
Deephub
更多文章请关注公众号:Deephub-IMBA

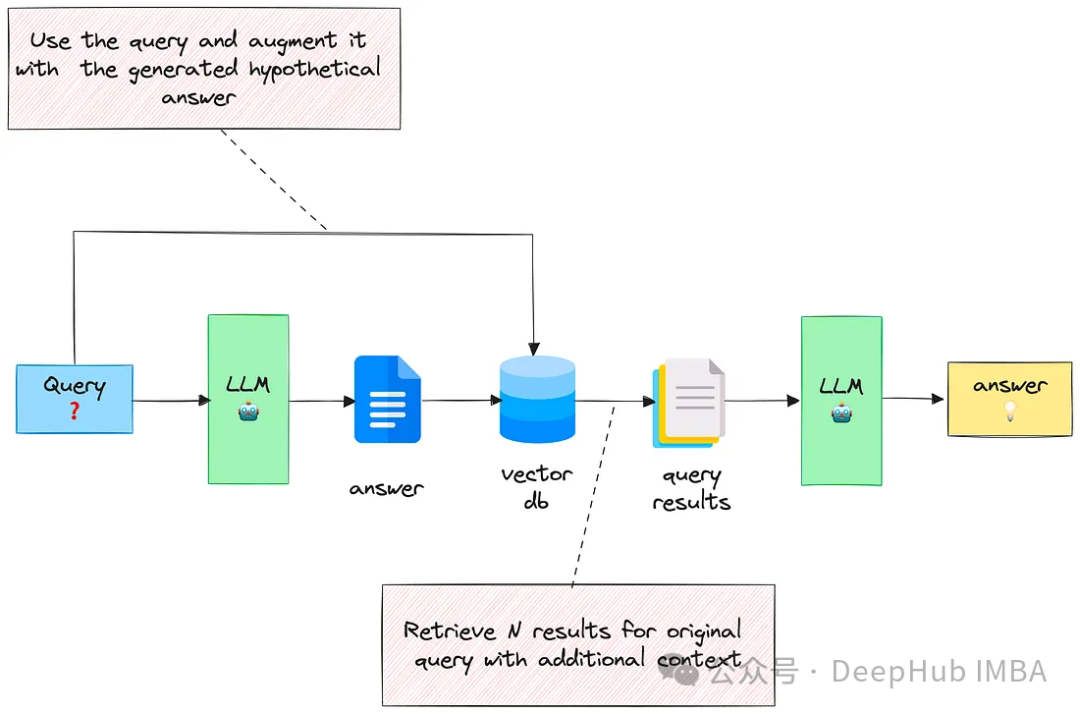
RAG中的3个高级检索技巧
本文将探讨三种有效的技术来增强基于rag的应用程序中的文档检索,通过结合这些技术,可以检索与用户查询密切匹配的更相关的文档,从而生成更好的答案。

4种通过LLM进行文本知识图谱的构建方法对比介绍
本文将介绍和比较使用LLM转换非结构化文本的四种方法,这些方法在不同的场景中都可能会用到。
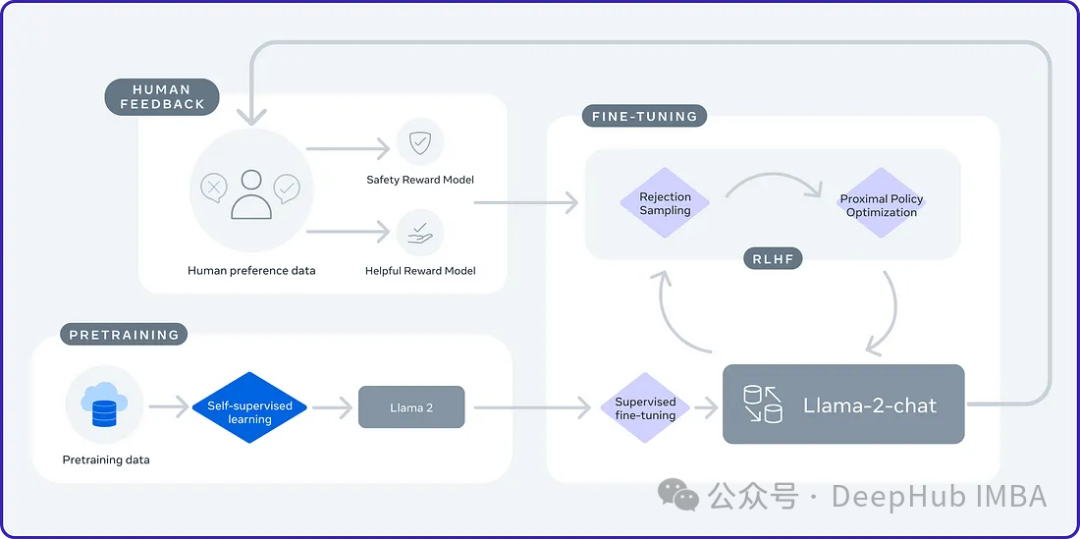
使用SPIN技术对LLM进行自我博弈微调训练
SPIN从AlphaGo Zero和AlphaZero等游戏中成功的自我对弈机制中汲取灵感。它能够使LLM参与自我游戏的能力。
