
Deephub
更多文章请关注公众号:Deephub-IMBA
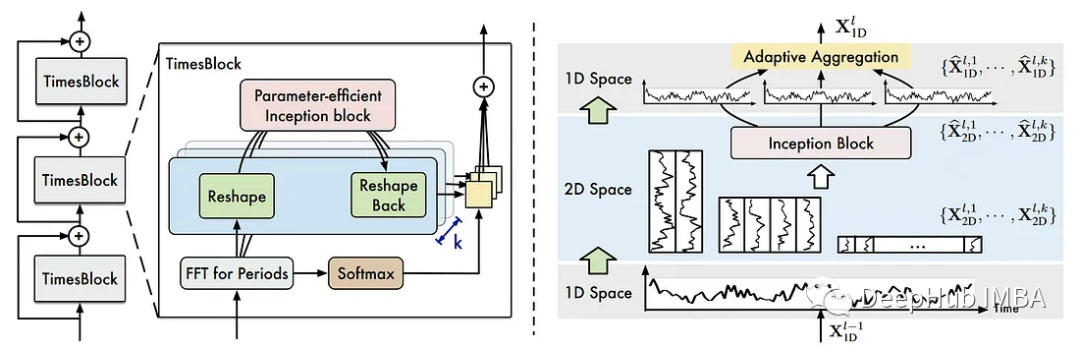
TimesNet:时间序列预测的最新模型
在本文中,我们将探讨TimesNet的架构和内部工作原理。然后将该模型应用于预测任务,与N-BEATS和N-HiTS进行对比。
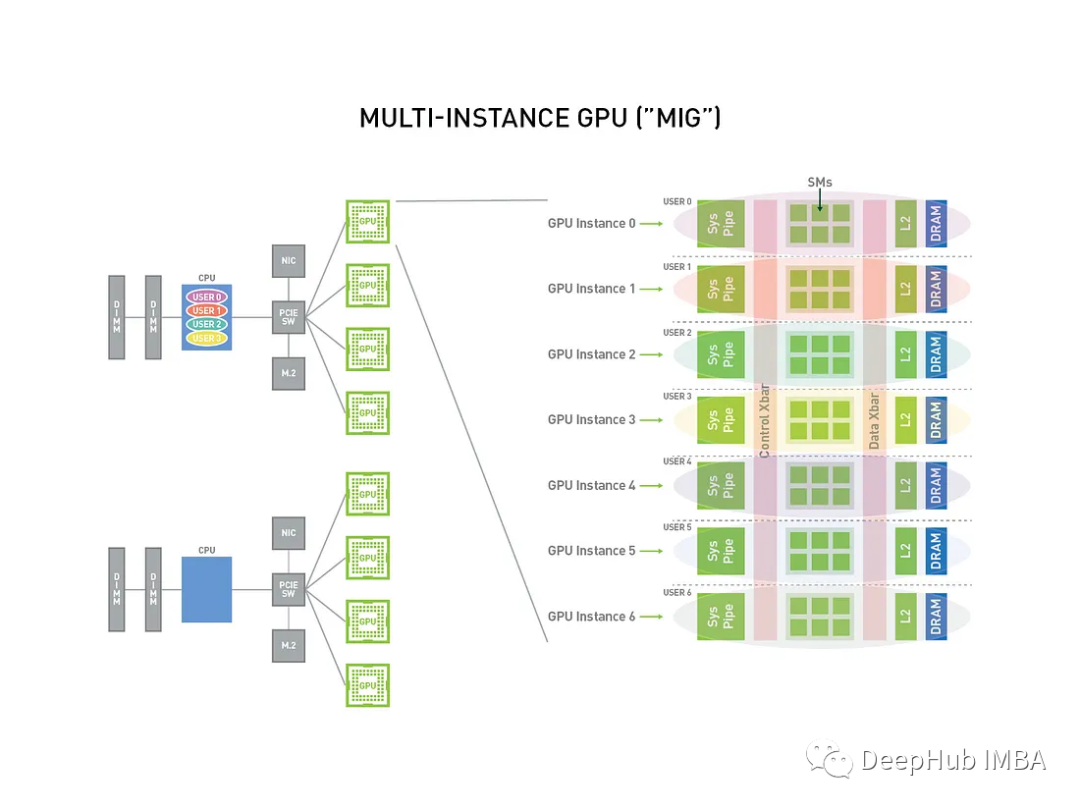
GPU 虚拟化技术MIG简介和安装使用教程
使用多实例GPU (MIG/Multi-Instance GPU)可以将强大的显卡分成更小的部分,每个部分都有自己的工作,这样单张显卡可以同时运行不同的任务。本文将对其进行简单介绍并且提供安装和使用的示例。
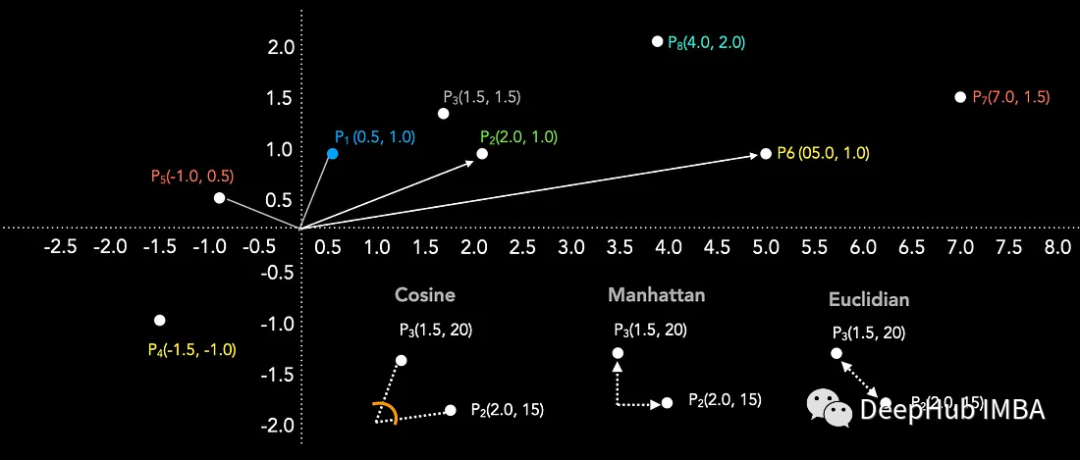
常用的相似度度量总结:余弦相似度,点积,L1,L2
