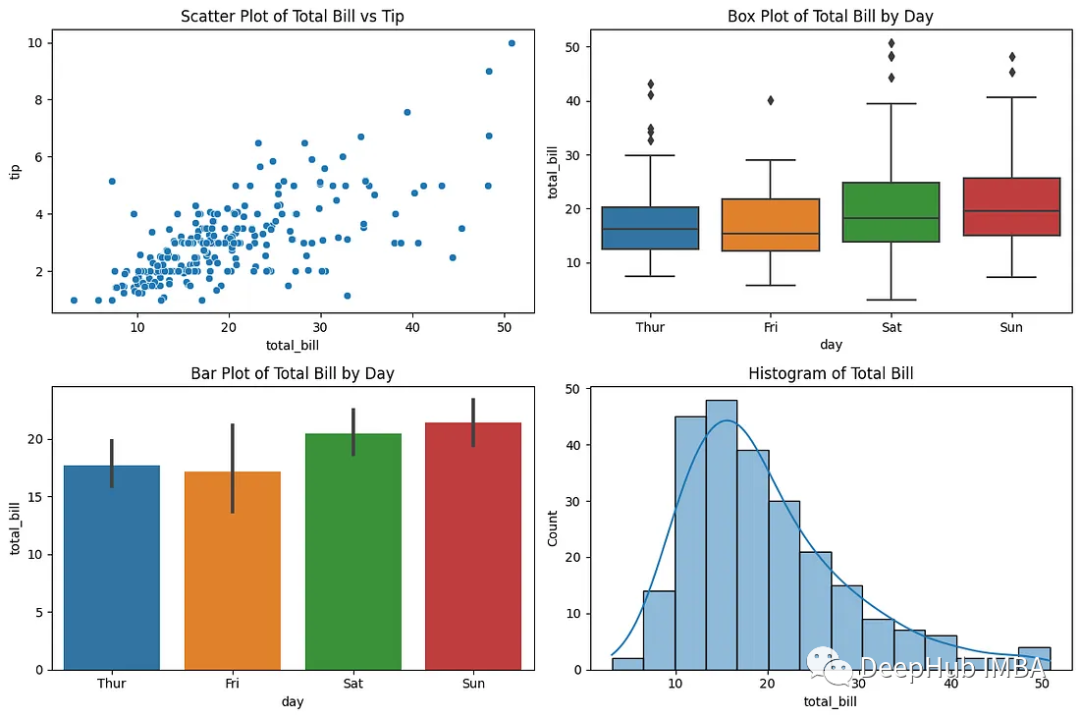
EDA中常用的9个可视化图表介绍和代码示例
在这篇文章中我们介绍EDA中常用的9个图表,并且针对每个图表给出代码示例。

2023年小型计算机视觉总结
到2023年底,人工智能领域迎来了生成式人工智能的新成功:大型语言模型(llm)和图像生成模型。每个人都在谈论它,它们对小型计算机视觉应用有什么改变吗?
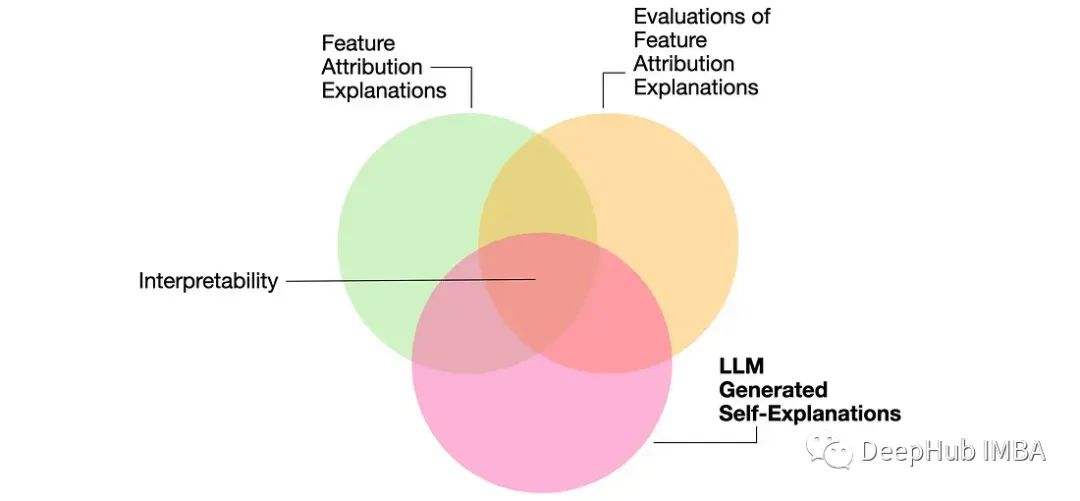
论文推荐:大型语言模型能自我解释吗?
