
Deephub
更多文章请关注公众号:Deephub-IMBA
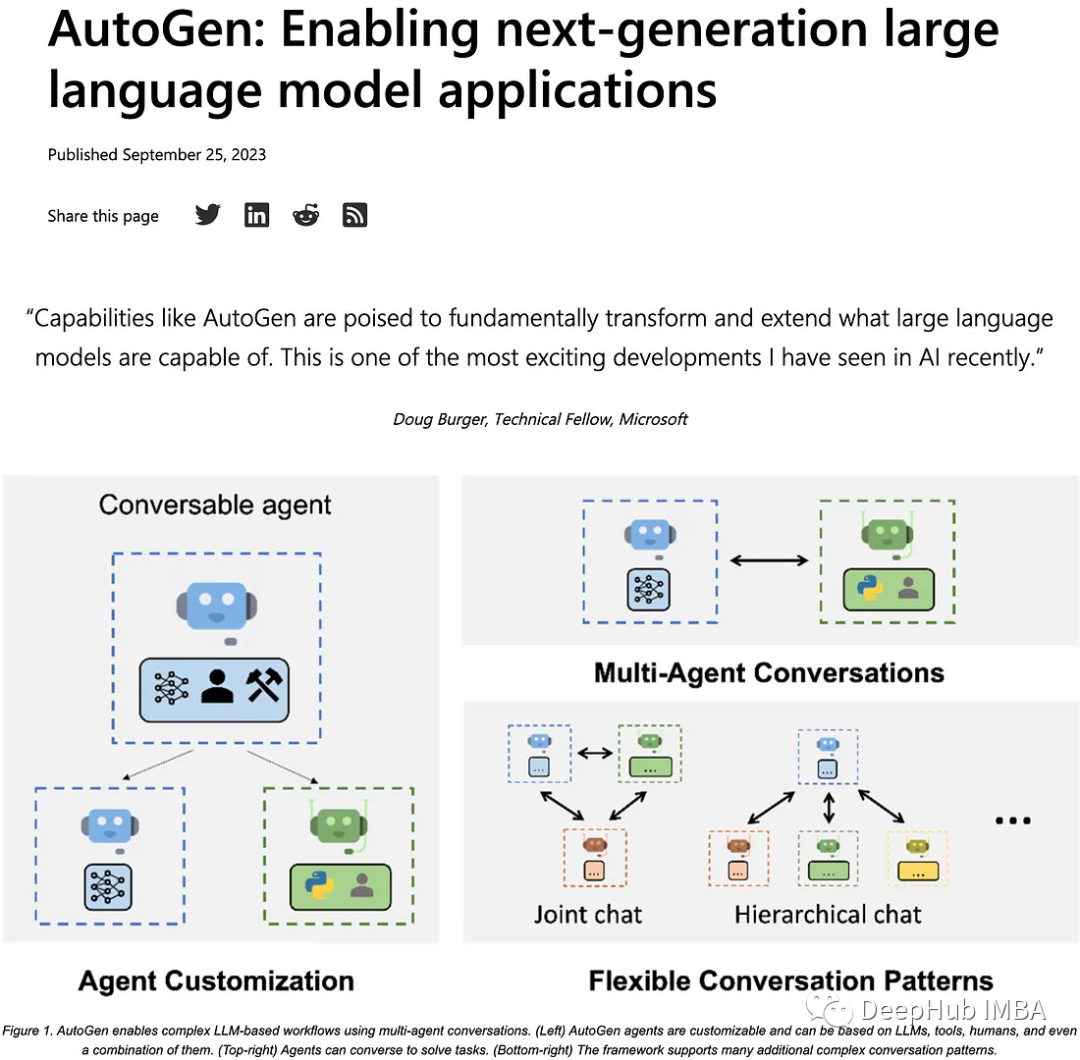
AutoGen完整教程和加载本地LLM示例
Autogen是一个卓越的人工智能系统,它可以创建多个人工智能代理,这些代理能够协作完成任务,包括自动生成代码,并有效地执行任务。
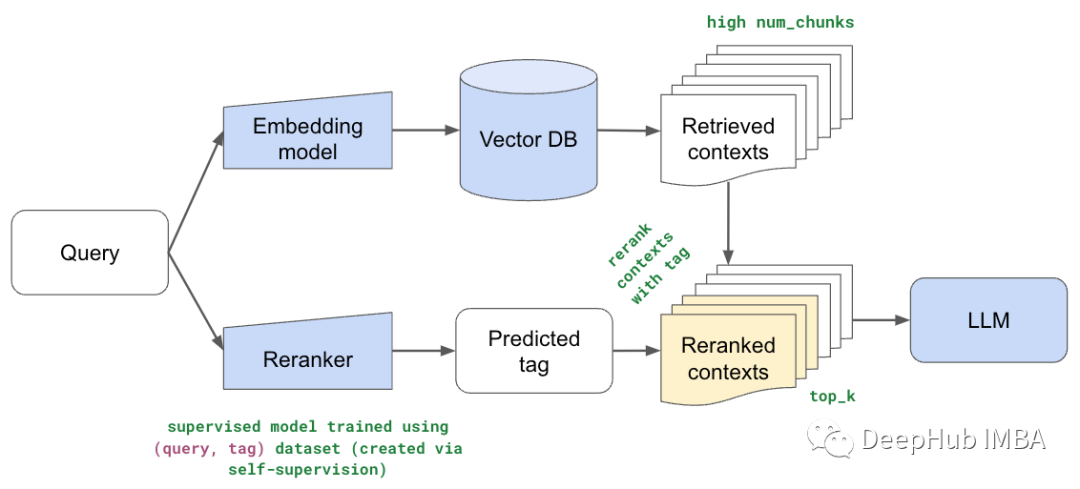
使用Llama index构建多代理 RAG
检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用的上下文,以产生基于事实的输出。
使用Panda-Gym的机器臂模拟进行Deep Q-learning强化学习
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动导致预期结果而受到惩罚。随着时间的推移,代理学会采取行动,使其预期回报最大化。
