
不到两年的时间ViT 已经彻底改变了计算机视觉领域,利用transformers 强大的自注意机制来替代卷积,最近诸如 MLP-Mixer 和通过精心设计的卷积神经网络 (CNN) 等方法也已经实现了与 ViT 相当的性能。
在新论文 Sequencer: Deep LSTM for Image Classification 中,来自Rikkyo University 和 AnyTech Co., Ltd. 的研究团队检查了不同归纳偏差对计算机视觉的适用性,并提出了 Sequencer,它是 ViT 的一种架构替代方案,它使用传统的LSTM而不是自注意力层。Sequencer 通过将空间信息与节省内存和节省参数的 LSTM 混合来降低内存成本,并在长序列建模上实现与 ViT 竞争的性能。

Sequencer 架构采用双向 LSTM (BiLSTM) 作为构建块,并受 Hou 等人的 2021 Vision Permutator (ViP) 启发,并行处理垂直轴和水平轴。研究人员引入了两个 BiLSTM,以实现上/下和左/右方向的并行处理,由于序列长度缩短,从而提高了 Sequencer 的准确性和效率,并产生了具有空间意义的感受野。
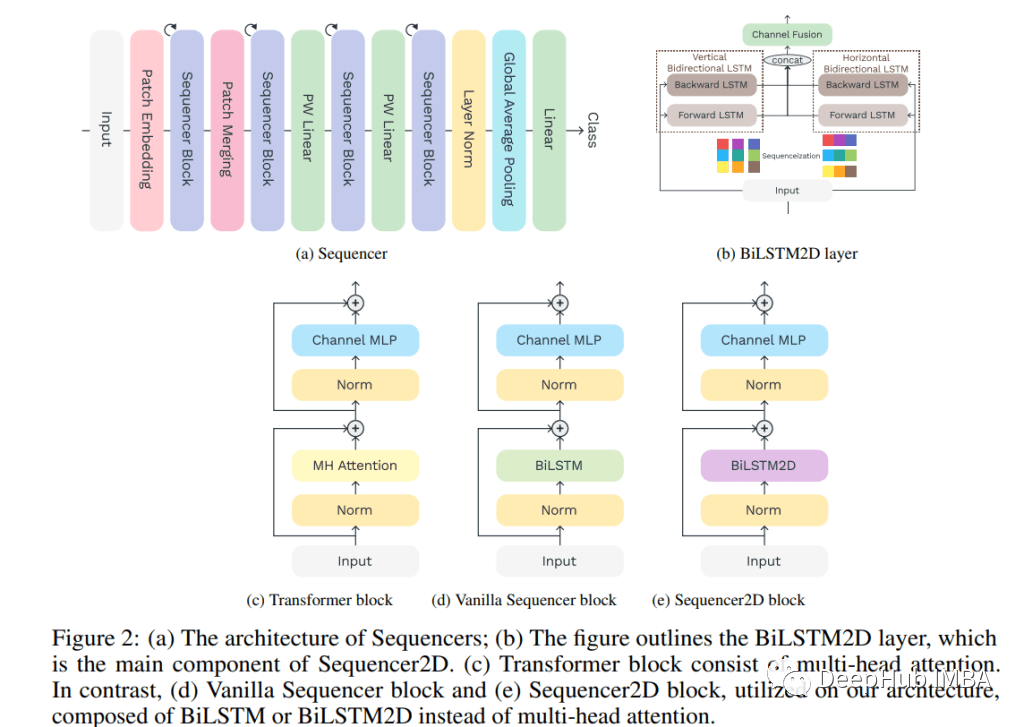