这篇论文的研究主要贡献是对LLM生成解释的优缺点进行了调查。详细介绍了两种方法,一种是做出预测,然后解释它,另一种是产生解释,然后用它来做出预测。
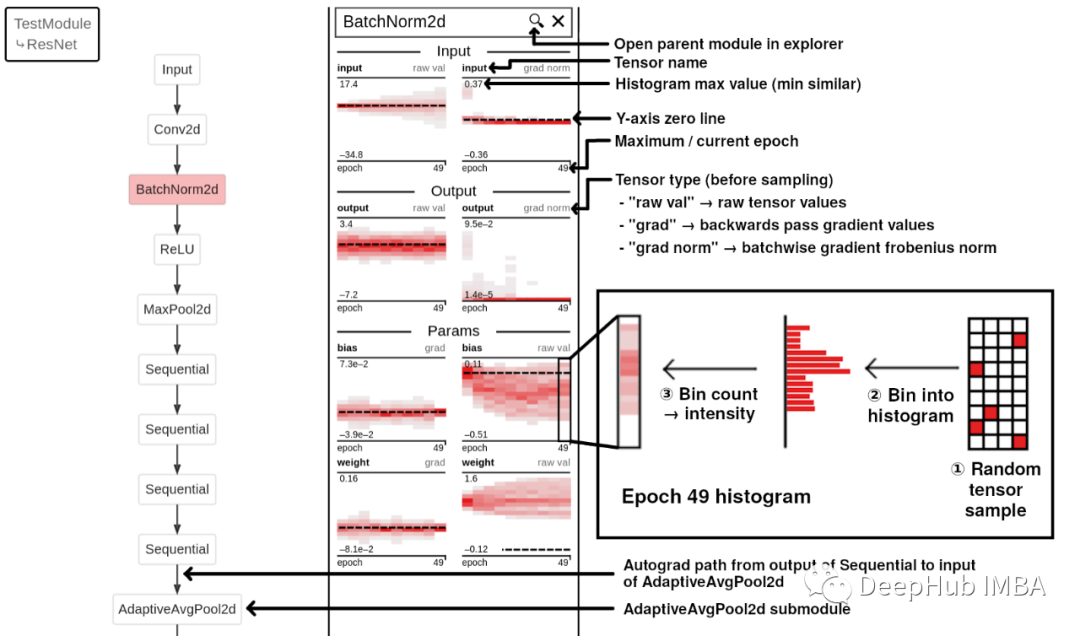
神经网络可视化新工具:TorchExplorer
TorchExplorer是一个交互式探索神经网络的可视化工具

MLX vs MPS vs CUDA:苹果新机器学习框架的基准测试
如果你是一个Mac用户和一个深度学习爱好者,你可能希望在某些时候Mac可以处理一些重型模型。苹果刚刚发布了MLX,一个在苹果芯片上高效运行机器学习模型的框架。
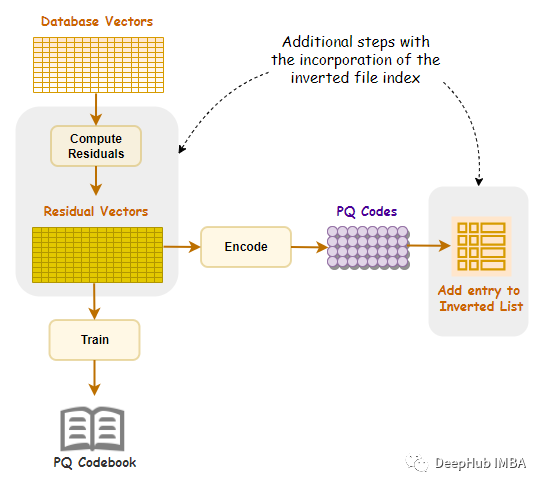