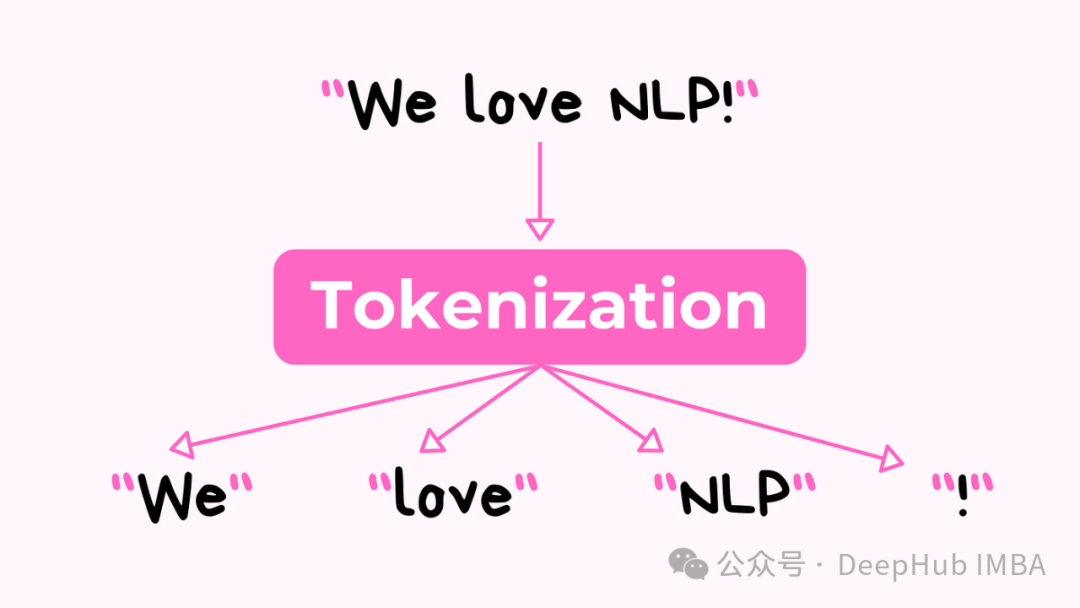
Tokenization 指南:字节对编码,WordPiece等方法Python代码详解
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
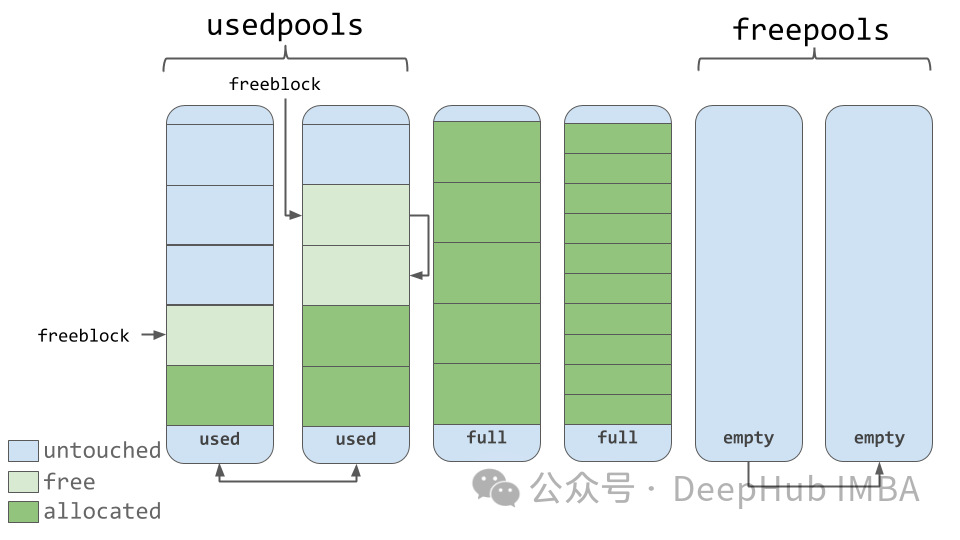
提高代码效率的6个Python内存优化技巧
有许多方法可以显著优化Python程序的内存使用,这些方法可能在实际应用中并没有人注意,所以本文将重点介绍Python的内置机制,掌握它们将大大提高Python编程技能。
RoSA: 一种新的大模型参数高效微调方法
随着语言模型不断扩展到前所未有的规模,对下游任务的所有参数进行微调变得非常昂贵,PEFT方法已成为自然语言处理领域的研究热点。PEFT方法将微调限制在一小部分参数中,以很小的计算成本实现自然语言理解任务的最先进性能。