本文将介绍几种常用的用来计算两个向量在嵌入空间中的接近程度的相似性度量。
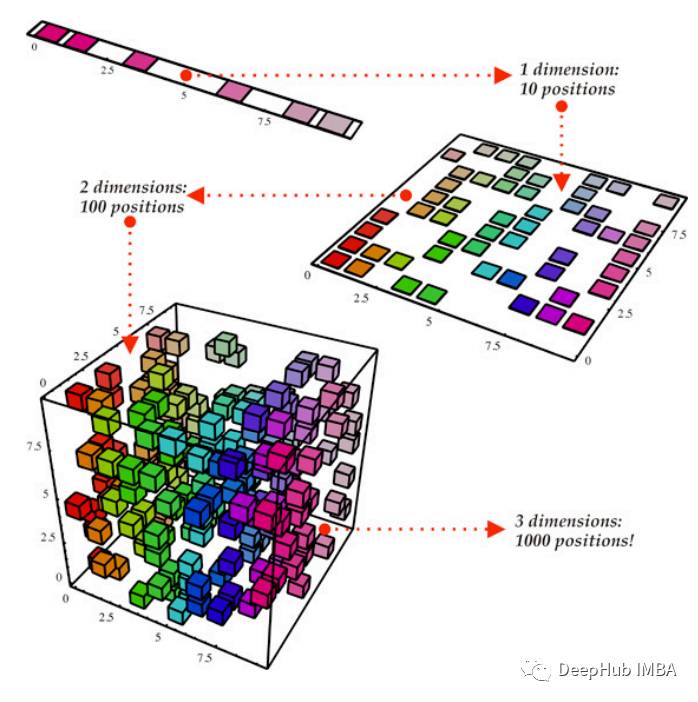
三个主要降维技术对比介绍:PCA, LCA,SVD
本文将深入研究三种强大的降维技术——主成分分析(PCA)、线性判别分析(LDA)和奇异值分解(SVD)。我们不仅介绍这些方法的基本算法,而且提供各自的优点和缺点。
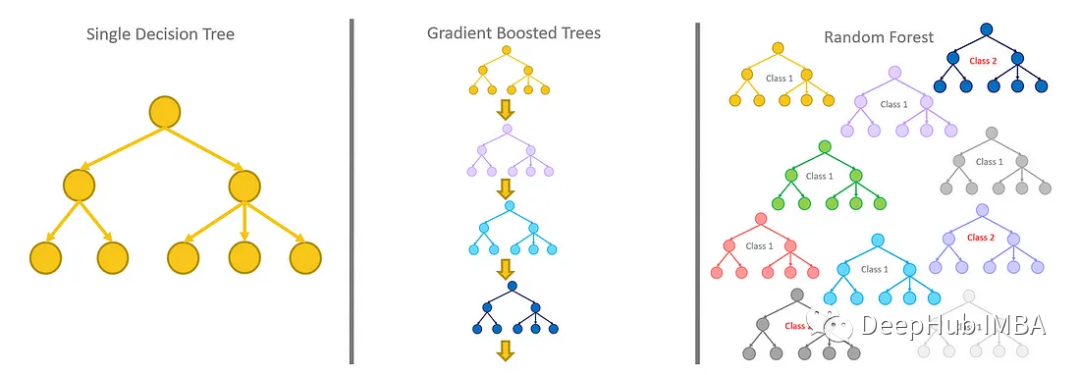
XGBoost 2.0:对基于树的方法进行了重大更新
XGBoost是处理不同类型表格数据的最著名的算法,LightGBM 和Catboost也是为了修改他的缺陷而发布的。9月12日XGBoost发布了新的2.0版,本文除了介绍让XGBoost的完整历史以外,还将介绍新机制和更新。