高维向量压缩方法IVFPQ :通过创建索引加速矢量搜索
IVFPQ 是一种用于数据检索的索引方法,它结合了倒排索引(Inverted File)和乘积量化(Product Quantization)的技术。
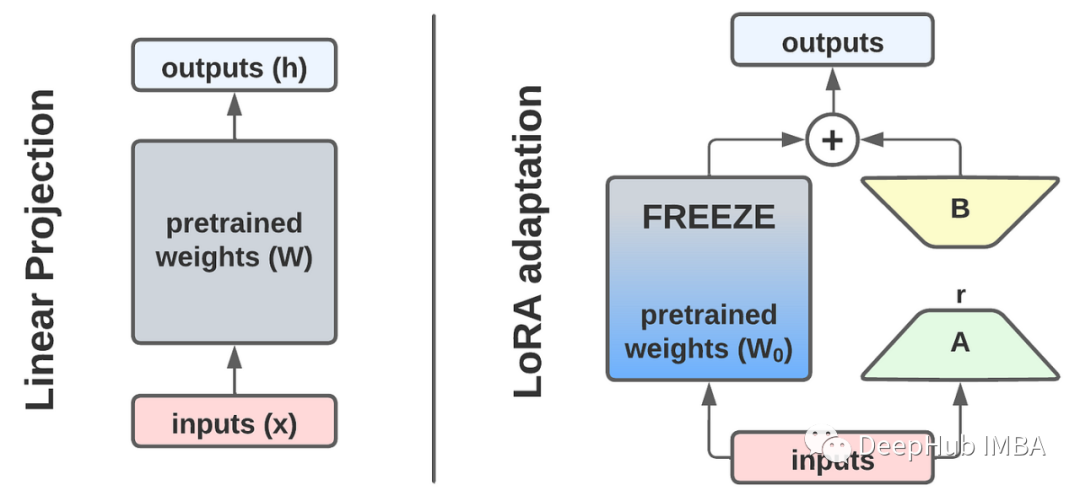
从头开始实现LoRA以及一些实用技巧
本文将首先深入研究LoRA,然后以RoBERTa模型例从头开发一个LoRA,然后使用GLUE和SQuAD基准测试对实现进行基准测试,并讨论一些技巧和改进。

2023年12月 论文推荐
12月已经过了一半了,还有2周就是2024年了,我们来推荐下这两周我发现的一些好的论文,另外再推荐2篇很好的英文文章。
