
在本文中,将演示一些不常见,但是却非常有用的 Pandas 函数。
创建一个示例 DataFrame 。
import numpy as np
import pandas as pd
df = pd.DataFrame({
"date": pd.date_range(start="2021-11-20", periods=100, freq="D"),
"class": ["A","B","C","D"] * 25,
"amount": np.random.randint(10, 100, size=100)})
df.head()
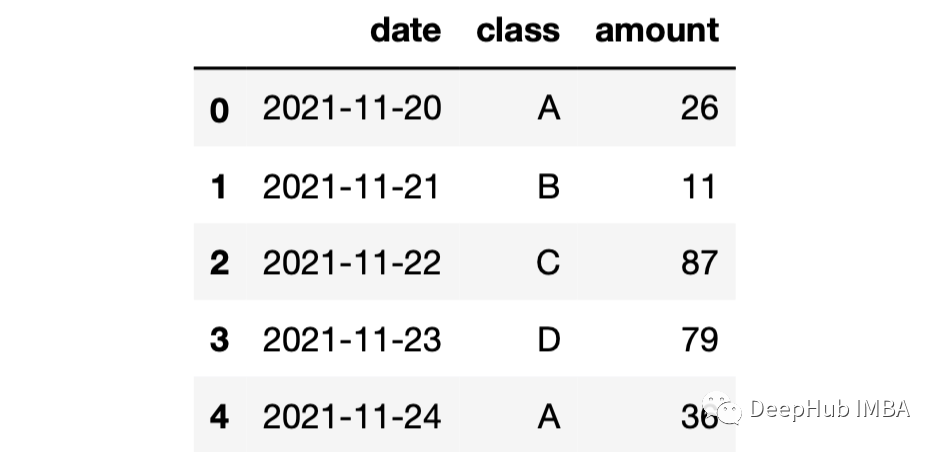
我们创建有一个 3 列 100 行的 DataFrame。date 列包含 100 个连续日期,class 列包含 4 个以对象数据类型存储的不同值,amount 列包含 10 到 100 之间的随机整数。
1、To_period
在 Pandas 中,操 to_period 函数允许将日期转换为特定的时间间隔。使用该方法可以获取具有许多不同间隔或周期的日期,例如日、周、月、季度等。
比如针对于时间类型的列,month 方法只返回在许多情况下没有用处的月份的数值,我们无法区分 2020 年 12 月和 2021 年 12 月。但是我们通过使用to_period 函数的参数”M“实现时间序列。
让我们为年月和季度创建新列。
df["month"] = df["date"].dt.to_period("M")
df["quarter"] = df["date"].dt.to_period("Q")
df.head()
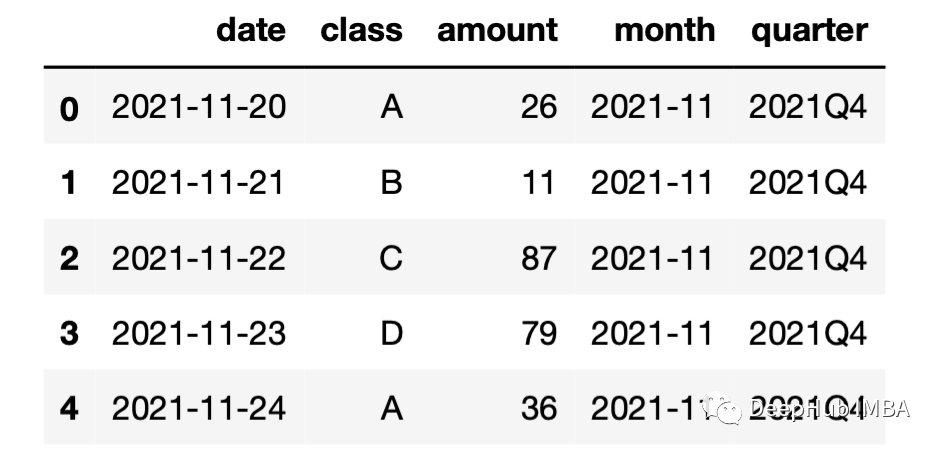
还可以查看 DataFrame 中不同的年月和季度值。
df["month"].value_counts()
# output
2021-12 31
2022-01 31
2022-02 27
2021-11 11
Freq: M, Name: month, dtype: int64
--------------------------
df["quarter"].value_counts()
# output
2022Q1 58
2021Q4 42
Freq: Q-DEC, Name: quarter, dtype: int64
2、Cumsum 和 groupby
cumsum 是一个非常有用的 Pandas 函数。它计算列中值的累积和。以下是我们通常的使用方式:
df["cumulative_sum"] = df["amount"].cumsum()
df.head()
