
虽然大多数的特征策略都与领域相关,并且必须针对每个应用程序进行专门调整。但特征工程是操纵原始数据和提取机器学习特征的过程,探索性数据分析 (EDA) 可以使用特征工程技术来可视化数据并在执行机器学习任务之前更好地识别模式和异常值。这是数据科学的重要一步,可以确保特定机器学习应用程序的预期结果。
使用 EDA 和特征工程的组合具有多种优势:
- 提高准确性
- 减少训练时间
- 减少过拟合
- 简化模型
特征工程技术
有多种特征工程方法可以用于机器学习的各种特定应用和数据类型。这些可以包括:
- 转换——缩放或编码数据以便模型更好地理解
- 分类编码
- 特征缩放
- 特征选择——挑选出不必要或导致模型准确性降低的特征
- 特征创建——创建从其他特征中提取或结合的新特征,以便对模型更有用
- 特征提取——通常是某种形式的降维(PCA、ICA 等)
- 自动编码器
在典型的机器学习项目中,数据科学家会使用特征工程技术的组合创建复杂的管道,处理数据并为机器学习做好准备。这个过程通常是机器学习中最繁琐和最需要技能的部分。
端到端的特征转换
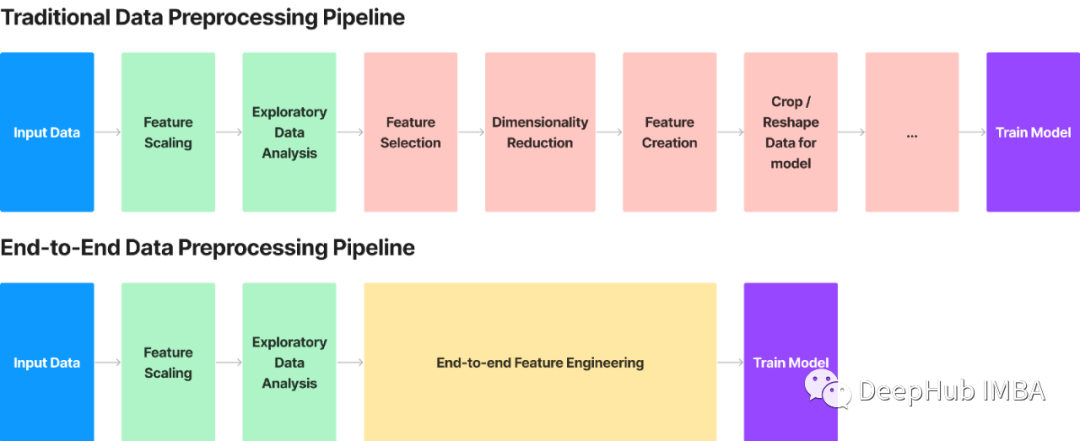
复杂特征工程管道的一个潜在替代方案是端到端的特征转换。在端到端方法中,机器学习从原始输入数据到输出预测的整个过程是通过一个连续的管道来学习的。端到端管道所需的配置较少,并且可以轻松应用于多种形式的数据。但是使用特征工程的方法可以比端到端方法做得更好,因为它们可以针对特定任务进行更好的调整。
端到端特征工程方法不会取代 EDA。换句话说,端到端的特征转换方法也是一种特征工程,它使用机器学习模型将原始数据直接转换为可用于提高模型准确性的数据。此过程几乎不需要对数据进行预处理,并且可以轻松应用于许多领域。
在 Jean-Yves Franceschi 等人的论文“Unsupervised Scalable Representation Learning for Multivariate Time Series”。通过卷积和三元组损失学习数据的表示,并提出了一种端到端的特征转换方法,这种使用无监督卷积的方法简化并应用于各种数据。
简而言之,他们正在实现一个卷积神经网络,该网络将转换和提取特征,然后将其发送到你选择的机器学习模型执行预测。经过适当训练,这个 CNN 将能够为我们的模型提取重要特征,并准确执行其给定任务。
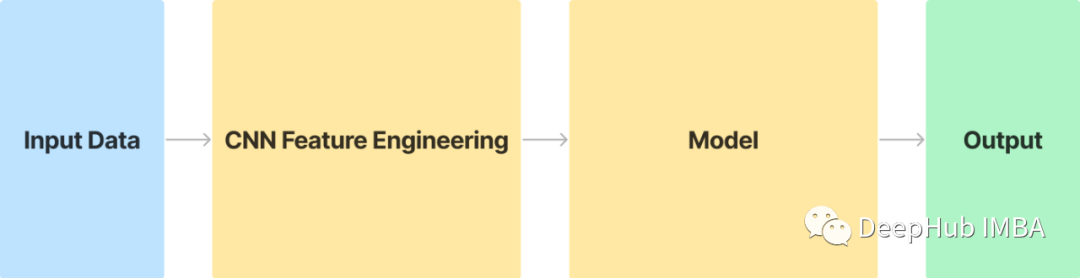
在本文中,我将使用来Pytorch , sklearn 和Kaggle的牛油果价格数据集🥑(https://www.kaggle.com/datasets/neuromusic/avocado-prices?resource=download)来演示这种 CNN 特征工程技术。

首先,需要从 kaggle 下载数据集,并做一些简单的数据准备,例如删除不需要的特征/从df中提取我们的目标列。
df = pd.read_csv("avocado.csv")
df = df.drop(columns=['Unnamed: 0',"Date", "type", "region"])
接下来,我们需要准备两个df副本。一个副本按我们所需的目标值列(在本例中为“AveragePrice”)排序,另一个应保持原样。
df的排序副本将用于训练我们的卷积特征工程层,另一个副本将用于训练主模型。
# unsorted training data
y = df["AveragePrice"].to_numpy()
x = df.drop(columns=["AveragePrice"])
# sorted training data
x_s = df.sort_values(by="AveragePrice")
x_s = x_s.drop(columns=["AveragePrice"])
在继续之前,需要将df转换为 pytorch 张量。
x = torch.Tensor(x.to_numpy()).reshape(-1,1,9)
x_s = torch.Tensor(x_s.to_numpy()).reshape(-1,1,9)
这就是我们在将数据输入 CNN 之前需要执行的所有预处理。
下一步是实现我们将用于特征提取和转换的 CNN。实现非常简单,五个 1D 卷积层,内核大小为 1,膨胀增加了 3 倍。当然,这些都是超参数,可以进行试验和改进。