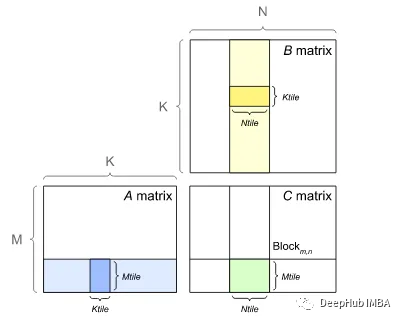
从GPU的内存访问视角对比NHWC和NCHW
NHWC和NCHW之间的选择会影响内存访问、计算效率吗?本文将从模型性能和硬件利用率来尝试说明这个问题。

CLIP与DINOv2的图像相似度对比
在本文中,我们将探讨CLIP和DINOv2的优势和它们直接微妙的差别。我们的目标是发现哪些模型在图像相似任务中真正表现出色。
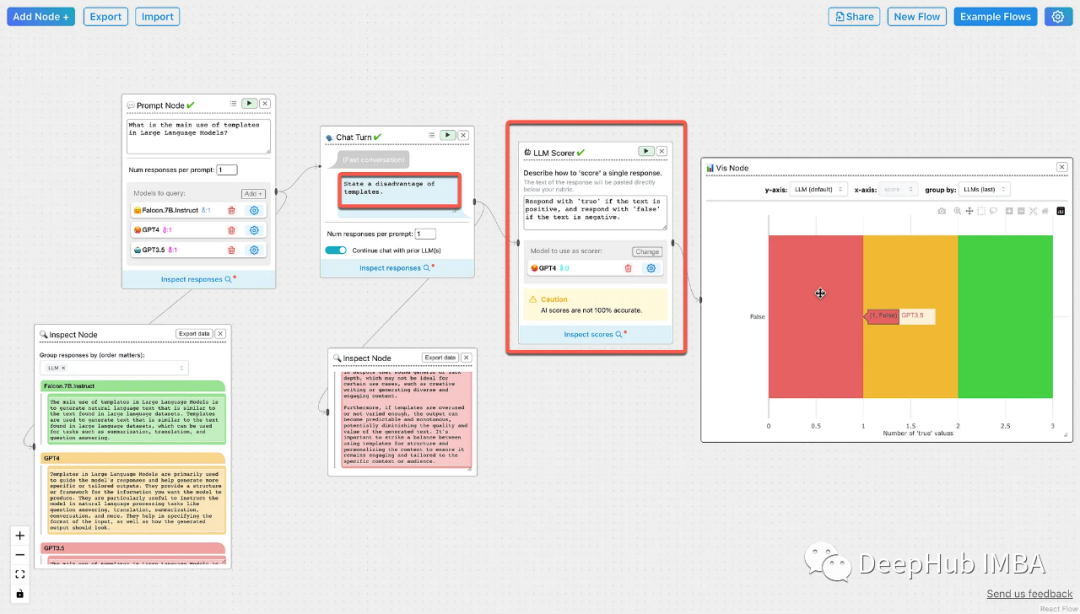
ChainForge:衡量Prompt性能和模型稳健性的GUI工具包
ChainForge是一个用于构建评估逻辑来衡量模型选择,提示模板和执行生成过程的GUI工具包。ChainForge可以安装在本地,也可以从chrome浏览器运行。

用于数据增强的十个Python库
