
Deephub
更多文章请关注公众号:Deephub-IMBA
可视化FAISS矢量空间并调整RAG参数提高结果精度
在本文中,我们将使用可视化库renumics-spotlight在2-D中可视化FAISS向量空间的多维嵌入,并通过改变某些关键的矢量化参数来寻找提高RAG响应精度的可能性。

谷歌Gemma介绍、微调、量化和推理
这篇文章我们将介绍Gemma模型,然后展示如何使用Gemma模型,包括使用QLoRA、推理和量化微调。
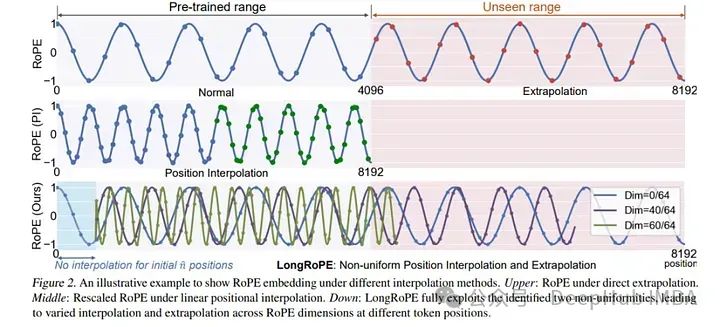
2024年2月深度学习的论文推荐
我们这篇文章将推荐2月份发布的10篇深度学习的论文
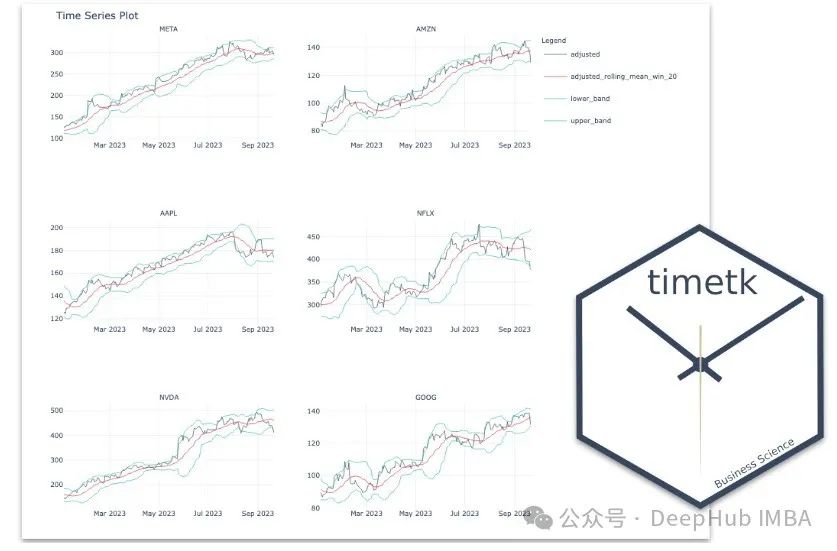
PyTimeTK: 一个简单有效的时间序列分析库
我最近在Github上发现了一个刚刚发布不久的Python时间工具包PyTimeTK ,它可以帮我们简化时间序列分析的很多步骤。
选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
本文将OpenAI新模型与开源模型的性能进行实证比较。
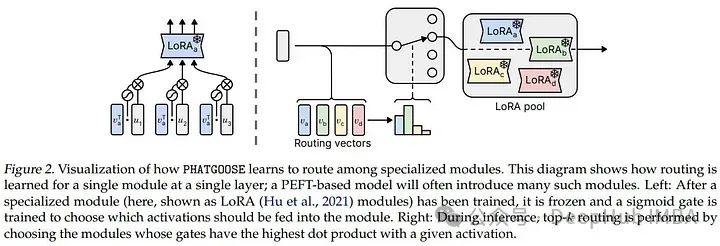
PHATGOOSE:使用LoRA Experts创建低成本混合专家模型实现零样本泛化