使用FastAPI部署Ultralytics YOLOv5模型
在本文中,我们将介绍如何使用FastAPI的集成YOLOv5,这样我们可以将YOLOv5做为API对外提供服务。
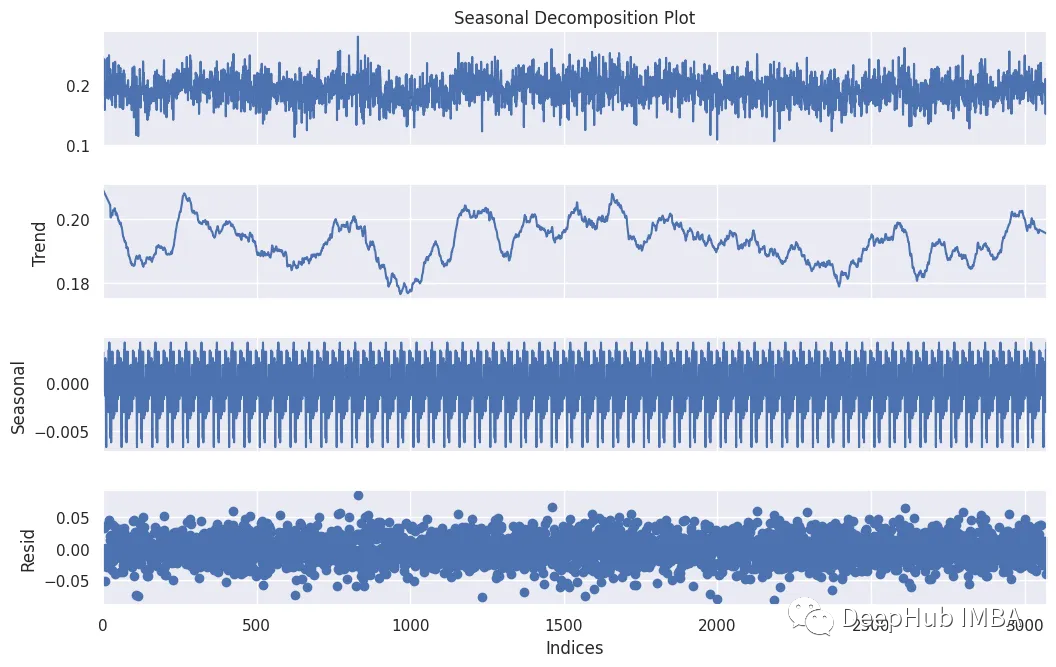
Python时间序列分析库介绍:statsmodels、tslearn、tssearch、tsfresh
在本文中,我们将介绍四个主要的Python库——statmodels、tslearn、tssearch和tsfresh——每个库都针对时间序列分析的不同方面进行了定制
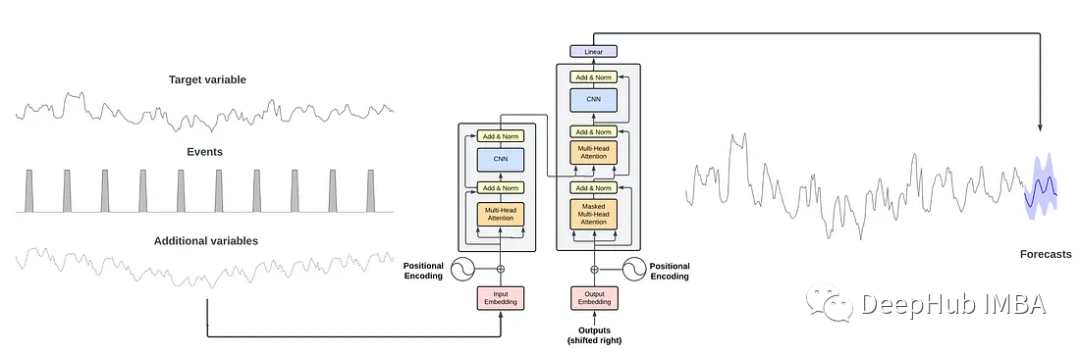
TimeGPT:时间序列预测的第一个基础模型
在本文中,我们将探索TimeGPT背后的体系结构以及如何训练模型。然后,我们将其应用于预测项目中,以评估其与其他最先进的方法(如N-BEATS, N-HiTS和PatchTST)的性能。