Sequencer 将不重叠的补丁作为输入,并将它们与特征图匹配。Sequencer 模块有两个子组件:1)BiLSTM 层可以全局地混合空间信息记忆2)用于通道混合的多层感知机(MLP)。与现有架构一样,最后一个块的输出通过全局平均池化层发送到线性分类器。
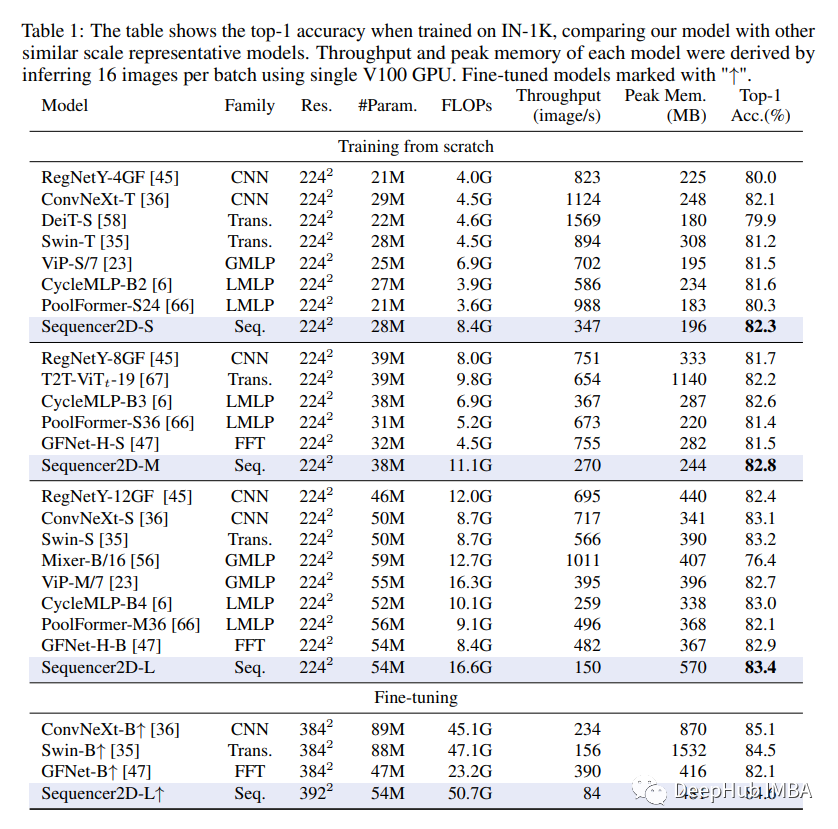
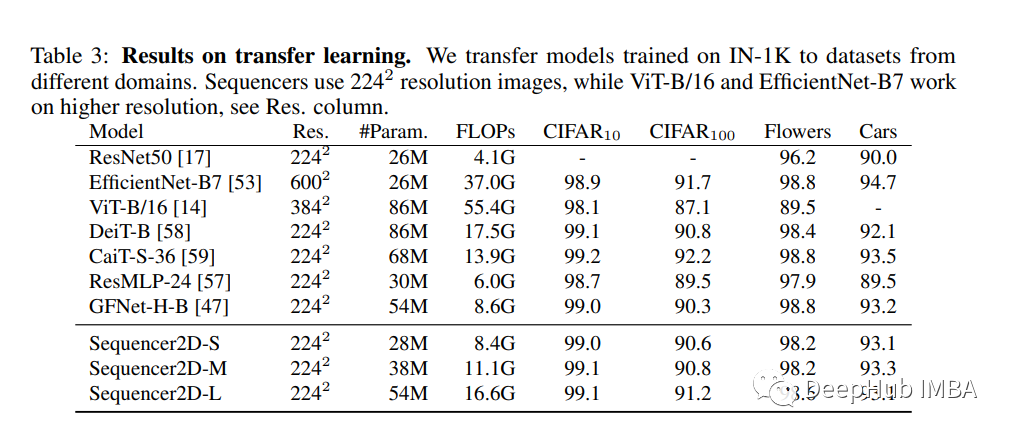
在他们的实践验证中,该团队将提议的 Sequencer 与基于 CNN、ViT 以及基于 MLP 和 FFT 的模型架构与 ImageNet-1K 基准数据集上的可比参数数量进行了比较;并测试了它的迁移学习能力。Sequencer 在评估中取得了令人印象深刻的 84.6% 的 top-1 准确率,分别比 ConvNeXt-S 和 Swin-S 提高了 0.3% 和 0.2%,并且还表现出良好的可迁移性和强大的分辨率适应性。
该团队希望他们的工作能够提供新的见解并加深对各种归纳偏差在计算机视觉中的作用的理解,并激发对这一不断发展的领域中优化架构设计的进一步研究。
论文 Sequencer: Deep LSTM for Image Classification 的地址如下: