
Deephub
更多文章请关注公众号:Deephub-IMBA
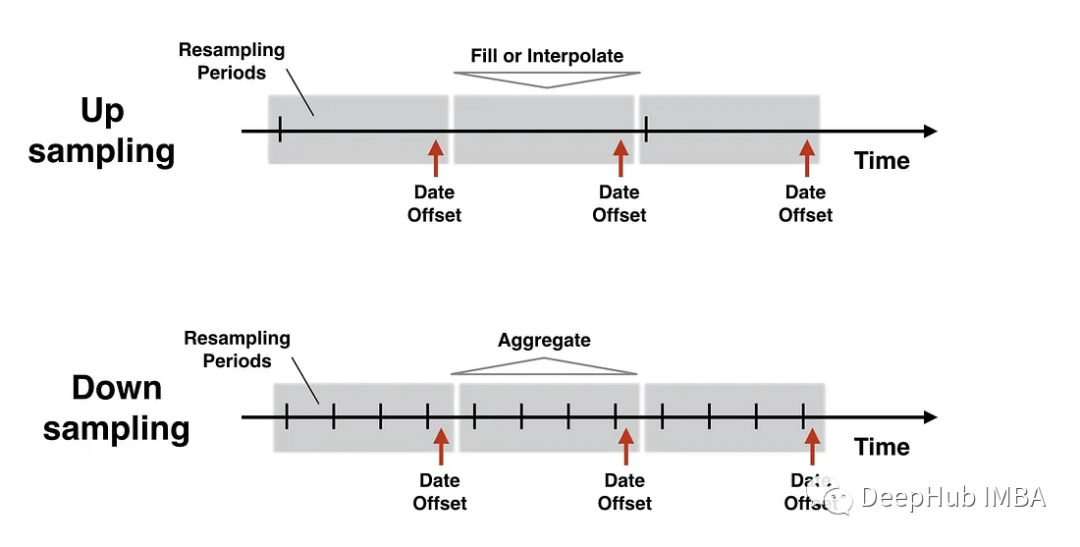
时间序列的重采样和pandas的resample方法介绍
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。
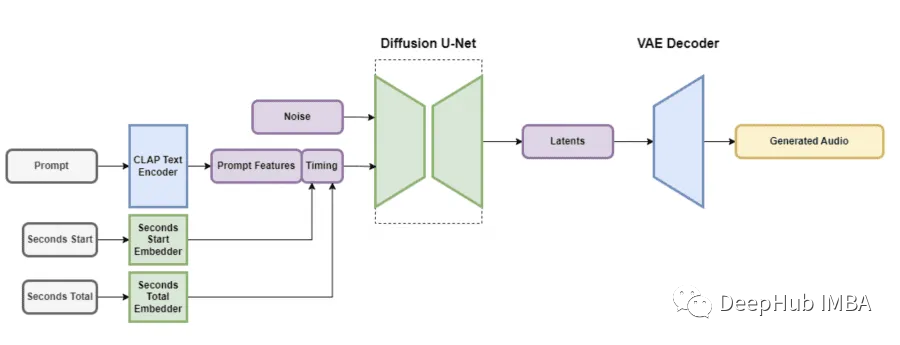
Stability AI发布基于稳定扩散的音频生成模型Stable Audio
近日Stability AI推出了一款名为Stable Audio的尖端生成模型,该模型可以根据用户提供的文本提示来创建音乐。
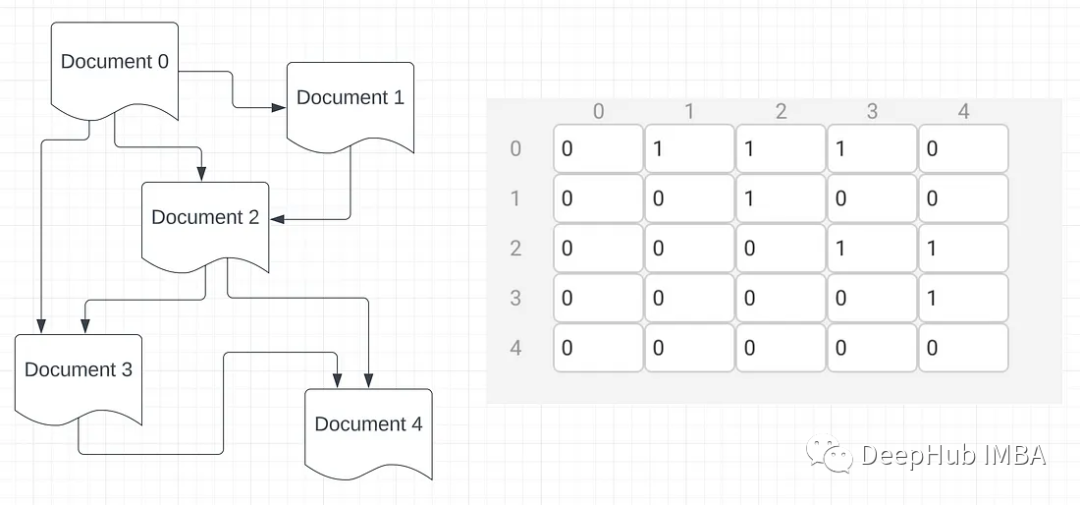
图注意网络(GAT)的可视化实现详解
能够可视化的查看对于理解图神经网络(gnn)越来越重要,所以在这篇文章中,我将介绍传统GNN层的实现,然后展示ICLR论文“图注意力网络”中对传统GNN层的改进。
Python中进行特征重要性分析的9个常用方法
特征重要性分析用于了解每个特征(变量或输入)对于做出预测的有用性或价值。目标是确定对模型输出影响最大的最重要的特征,它是机器学习中经常使用的一种方法。