class FeatureEngineering(nn.Module):
def __init__(self, out):
super().__init__()
self.conv1 = nn.LazyConv1d(out,1, dilation=3)
self.conv2 = nn.LazyConv1d(out,1, dilation=9)
self.conv3 = nn.LazyConv1d(out,1, dilation=27)
self.conv4 = nn.LazyConv1d(out,1, dilation=81)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
return x
现在我们可以开始训练CNN 特征工程网络了!CNN 使用triplet loss 进行训练,该损失考虑了三个变量:anchor、positive 和negative。anchor是当前样本。positive 是与anchor相似的样本(同一类,或者在我们的例子中,具有相似的目标值),negative可以是与anchor不同的随机样本。
我们将使用 2 个随机数来获得anchor、positive 和negative。第一个随机索引处的项目是anchor。由于 CNN 训练数据集是按目标值排序的,所以可以直接使用anchor之后的样本作为positive 。另一个随机数将用于获取negative。
iters = 30000
for iter in range(iters):
indx_1 = np.random.randint(237 - 1)
indx_2 = np.random.randint(237 - 1)
# anchor
a = ft(x_s[indx_1])
# positive
p = ft(x_s[indx_1 + 1])
# negative
n = ft(x_s[indx_2])
# perform triplet loss
loss = triplet_loss(a,p,n)
loss.backward()
with torch.no_grad():
ft.zero_grad()
在创建和训练CNN 特征工程层之后,需要使用 CNN 特征工程层来转换特征,并使用 sklearn 的 train_test_split 分割训练/测试数据。
# transform data using fe
trans_x = []
for i in x:
trans_x.append( ft(torch.Tensor(i)).detach().numpy() )
trans_x = np.array(trans_x)
print(trans_x.shape)
trans_x = trans_x.reshape(-1, 36)
# train test split for transformed data
x_train_trans, x_test_trans, y_train_trans, y_test_trans = train_test_split(trans_x,y,)
# train test split for untransformed data
x = x.reshape(-1, 9)
x_train, x_test, y_train, y_test = train_test_split(x,y)
就是这样!这就是我们在将转换后的数据输入最终模型之前需要做的所有数据准备工作!
rg = RandomForestRegressor()
rg.fit(x_train_trans,y_train_trans)
总结
传统的特征工程和数据预处理流程可能既复杂又耗时。使用卷积神经网络和三元组损失的端到端特征工程方法是复杂特征工程方法的替代方法,可以在几乎不需要配置的情况下提高模型的性能。
这些基于 CNN 的特征工程方法可以与任何模型一起使用,并且可以适应几乎任何机器学习管道。并且可以尝试不同的超参数以达到最佳效果!
引用:
[1] J. Y. Franceschi, A. Dieuleveut, A. Jaggi, Unsupervised scalable representation learning for multivariate time series, NeurIPS (2019) https://arxiv.org/abs/1901.10738
作者:Ryan Du