这篇2月的新论文介绍了Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE),这是一种通过利用一组专门的PEFT模块(如LoRA)实现零样本泛化的新方法
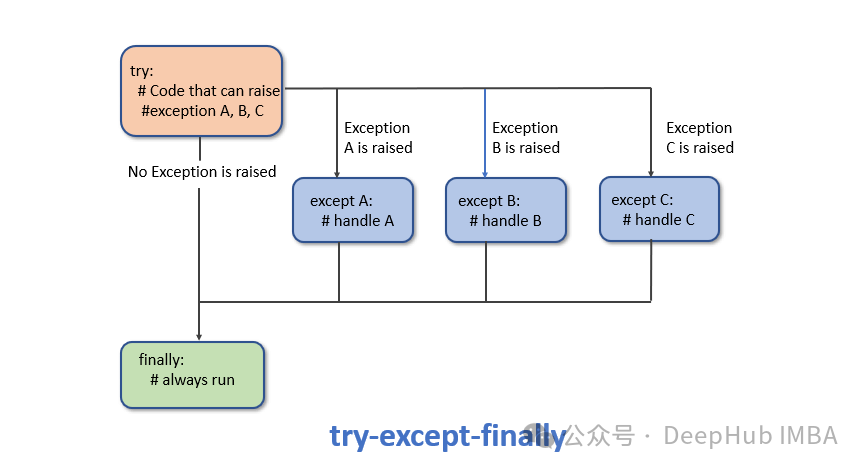
20个改善编码的Python异常处理技巧,让你的代码更高效
本文将介绍关于Python异常的20个可以显著改善编码的Python异常处理技巧,这些技巧可以让你熟练的掌握Python的异常处理。
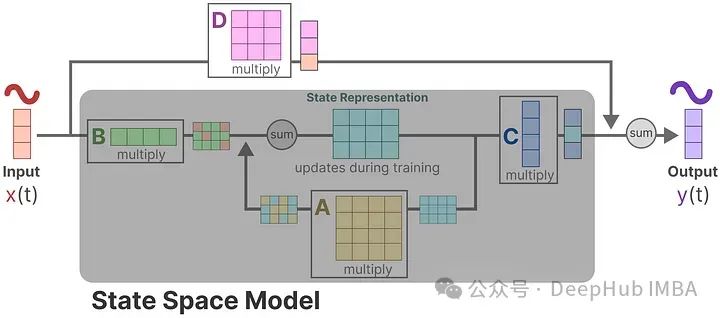
Mamba详细介绍和RNN、Transformer的架构可视化对比
在本篇文章中,通过将绘制RNN,transformer,和Mamba的架构图,并进行详细的对比,这样我们可以更详细的了解它们之间的区别。
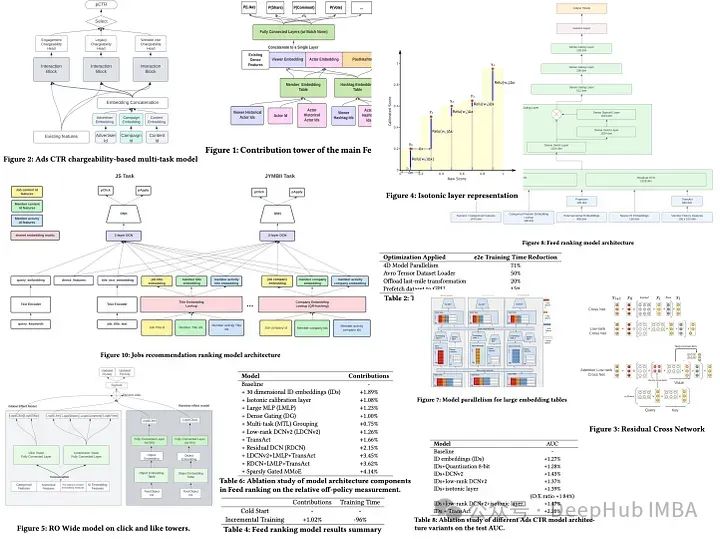
LiRank: LinkedIn在2月新发布的大规模在线排名模型
LiRank是LinkedIn在2月份刚刚发布的论文,它结合了最先进的建模架构和优化技术,包括残差DCN、密集门控模块和Transformers。
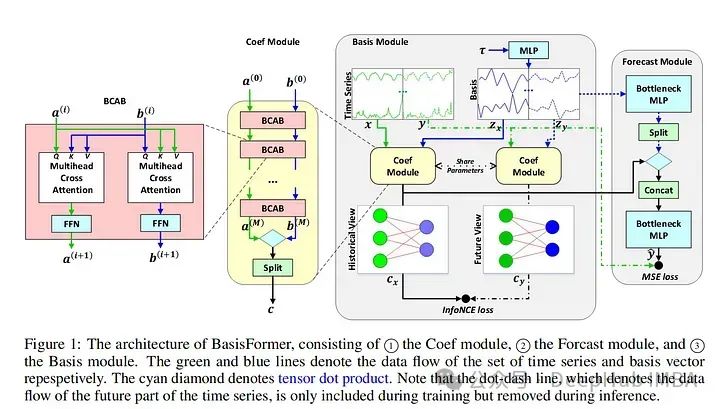