Recognize Anything:一个强大的图像标记模型
Recognize Anything是一种新的图像标记基础模型,与传统模型不同,它不依赖于手动注释进行训练;相反,它利用大规模的图像-文本对

向量数据库简介和5个常用的开源项目介绍
本文旨在全面介绍向量数据库,并介绍2023年可用的最佳向量数据库。

Llama-2 推理和微调的硬件要求总结:RTX 3080 就可以微调最小模型
大语言模型微调是指对已经预训练的大型语言模型(例如Llama-2,Falcon等)进行额外的训练,以使其适应特定任务或领域的需求。

Falcon 180B 目前最强大的开源模型
Technology Innovation Institute最近发布了Falcon 180B大型语言模型(LLM),它击败了Llama-2 70b,与谷歌Bard的基础模型PaLM-2 Large不相上下。
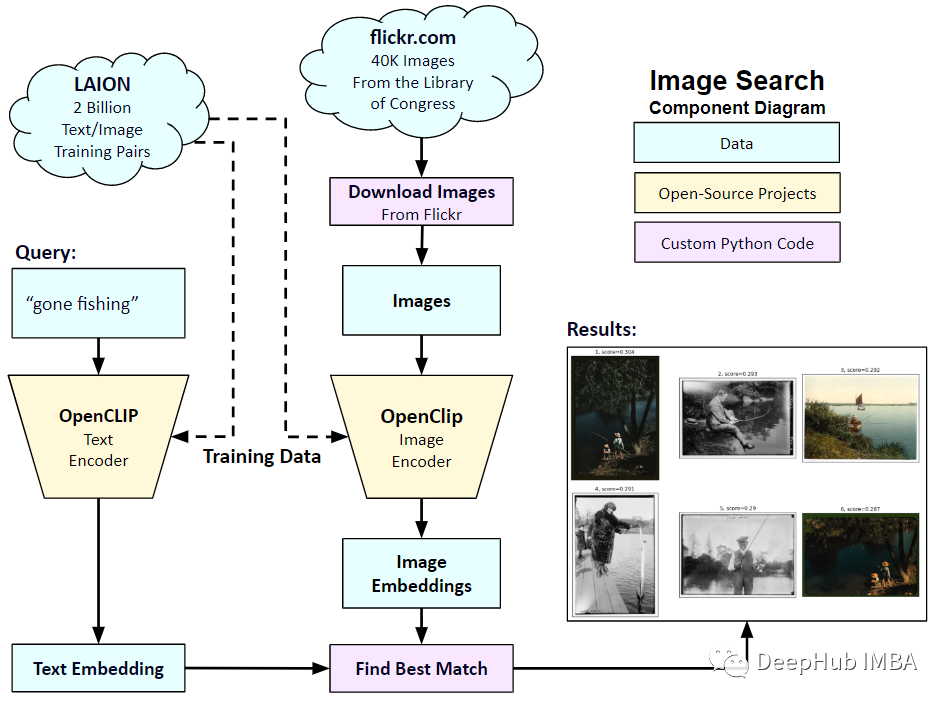
在自定义数据集上实现OpenAI CLIP
在本文中,我们将使用PyTorch中从头开始实现CLIP模型,以便我们对CLIP有一个更好的理解