在本文中,我们将介绍数据增强的十个Python库,并为每个库提供代码片段和解释。
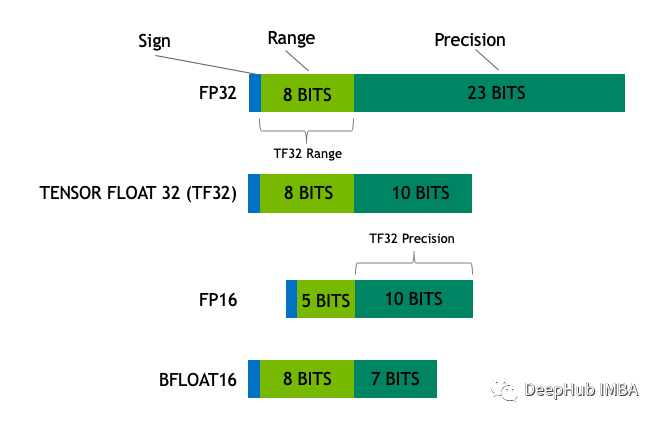
16,8和4位浮点数是如何工作的
在本文中,我们将介绍最流行的浮点格式,创建一个简单的神经网络,并了解它是如何工作的。

使用ExLlamaV2在消费级GPU上运行Llama2 70B
在本文中,我将展示如何使用ExLlamaV2以混合精度量化模型。我们将看到如何将Llama 2 70b量化到低于3位的平均精度。
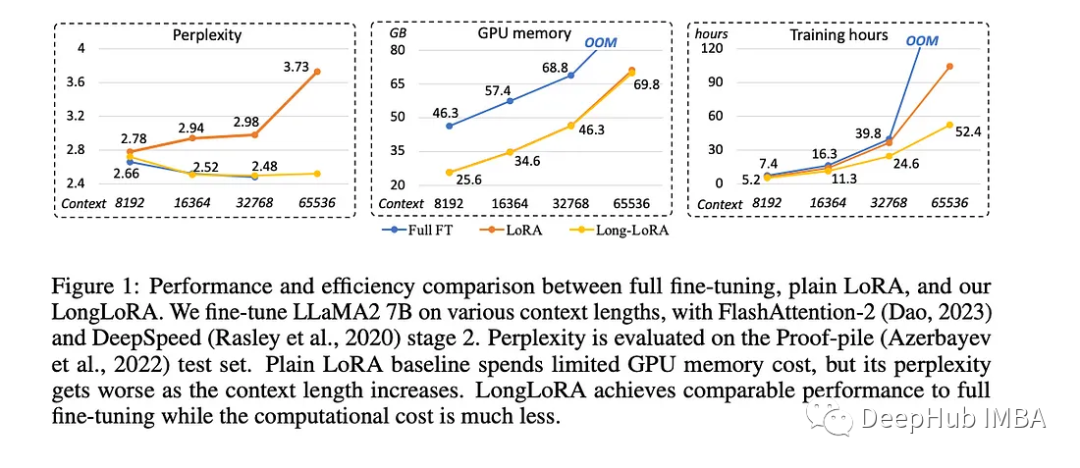
LongLoRA:不需要大量计算资源的情况下增强了预训练语言模型的上下文能力
麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上下文能力。
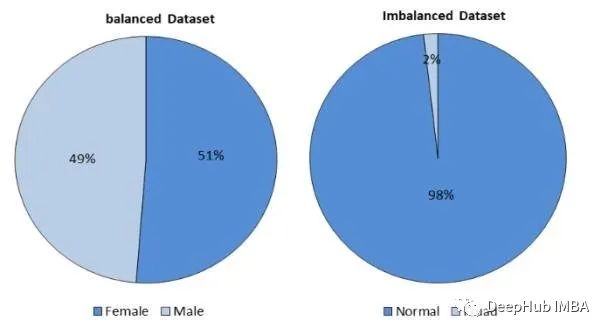