深度学习在时间序列预测的总结和未来方向分析
我们这篇文章就来总结下2023年深度学习在时间序列预测中的发展和2024年未来方向分析

视频生成领域的发展概述:从多级扩散到LLM
在这篇文章中,我们将整理视频生成在最近几年是发展概况,模型的架构是如何发展的,以及现在面临的突出问题。

4张图片就可以微调扩散模型
我们今天使用DreamBooth在不影响模型原始功能的情况下实现微调过程。
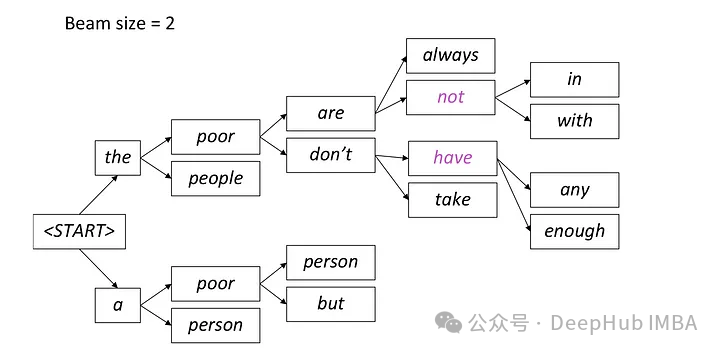
自然语言生成任务中的5种采样方法介绍和Pytorch代码实现
在自然语言生成任务(NLG)中,采样方法是指从生成模型中获取文本输出的一种技术。本文将介绍常用的5中方法并用Pytorch进行实现。
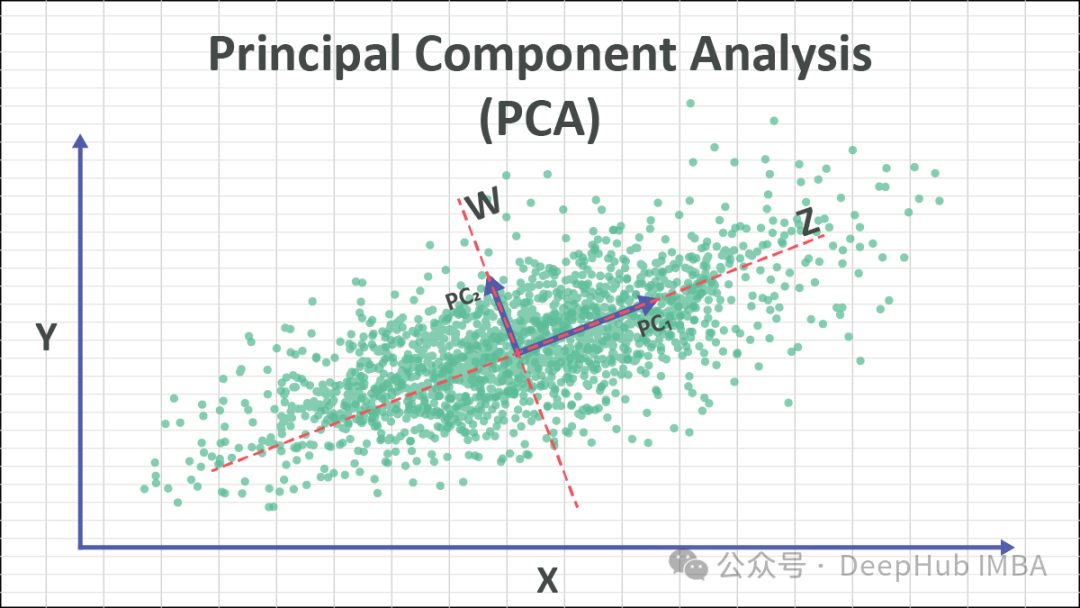
机器学习中7种常用的线性降维技术总结
上篇文章中我们主要总结了非线性的降维技术,本文我们来总结一下常见的线性降维技术。
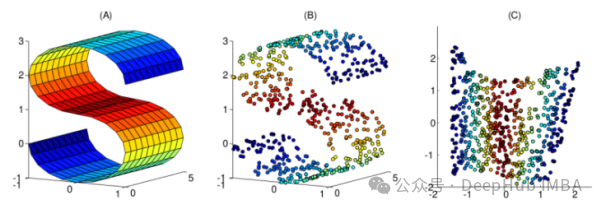
机器学习中的10种非线性降维技术对比总结
本文整理了10个常用的非线性降维技术,可以帮助你在日常工作中进行选择
Lag-Llama:第一个时间序列预测的开源基础模型介绍和性能测试