Langchain的一些问题和替代选择
Langchain因其简化大型语言模型(llm)的交互方面的到关注。凭借其高级的API可以简化将llm集成到各种应用程序中的过程。
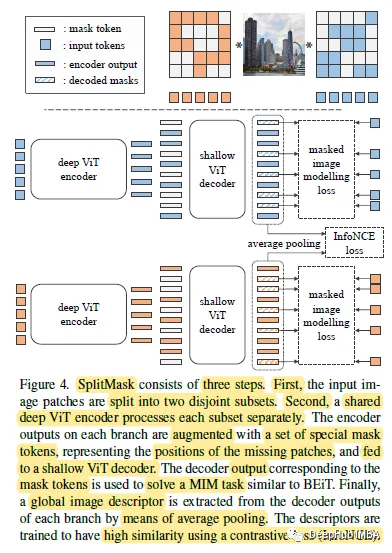
SplitMask:大规模数据集是自我监督预训练的必要条件吗?
自监督预训练需要大规模数据集吗?这是2021年发布的一篇论文,提出了一种类似于BEiT的去噪自编码器的变体SplitMask,它对预训练数据的类型和大小具有更强的鲁棒性。
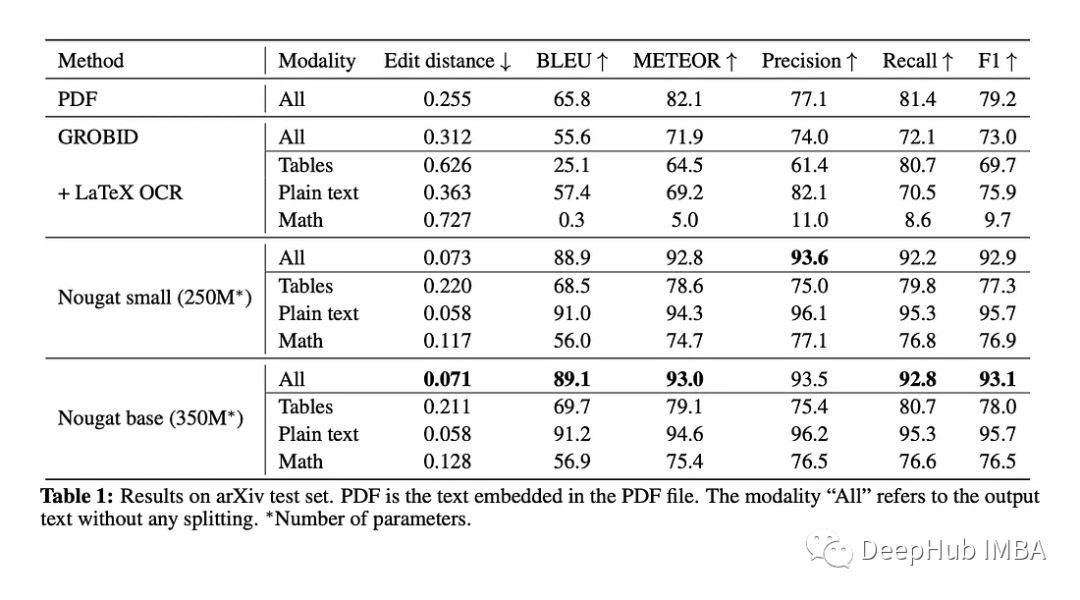
Nougat:一种用于科学文档OCR的Transformer 模型