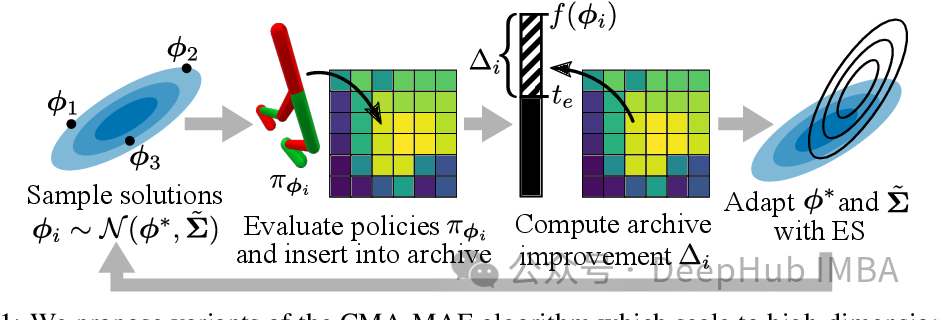
基于协方差矩阵自适应演化策略(CMA-ES)的高效特征选择
特征选择是指从原始特征集中选择一部分特征,以提高模型性能、减少计算开销或改善模型的解释性。
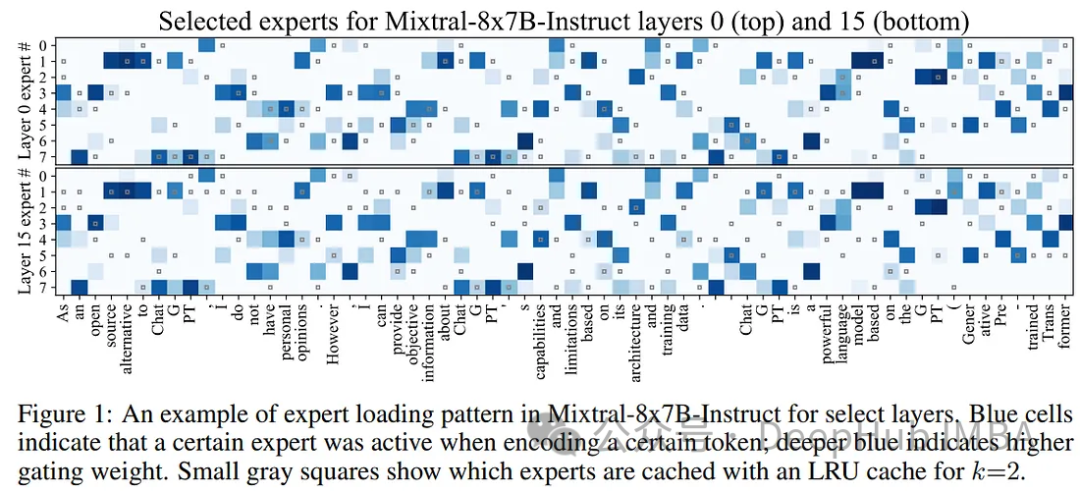
使用Mixtral-offloading在消费级硬件上运行Mixtral-8x7B
在本文中,将解释Mixtral-offloading的工作过程,使用这个框架可以节省内存并保持良好的推理速度,我们将看到如何在消费者硬件上运行Mixtral-8x7B,并对其推理速度进行基准测试。

在Colab上测试Mamba