Table-GPT:让大语言模型理解表格数据
在这篇文章中,我们将介绍微软发表的一篇研究论文,“Table-GPT: Table- tuning GPT for Diverse Table Tasks”,研究人员介绍了Table-GPT
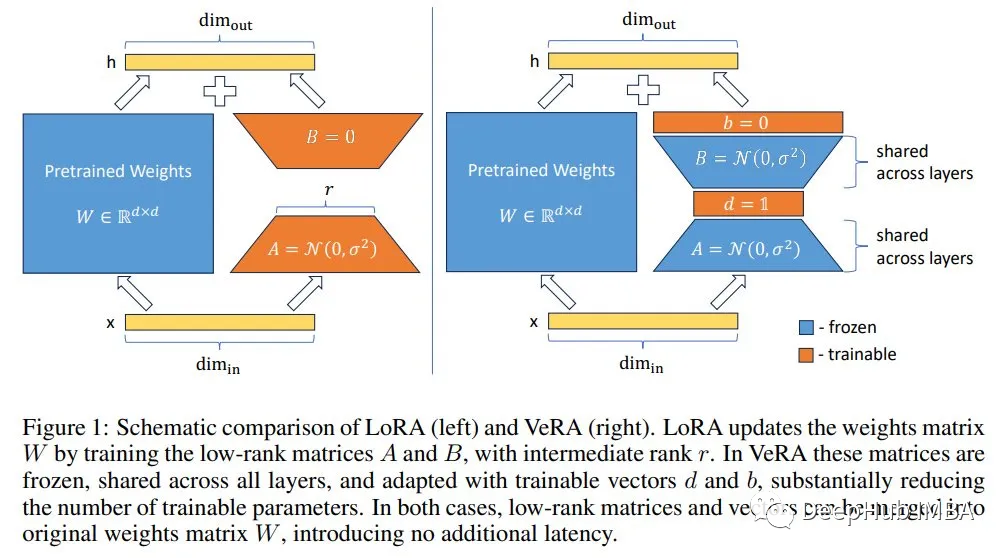
VeRA: 性能相当,但参数却比LoRA少10倍
VeRA在LoRA冻结的低秩张量上添加可训练向量,只训练添加的向量。论文中显示的大多数实验中,VeRA训练的参数比原始LoRA少10倍。
LlamaIndex使用指南
LlamaIndex是一个方便的工具,它充当自定义数据和大型语言模型(llm)(如GPT-4)之间的桥梁,大型语言模型模型功能强大,能够理解类似人类的文本
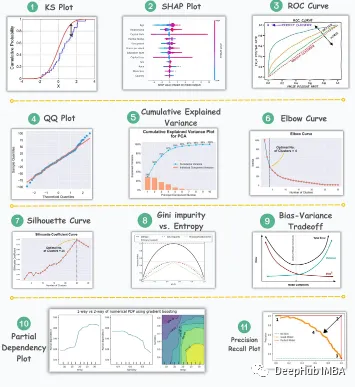