Nougat是一种VIT模型。它的目标是将这些文件转换为标记语言,以便更容易访问和机器可读。
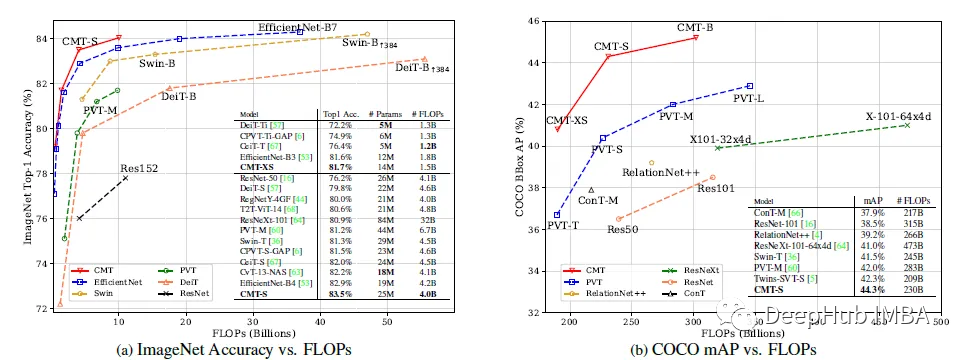
CMT:卷积与Transformers的高效结合
论文提出了一种基于卷积和VIT的混合网络,利用Transformers捕获远程依赖关系,利用cnn提取局部信息。构建了一系列模型cmt,它在准确性和效率方面有更好的权衡。
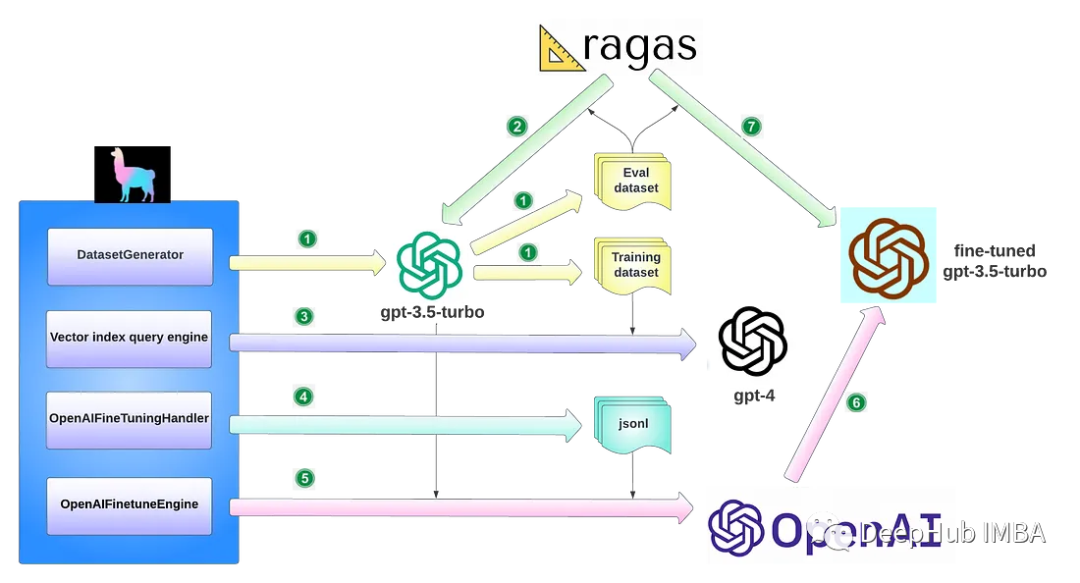
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
我们现在可以使用GPT-4生成训练数据,然后用更便宜的API(gpt-3.5 turbo)来进行微调,从而获得更准确的模型,并且更便宜。