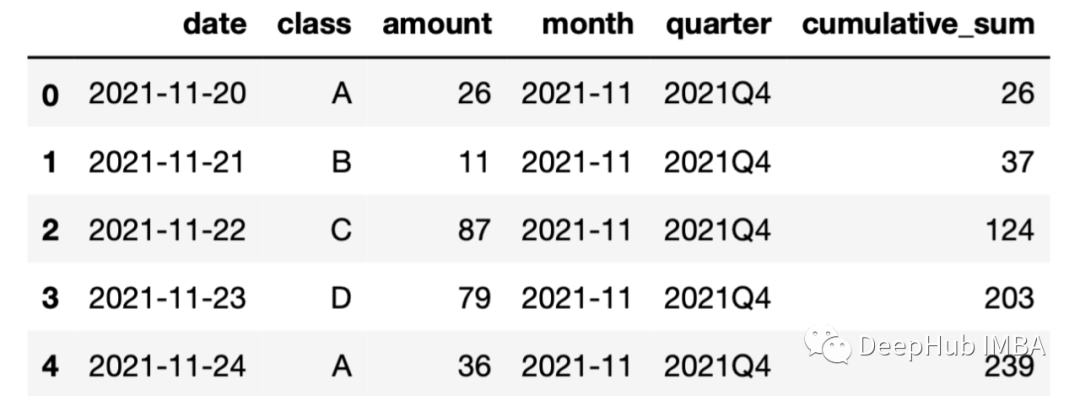
这样就获得了金额列值的累积总和。但是它只是全部的总和没有考虑分类。在某些情况下,我们可能需要分别计算不同类别的累积和。
Pandas中我们只需要按类列对行进行分组,然后应用 cumsum 函数。
df["class_cum_sum"] = df.groupby("class")["amount"].cumsum()
让我们查看 A 类的结果。
df[df["class"]=="A"].head()
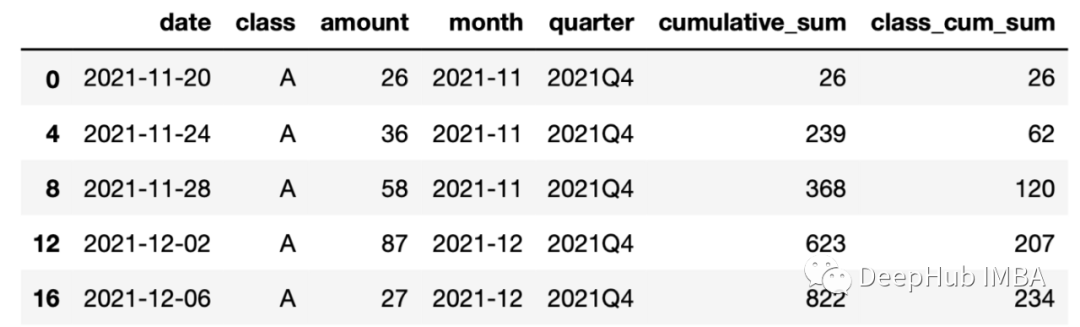
类·的累积总和列包含为每个类单独计算的累积值总和。
3、Category数据类型
我们经常需要处理具有有限且固定数量的值的分类数据。例如在我们的 DataFrame 中,”分类“列具有 4 个不同值的分类变量:A、B、C、D。
默认情况下,该列的数据类型为object。
df.dtypes
# output
date datetime64[ns]
class object
amount int64
month period[M]
quarter period[Q-DEC]
cumulative_sum int64
class_cum_sum int64
Pandas 还有一个“Category”数据类型,它比object数据类型消耗更少的内存。因此最好尽可能使用category数据类型。
df["class_category"] = df["class"].astype("category")
df.dtypes
# output
date datetime64[ns]
class object
amount int64
month period[M]
quarter period[Q-DEC]
cumulative_sum int64
class_cum_sum int64
class_category category
dtype: object
现在可以比较 class 和 class_category 列的内存消耗。
df.memory_usage()
# output
Index 128
date 800
class 800
amount 800
month 800
quarter 800
cumulative_sum 800
class_cum_sum 800
class_category 304
dtype: int64
class_category 列消耗的内存不到 class 列的一半。差异是 496 字节,虽然并不多。但是当我们使用大型数据集时,这样差异就会被放大,这样就变成了节省大量的空间。
作者:Soner Yıldırım