数据分析和机器学习的11个高级可视化图表介绍
我们将介绍11个最重要和必须知道的图表,这些图表有助于揭示数据中的信息,使复杂数据更加可理解和有意义。
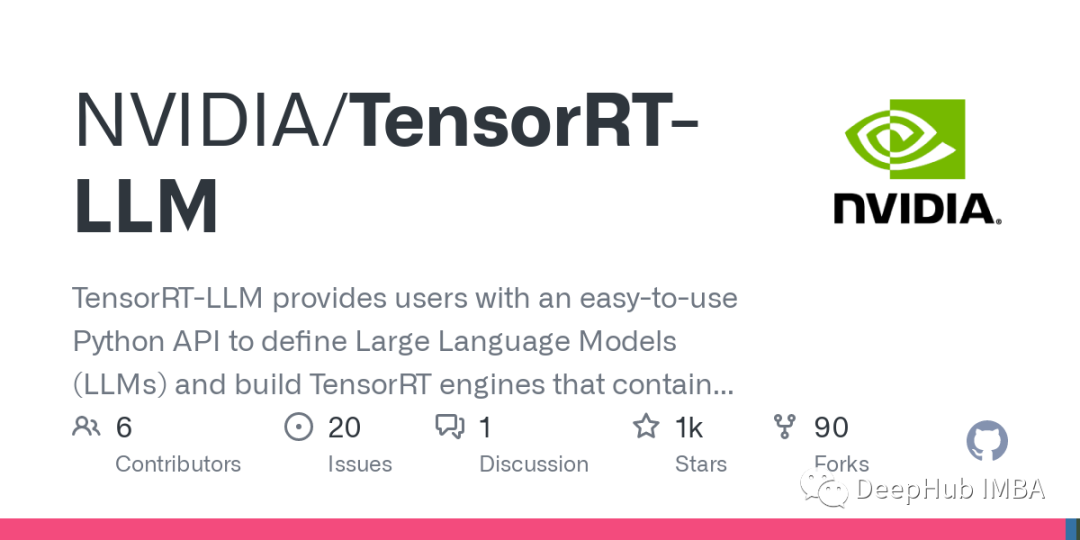
使用TensorRT-LLM进行高性能推理
TensorRT-LLM是在TensorRT基础上针对大模型进一步优化的加速推理库,它号称可以增加4倍的推理速度。
使用pytorch实现高斯混合模型分类器
本文是一个利用Pytorch构建高斯混合模型分类器的尝试。我们将从头开始构建高斯混合模型(GMM)。这样可以对高斯混合模型有一个最基本的理解,本文不会涉及数学,因为我们在以前的文章中进行过很详细的介绍。

使用Pytorch Geometric 进行链接预测代码示例
PyTorch Geometric (PyG)是构建图神经网络模型和实验各种图卷积的主要工具。在本文中我们将通过链接预测来对其进行介绍。