在本文中,我们将探讨Lag-Llama的架构、功能以及训练方式。还会将lagllama应用于一个预测项目中,并将其与其他深度学习方法Temporal Fusion Transformer (TFT) 和DeepAR进行性能比较。
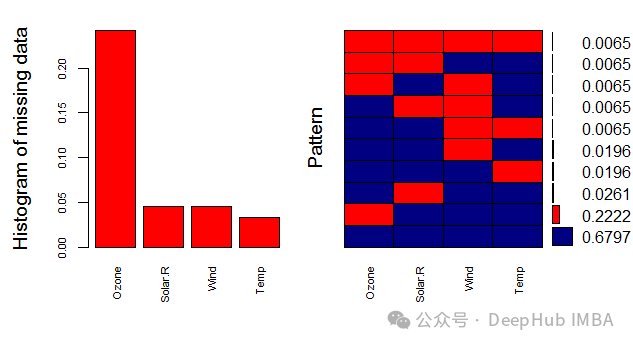
使用MICE进行缺失值的填充处理
MICE(Multiple Imputation by Chained Equations)是一种常用的填充缺失数据的技术。它通过将待填充的数据集中的每个缺失值视为一个待估计的参数,然后使用其他观察到的变量进行预测。
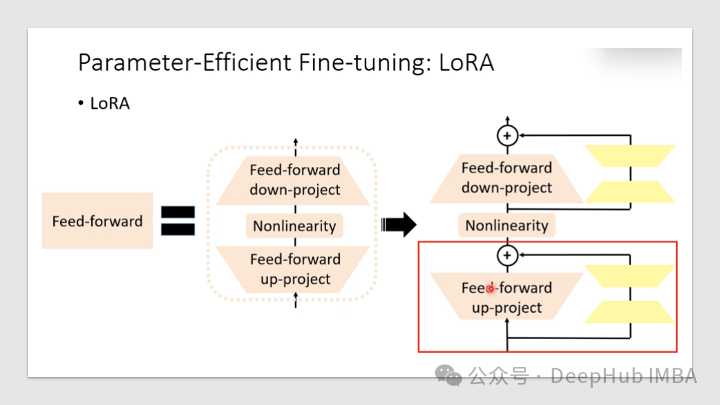
使用LORA微调RoBERTa
LORA可以大大减少了可训练参数的数量,节省了训练时间、存储和计算成本,并且可以与其他模型自适应技术(如前缀调优)一起使用,以进一步增强模型。

使用PyOD进行异常值检测
异常值检测各个领域的关键任务之一。PyOD是Python Outlier Detection的缩写,可以简化多变量数据集中识别异常值的过程。在本文中,我们将介绍PyOD包,并通过实际给出详细的代码示例
使用UMAP降维可视化RAG嵌入
在本文中,我们使用LangChain构建RAG应用,并在2D中可视化嵌入,分析查询和文档片段之间的关系和接近度。