处理不平衡数据的十大Python库
在本文中,我们将介绍用于处理机器学习中不平衡数据的十大Python库,并为每个库提供代码片段和解释。
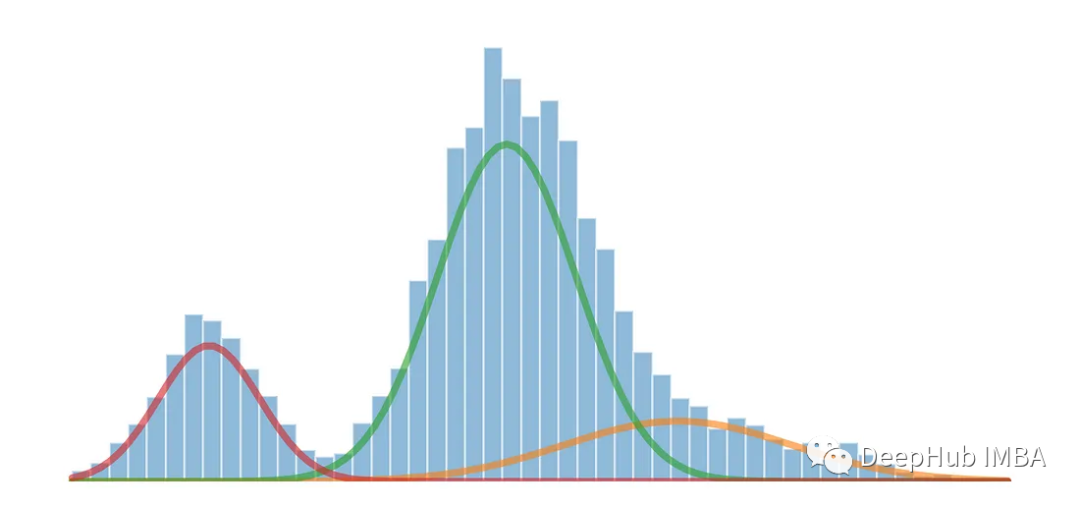
使用高斯混合模型拆分多模态分布
本文介绍如何使用高斯混合模型将一维多模态分布拆分为多个分布。
9月人工智能论文和项目推荐
因为LLM的火爆,所以最近的论文都是和LLM相关的
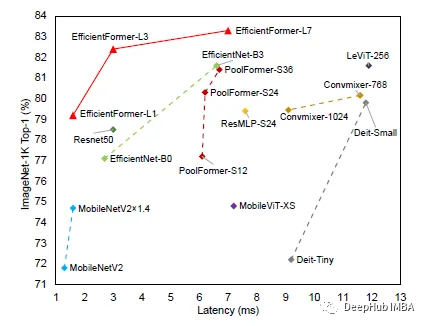
EfficientFormer:高效低延迟的Vision Transformers
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。
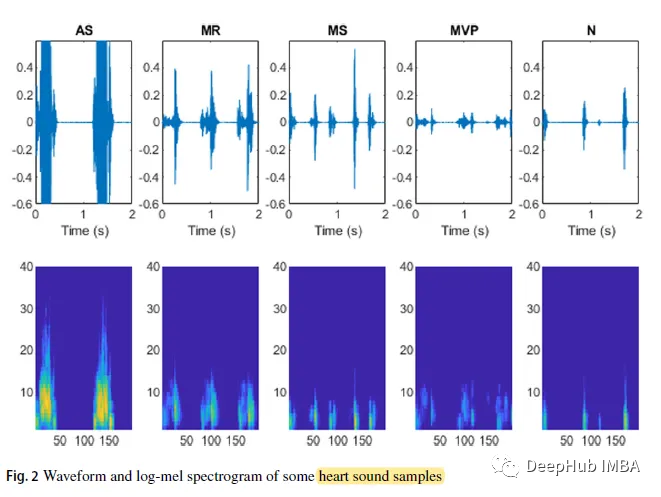