Pandas DataFrame 数据存储格式比较
Pandas 支持多种存储格式,在本文中将对不同类型存储格式下的Pandas Dataframe的读取速度、写入速度和大小的进行测试对比。
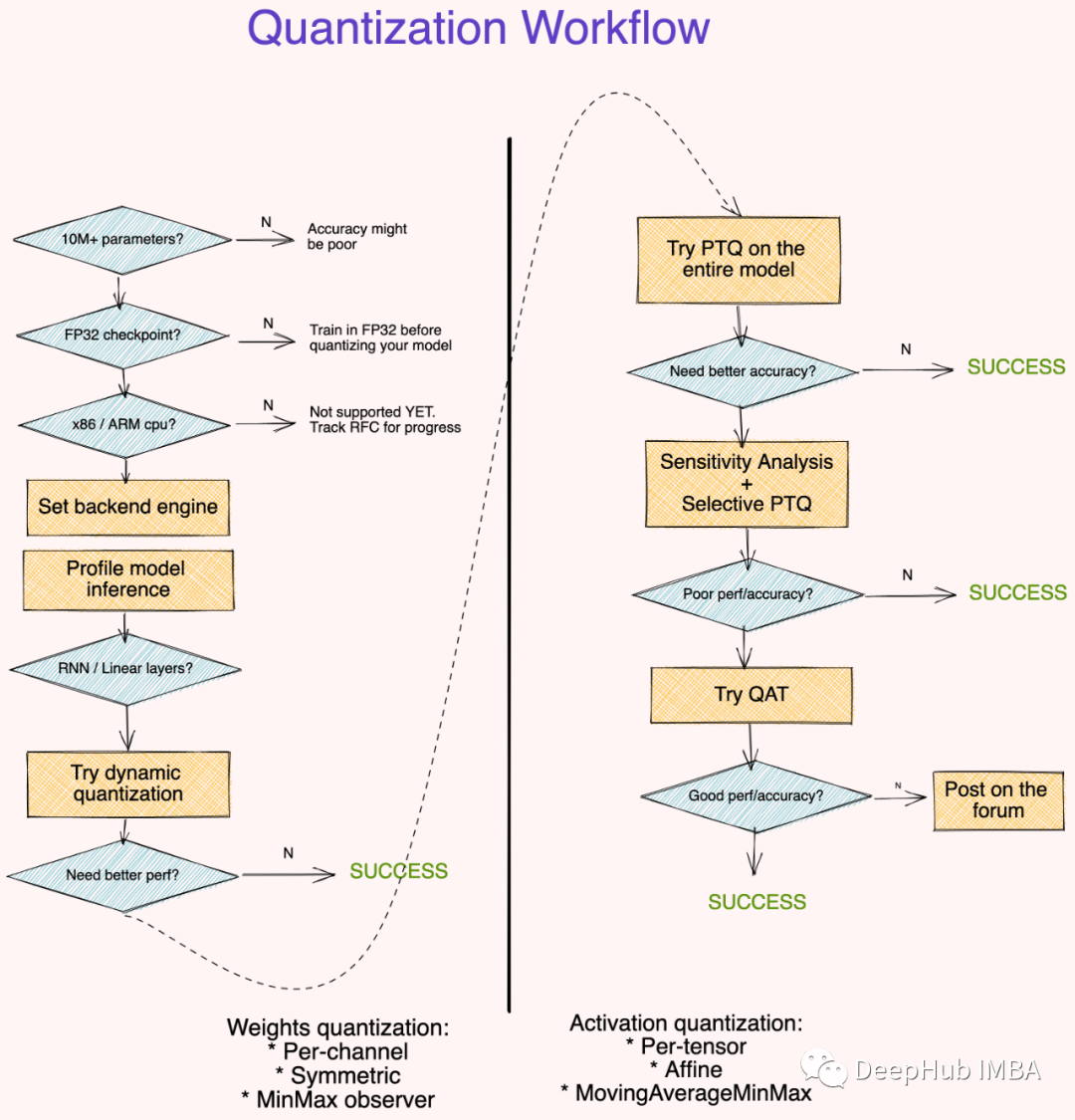
量化自定义PyTorch模型入门教程
基础模型与量化模型具有相似的准确性,但模型尺寸大大减小,这在我们希望将其部署到服务器或低功耗设备上时至关重要。

15个基本且常用Pandas代码片段
以上这15个Pandas代码片段是我们日常最常用的数据操作和分析操作。熟练的掌握它,并将它们合并到工作流程中,可以提高处理和探索数据集的效率和效果。

20用于深度学习训练和研究的数据集
本文将整理常用且有效的20个数据集。

Pandas 2.1发布了
2023年3月1日,Pandas 发布了2.0版本。6个月后(8月30日),更新了新的2.1版。让我们看看他有什么重要的更新。

是否在业务中使用大语言模型?
但LLM究竟是什么,它们如何使你的企业受益?它只是一种炒作,还是会长期存在?