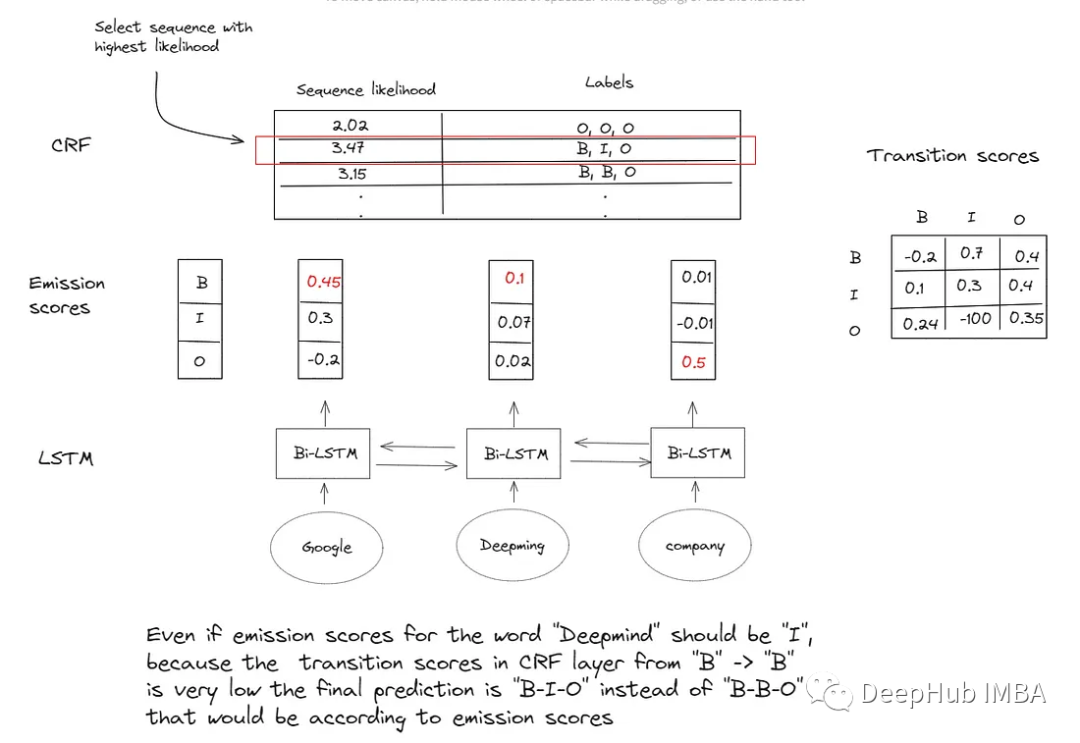
LSTM-CRF模型详解和Pytorch代码实现
本文中crf的实现并不是最有效的实现,也缺乏批处理功能,但是它相对容易阅读和理解,因为本文的目的是让我们了解crf的内部工作,所以它非常适合我们。
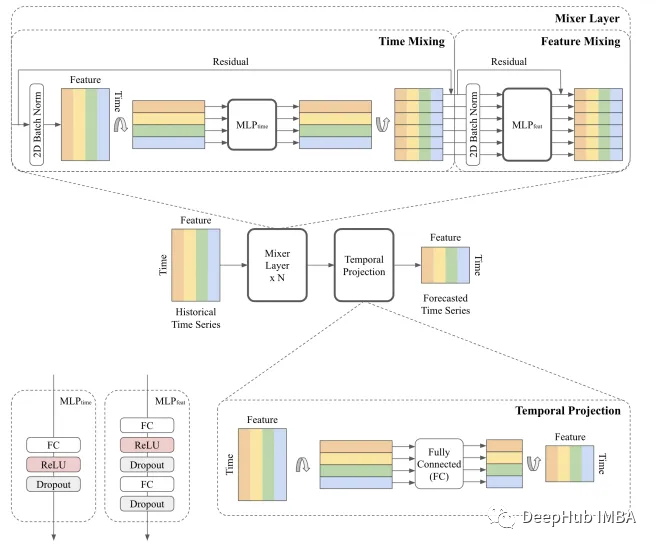
TSMixer:谷歌发布的用于时间序列预测的全新全mlp架构
这是谷歌在9月最近发布的一种新的架构 TSMixer: An all-MLP architecture for time series forecasting
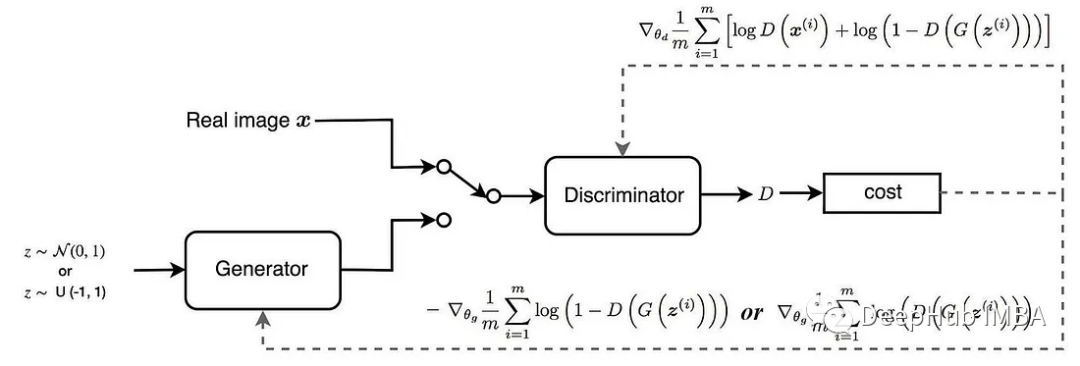
使用Pytorch实现频谱归一化生成对抗网络(SN-GAN)
自从扩散模型发布以来,GAN的关注度和论文是越来越少了,但是它们里面的一些思路还是值得我们了解和学习。所以本文我们来使用Pytorch 来实现SN-GAN