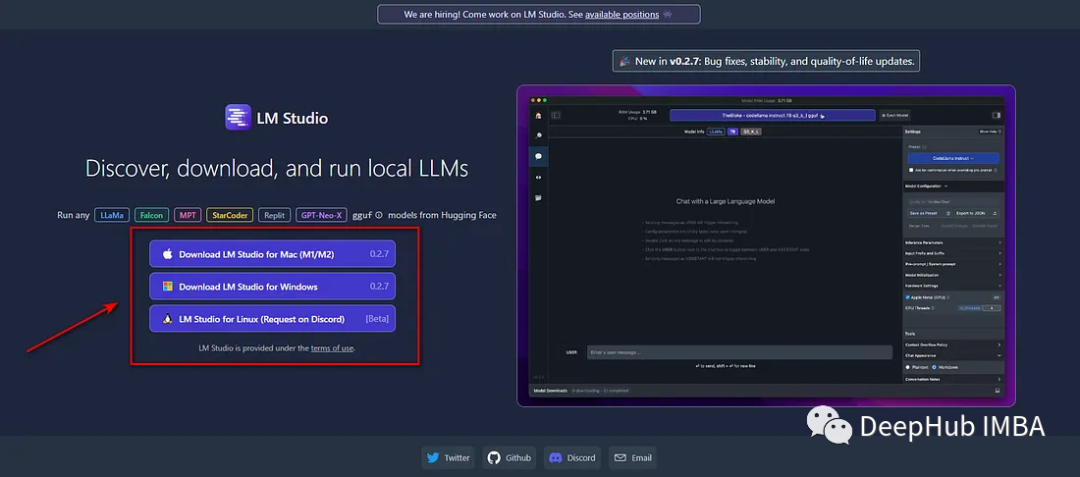
使用LM Studio在本地运行LLM完整教程
LM Studio是一个免费的桌面软件工具,它使得安装和使用开源LLM模型非常容易。
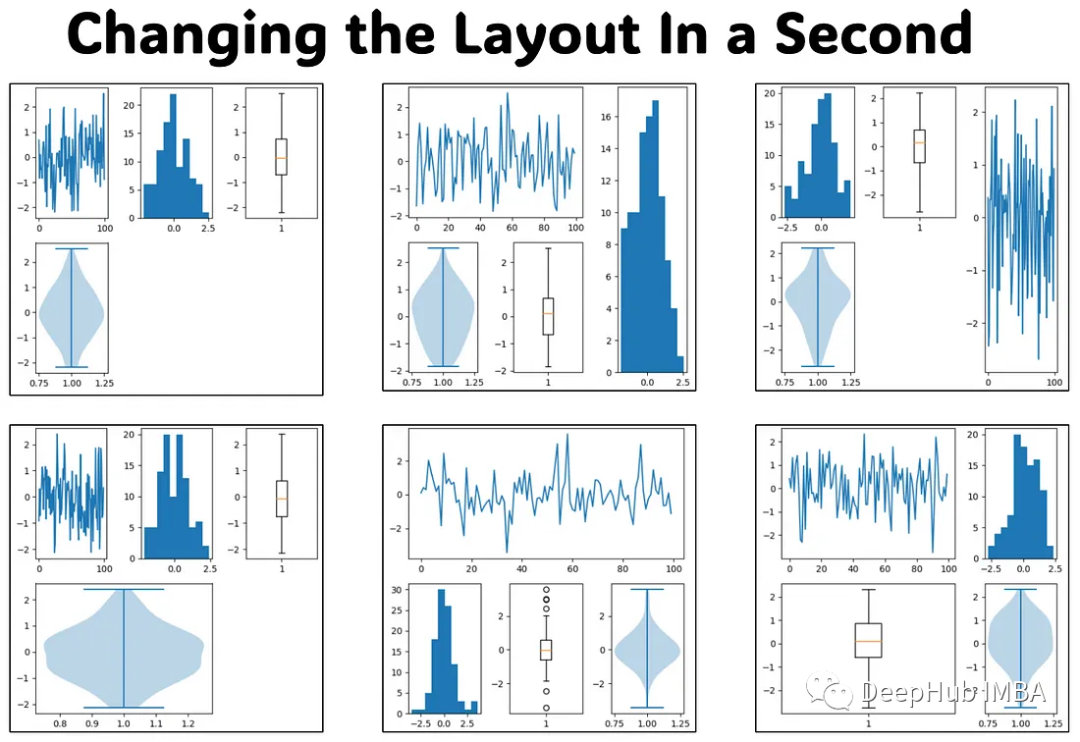
使用subplot_mosaic创建复杂的子图布局
在本文中,我将介绍matplotlib一个非常有价值的用于管理子图的函数——subplot_mosaic()。如果你想处理多个图的,那么subplot_mosaic()将成为最佳解决方案。我们将用四个不同的图实现不同的布局。
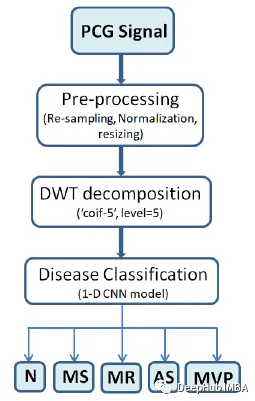