本文整理了一个能够在Colab上完整运行Mamba代码,代码中还使用了Mamba官方的3B模型来进行实际运行测试。
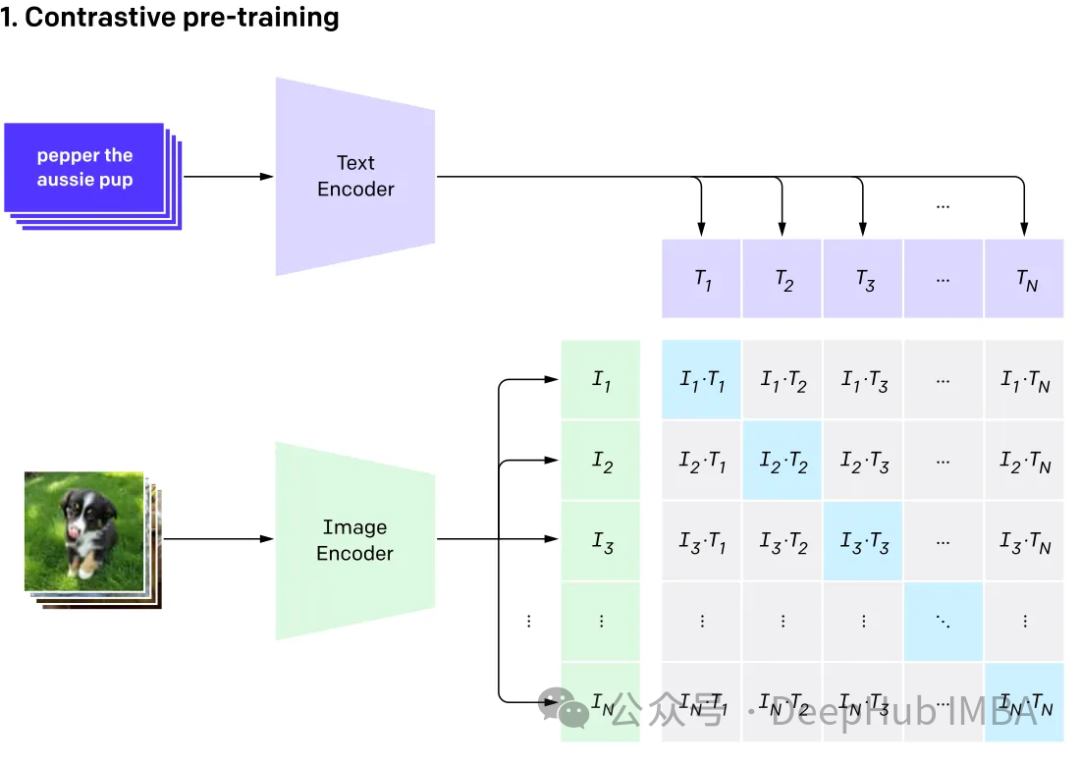
使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。
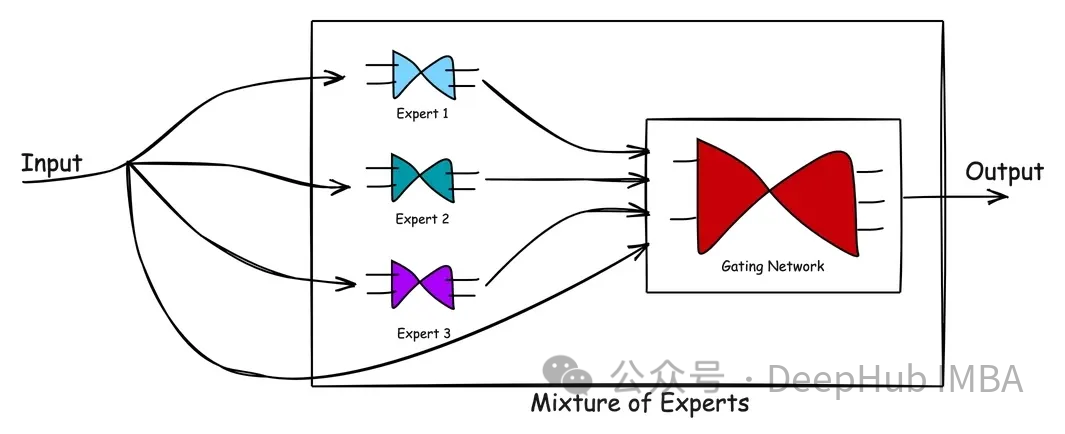
使用PyTorch实现混合专家(MoE)模型
在本文中,我将使用Pytorch来实现一个MoE模型。在具体代码之前,我们先简单介绍混合专家的体系结构。

挑战Transformer的新架构Mamba解析以及Pytorch复现
今天我们来详细研究这篇论文“Mamba:具有选择性状态空间的线性时间序列建模”
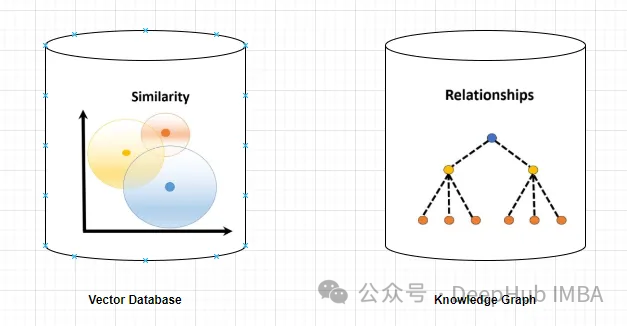