基于对数谱图的深度学习心音分类
这是一篇很有意思的论文,他基于心音信号的对数谱图,提出了两种心率音分类模型,我们都知道:频谱图在语音识别上是广泛应用的,这篇论文将心音信号作为语音信号处理,并且得到了很好的效果。

快速找到离群值的三种方法
本文将介绍3个在数据集中查找离群值的Python方法
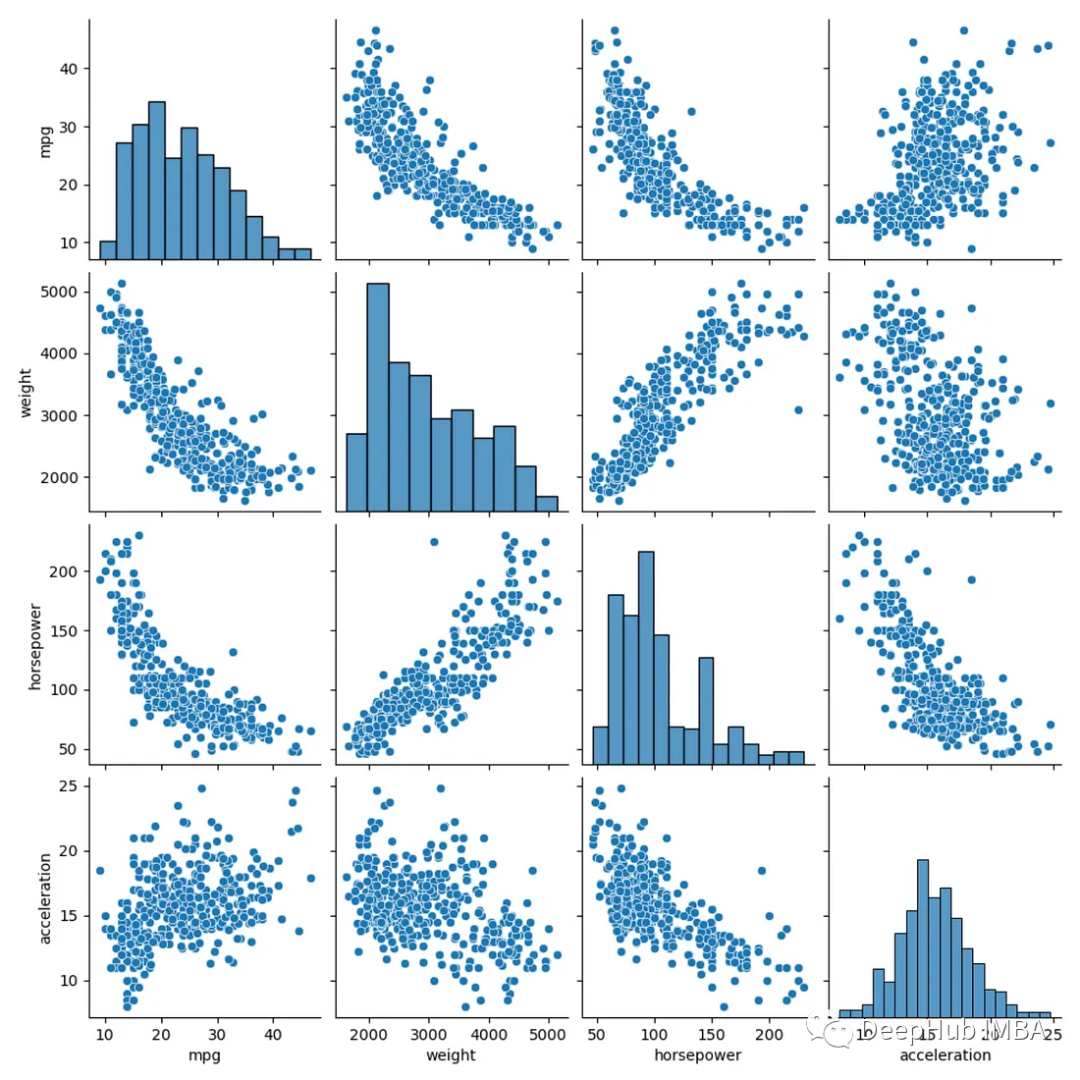
在Python中创建相关系数矩阵的6种方法
相关系数矩阵(Correlation matrix)是数据分析的基本工具。它们让我们了解不同的变量是如何相互关联的。在Python中,有很多个方法可以计算相关系数矩阵,今天我们来对这些方法进行一个总结

使用QLoRA对Llama 2进行微调的详细笔记
本文是一个良好的开端,因为可以把我们在这里学到的大部分东西应用到微调任何LLM的任务中。