
Micro-Outlier Removal:这个词听起来不错。但是这个术语是本文的作者首创的。所以应该找不到其他相关的资料,但是看完本篇文章你就可以了解这个词的含义。
在Kaggle 的《Titanic》排行榜中,作者使用这项技术获得了巨大排名飞跃-
在使用这个技术之前排名是12616
使用这个技术后排名是4057

Micro-Outlier Removal的动机
有许多改善机器学习模型的技术:超参数优化,网格搜索,甚至自动ML,那么现在还缺少什么呢?作者感觉缺啥一种基于直觉的可视化方法。因为 通过基于直觉的可视化方法可以超越目前所有机器学习优化技术,因为现在人工智能的技术还是在模拟人类。

现在让我们看看Micro-Outlier Removal是什么样子的
Micro-Outlier 定位方法
这是作者使用的泰坦尼克数据模型训练的一些信息:
- 只使用了以下特征:PClass, Sex, SibSp, Parch, Fare, Embarked.
- 没有使用年龄,因为它包含很多缺失的值。
- 没有进行其他的工程
- 使用的机器学习算法是基本的5级决策树,使用30-70的拆分策略
这里显示的是基于训练数据集和决策树算法的决策边界。下图中的图例表示下图中颜色的含义。
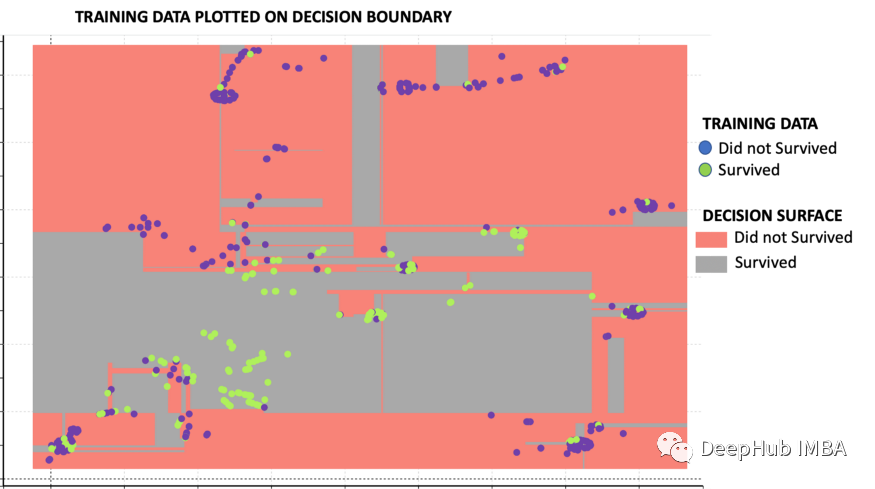
上图中可以看到以下几个观点:预测生存的决策面(绿色区域)大多位于中间。预测非存活的决策面(红色区域)主要位于两侧。一般来说,没有幸存下来的乘客(蓝点)被分组在一起。类似地,幸存的乘客(绿点)被分组在一起。
Micro-Outlier 定位方法如下:
- 一群非幸存者中的幸存者
- 一群幸存者中的非幸存者
下图显示了带有白色箭头的小异常值。
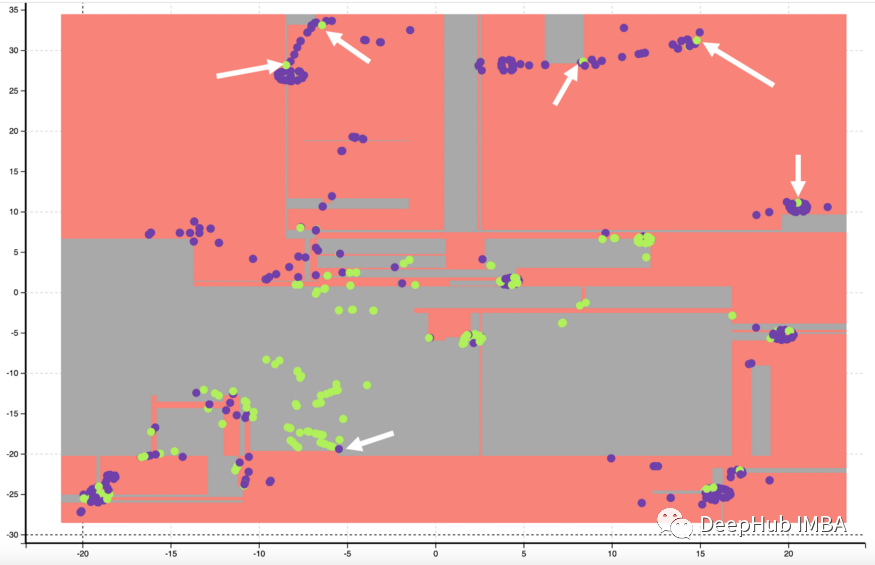
分析micro-outliers
为了更好地理解离群点,让我们分析一下位于左上角的micro-outliers。可视化的分析方法如下面的动画图像所示。当我们悬停在每个点上时,它显示了每个点的柱的雷达图。

你会发现所有的点都与男性乘客有关,他们的PCLass(即三等)很高,而且是从s港出发的乘客。所有这些乘客都没有幸存,除了这几个小的异常点。
这里的小异常是乘客尤金·帕特里克·戴利。他是一名三等舱乘客,坐在下层甲板上,他跳进了冰冷的水里。他没有活下来的机会。但是报道中说,他活了下来的原因是他的大衣很厚,他把这件大衣保存了很多年,并把它称为“幸运大衣”。

虽然我们为他能够活下来感到高兴,但他并不适合机器学习!因为一些模糊的原因(如大衣的厚度)幸存下来对我们来说就是异常值,这会干扰我们的机器学习模型。我们并不知道每个乘客的外套厚度。所以最好的办法就是把它从训练数据中去掉。
通过这种技术来识别泰坦尼克号数据中这些“幸运”的人!因为这是任何经典的异常值检测算法都无法做到这一点。
作者移除了6小的异常点然后训练模型,与没有删除异常值的相比,排名有了很大的提升。
总结
这是一种很好的基于直觉的方法,在不需要大量复杂编码的情况下提高机器学习模型的准确性。在某种程度上,我们正在移除那些可能使模型不必要地复杂化的数据点,从而获得整体模型的准确性。
之所以称这个方法为小技巧是因为他可能只针对于某些特定的数据集,并且这个方法也说明了:80%的数据+20%的模型=更好的机器学习,今天这篇文章的目的其实很简单,就是想说明有时kaggle上的高排名并不是因为模型,而是因为特殊的数据处理方法。
作者:Pranay Dave