使用知识图谱提高RAG的能力,减少大模型幻觉
在使用大型语言模型(llm)时,幻觉是一个常见的问题。LLM生成流畅连贯的文本,但往往生成不准确或不一致的信息。防止LLM产生幻觉的方法之一是使用提供事实信息的外部知识来源,如数据库或知识图谱。
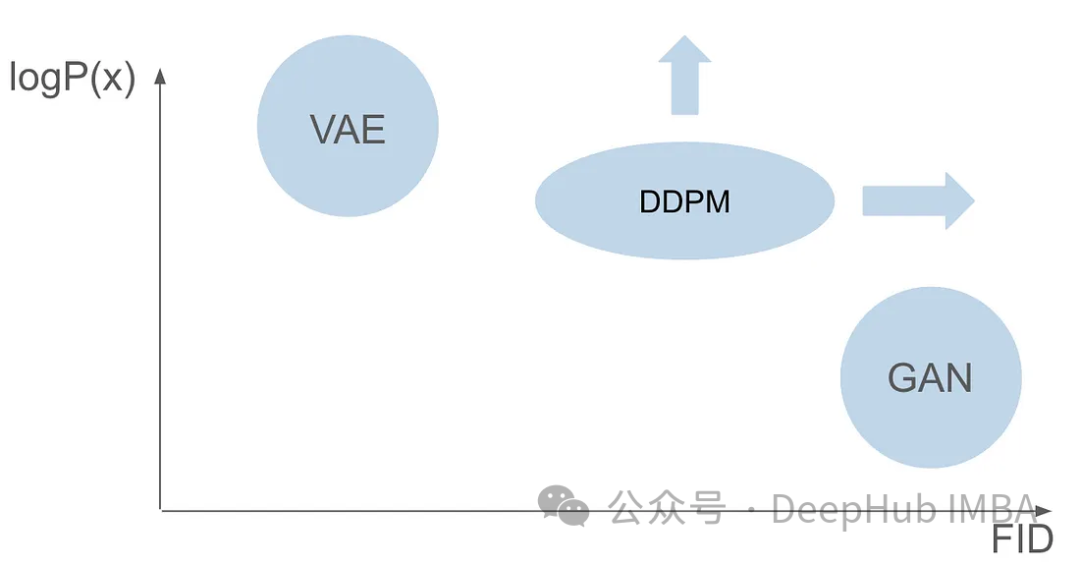
使用PyTorch实现去噪扩散模型
在本文中,我们将深入研究DDPM的复杂性,涵盖其训练过程,包括正向和逆向过程,并探索如何执行采样。在整个探索过程中,我们将使用PyTorch从头开始构建DDPM,并完成其完整的训练。

Python 中的==操作符 和 is关键字
==操作符和is关键字,它们的用途不同,但由于它们有时可以达到相同的目的,所以经常会被混淆。

4种SVM主要核函数及相关参数的比较
