
在 SimCLS [2]论文发布后不久,作者又发布了抽象文本摘要任务的SOTA结果 [1]。BRIO在上述论文的基础上结合了对比学习范式。
BRIO解决什么问题?
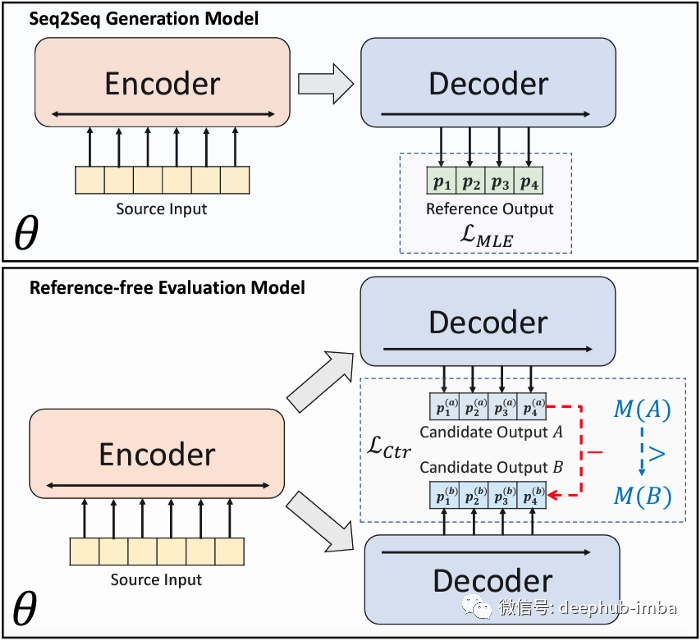
上图显示 seq2seq 架构中使用的传统 MLE 损失与无参考对比损失之间的差异。
我们通常使用最大似然估计(Maximum Likelihood Estimation, MLE)损失来训练序列模型。但是论文认为我们使用的损失函数将把一个本质上可能有多个正确输出(非确定性)的任务的“正确”输出(确定性)赋值为零。训练和推理过程之间也存在差异,在生成过程中模型是基于自己之前的预测步骤,而不是目标总结。在推理过程中,当模型开始偏离目标(并变得更加混乱)时,就会造成更严重的偏差。
论文的贡献
他们提出了合并评价指标(例如ROUGE、BERTScore,…)的想法,这样模型就可以学习如何对摘要进行排序。这是通过使用多样化Beam Search和生成多个候选(在论文中为16)来完成的。论文设计了一个两阶段的工作:1、使用一个预先训练的网络(BART)生成候选人,2、从中选择最好的一个。
对比损失(ctr)负责指导模型学习如何对给定文章的多个候选者进行排名。它将在微调过程中用于改进序列级别的协调。论文也说明了仅针对对比损失的微调模型不能用于生成摘要,因此将上述损失的加权值与交叉熵(xnet)损失相加,以确保令牌级别的预测准确性。(下图 2)它被称为多任务微调损失(mul),虽然 BRIO-Mul 被描述为“双重角色”模型,但它其实是一个单一的模型,既可以生成摘要,也可以评估生成的候选者的质量。
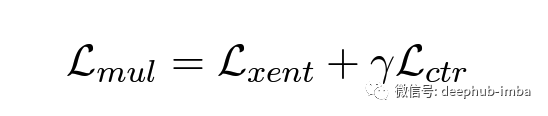
变量γ 控制对比损失对最终损失的贡献。对于不同的gamma值(0、0.1、1、2等)的研究表明,数值越大,收敛速度越快。此外100是最佳的γ值,获得了最高的ROUGE评分。
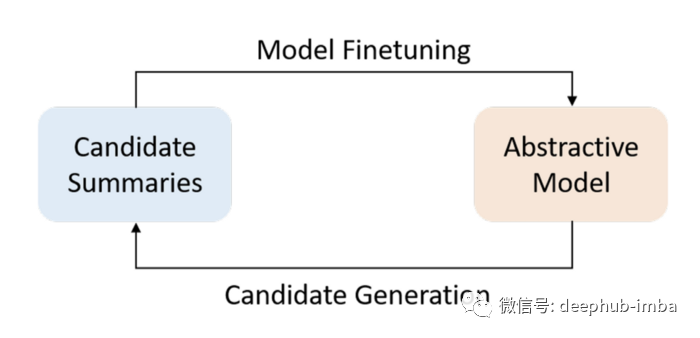
BRIO-Loop微调方案
论文的研究使用 BART 预训练模型进行生成阶段。但是使用 BRIO-Mul 模型是更好的,因为它已经超越了 BART 的性能。(如上图3所示)这个循环可以进一步提高ROUGE分数。
结果
BRIO方法刷新了三个抽象摘要数据集:CNN/DailyMail、XSum和NYT的的SOTA结果。从下图4可以看出,该方法对于长摘要和短摘要的数据集都有较好的性能。值得注意的是,BRIO-Loop模型仅在CNN/DM上进行了测试,将R-1分数提高到了48.01。

这篇论文中的两个观察结果。\1) BRIO [1] 和 SimCLR [2](之前的 SOTA)模型之间的主要区别在于使用单一模型进行生成和评分,以最大限度地提高 BRIO 中的参数共享,SimCLR 使用 RoBERTa 作为评估模型。\2) XSum 基准测试使用 PEGASUS 作为基础模型(而不是 BART),这表明该方法可以独立于模型的选择使用。
作者在分析他们的主张方面做得很好。在下一段中提到了其中的几个重点的观点。
- 增加Beam search的宽度:所提出的模型在 k 值较高的情况下表现更好。特别是 k=100时与使用 k=4 生成最佳输出的原始 BART 不同。
- Few-shot Fine-tuning:结果表明,在 CNN/DM 数据集上只有 100 个(随机选择的)样本和 PEGASUS 在 XSum 上只有 1000 个样本时,BRIO-few 可以胜过 BART。
- 新的 n-gram:与 BART 相比,BRIO 在摘要中生成更多新的 n-gram。
文中还有更多的分析,比如 Token-level Calibration、Training with different Metric、Filtering Inference Noise,我就不一一赘述了,但强烈推荐大家阅读。
作者能用一篇写得很好的分析论文来支持他们的想法。他们还在GitHub上发布了代码,帮助我们理解了其中的细节,这是一本很棒的读物。
引用
[1] Liu, Y., Liu, P., Radev, D., & Neubig, G. (2022). BRIO: Bringing Order to Abstractive Summarization. arXiv preprint arXiv:2203.16804.
[2] Liu, Y., & Liu, P. (2021). Simcls: A simple framework for contrastive learning of abstractive summarization. arXiv preprint arXiv:2106.01890.
作者:NLPiation