一种用于心音分类的轻量级1D-CNN+DWT网络
利用离散小波变换(DWT)得到的多分辨率域特征对1D-CNN模型进行心音分类训练。
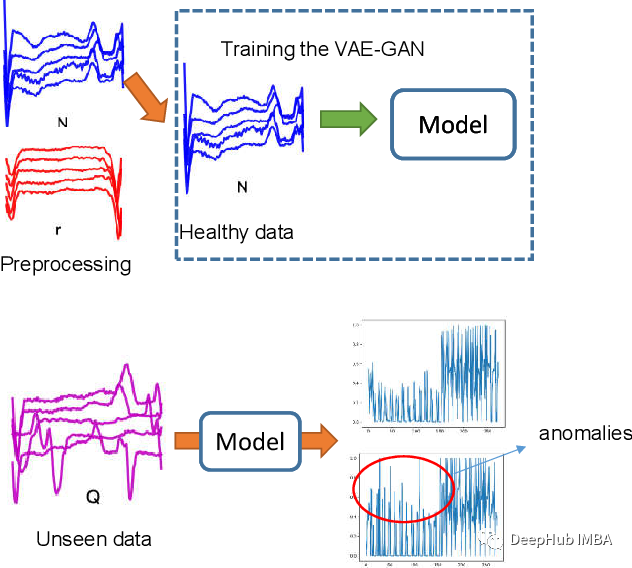
使用GAN进行异常检测
GAN是一种深度学习模型,可以学习生成与给定数据集相似的真实数据样本。这一特性表明它们可以成功地用于异常检测
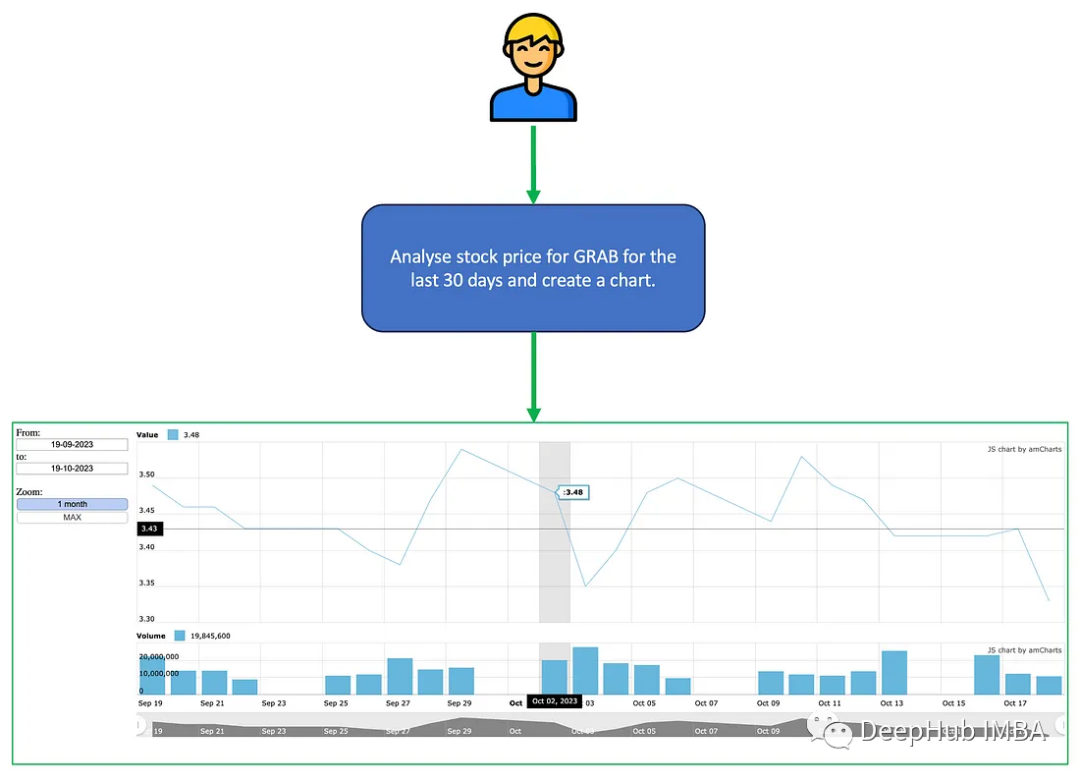
AutoGen多代理对话项目示例和工作流程分析
在这篇文章中,我将介绍AutoGen的多个代理的运行。这些代理将能够相互对话,协作评估股票价格,并使用AmCharts生成图表。