本文将用数据可视化的方法解释4种支持向量机核函数和参数的区别

使用pytorch构建图卷积网络预测化学分子性质
在本文中,我们将通过化学的视角探索图卷积网络,我们将尝试将网络的特征与自然科学中的传统模型进行比较,并思考为什么它的工作效果要比传统的方法好。
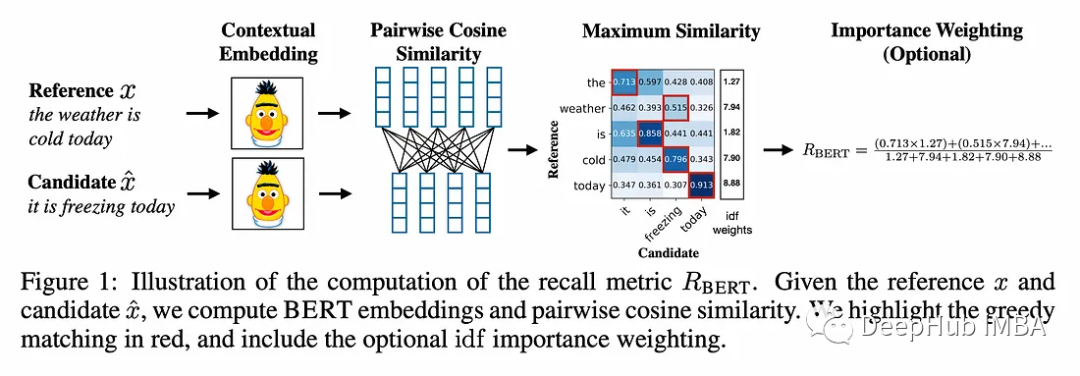
如何避免LLM的“幻觉”(Hallucination)
生成式大语言模型(LLM)可以针对各种用户的 prompt 生成高度流畅的回复。然而,大模型倾向于产生幻觉或做出非事实陈述,这可能会损害用户的信任。
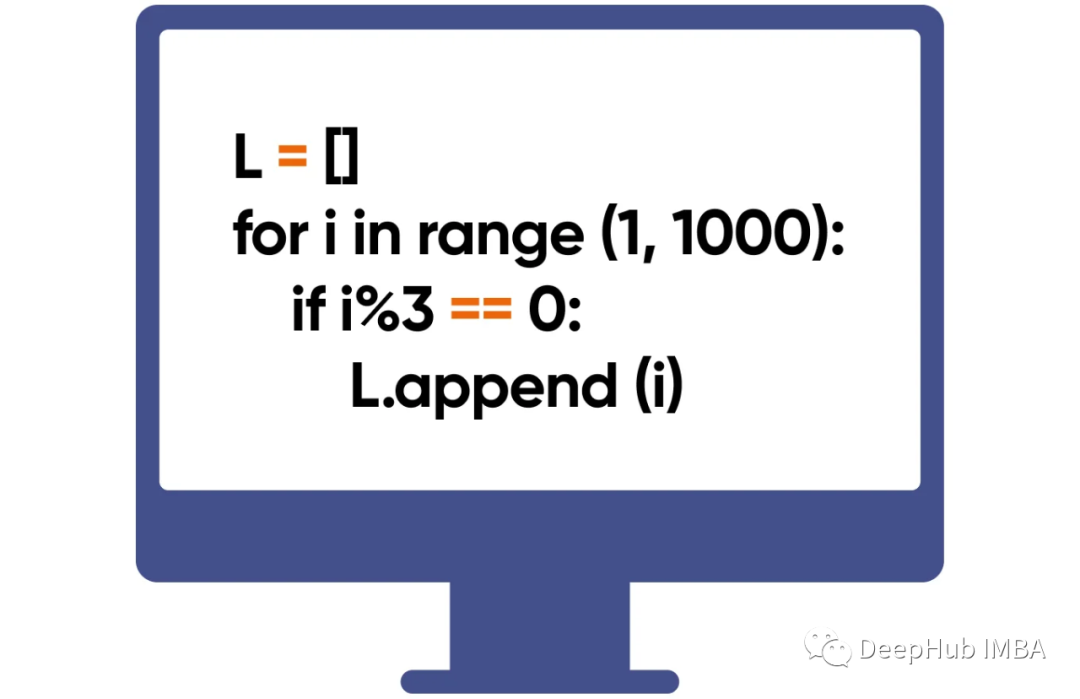
加速Python循环的12种方法,最高可以提速900倍
在本文中,我将介绍一些简单的方法,可以将Python for循环的速度提高1.3到900倍。