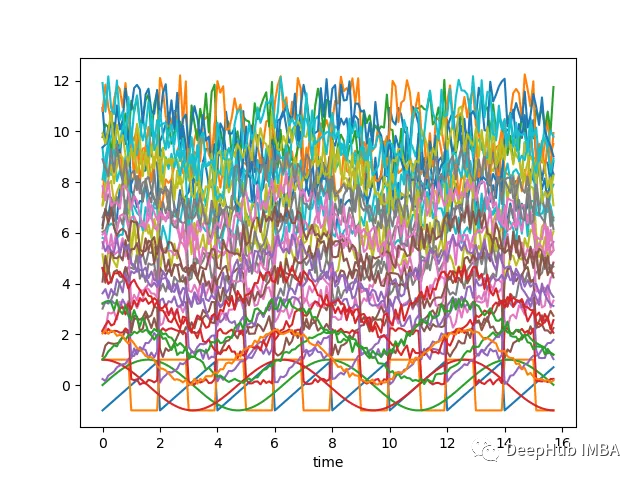
使用轮廓分数提升时间序列聚类的表现
我们将使用轮廓分数和一些距离指标来执行时间序列聚类实验,并且进行可视化
9月大型语言模型研究论文总结
这些论文涵盖了一系列语言模型的主题,从模型优化和缩放到推理、基准测试和增强性能。最后部分讨论了有关安全训练并确保其行为保持有益的论文。
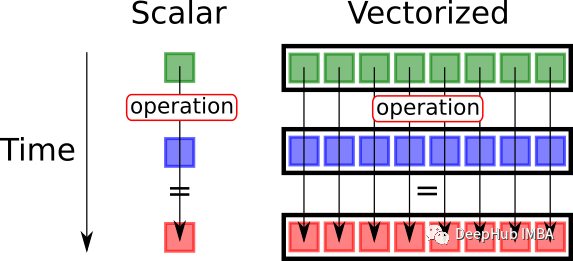
向量化操作简介和Pandas、Numpy示例
在本文中,我们将探讨什么是向量化,以及它如何简化数据分析任务。
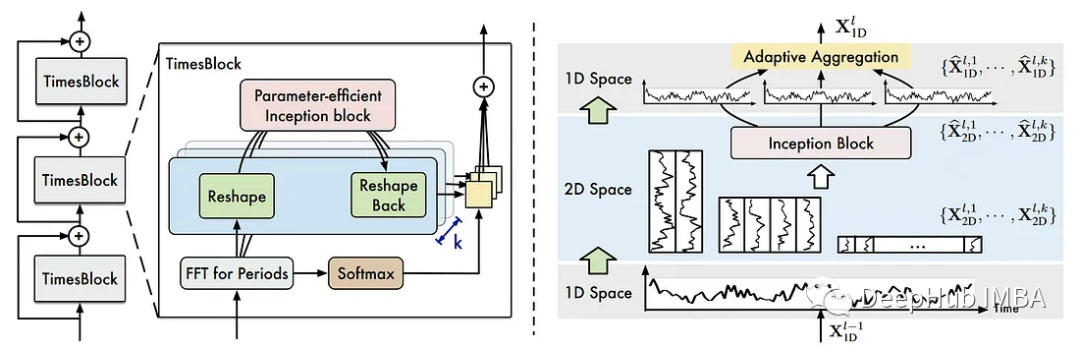
TimesNet:时间序列预测的最新模型
在本文中,我们将探讨TimesNet的架构和内部工作原理。然后将该模型应用于预测任务,与N-BEATS和N-HiTS进行对比。