1行Python代码实现:PDF转Word。
大家好,今天给大家介绍 python-office 近期更新的功能之一:1行代码,实现PDF转Word。真的很实用!安装很简单,在有python环境的电脑上,只需要执行下面这一行命令。安装2. PDF转Word直接上代码!代码...
OpenCV图像处理入门
OpenCV相关知识继续讲解
PyTorch 深度学习入门
深度学习是机器学习的一个分支,其中编写了模仿人脑功能的算法。深度学习中最常用的库是 Tensorflow 和 PyTorch。由于有各种可用的深度学习框架,人们可能想知道何时使用 PyTorch。以下是人们可能更喜欢将 Pytorch 用于特定任务的原因。Pytorch 是一个开源深度学习框架,带有
再议LaMDA,它真的初具思想吗?
昨天,我关注的一个新闻,并仔细的阅读了原文,并对其进行了解读(因怀疑对话系统变成人而被带薪休假,我亲自看了看。)。今天看到很多讨论后,想从技术的角度谈一谈,它现在到底处于什么水平的AI。当然,很多人的结论就是,现在的LaMDA距离真正的AI还很远。而且作为工程师,应该多和人类接触,而不是和机器打交道
黑洞优化算法(Matlab实现)
目录1 概述1.1 黑洞算法1.2黑洞搜索优化算法1.3黑洞搜索算法的实现过程 2 Matlab代码实现2.1 主函数2.2 目标函数 2.3 黑洞优化算法 3 结果展现 应用的领域很多。根据黑洞现象原理首次提出BH 算法,它在传统PSO基础上引入了新的机制,有效地提高了收敛速度并防止了陷入局部

数据科学的面试的一些基本问题总结
在这篇文章中,将介绍如何为成功的面试做准备的,以及可以帮助我们面试的一些资源。
2022/6/13
The Reforce Leaning based on Q-learning method, which is used in the interactive control of autos in the one single intersection. Easily speaking, the
Machine Learning with Matminer(附代码)
Machine Learning with Matminer(附代码),Matminer是一个开源的、基于python的软件平台,以促进数据驱动的方法来分析和预测材料的属性。
【机器学习】浅谈正规方程法&梯度下降
【机器学习】浅谈正规方程法&梯度下降数据模型为线性回归模型,方程代价函数。代价函数就是实际数据与数学模型(这里是一元一次方程)所预测的差值,如:蓝线的长度就是代价函数,可以看到代价函数越大拟合效果越差,代价函数越小,拟合效果越好。其中关于 θ1\theta_1θ1 的的代价函数f(θ1)f(\th
时间序列—相关性和滞后性分析_python
本文讲述了两个时间序列(信号)的相关性分析,可以利用相关性分析进行特征筛选。此外本文还讲了怎么判断时间序列的滞后性的方法。
你应该知道的,十二大CNN算法
大家好,我是K同学啊!今天和大家分享一下自年来,涌现出来的那些优秀的图像识别算法模型。⭐️ 简介模型是Yann LeCun教授于1998年在论文《Gradient-based learning applied to document recognition》中提出。它是第一个成功应用于手写数字识别问
用Python生成答题库,辅助完成XX在线平台视频学习的课后考试
随着XX在线视频学习的任务增多,有时刷完视频并不能轻松完成课后考试,本篇文章意在用Python提供解决思路和代码,为顺利通过考试提供可行性方案。
因怀疑对话系统变成人而被带薪休假,我亲自看了看。
今天被一个谷歌的对话系统LaMDA的新闻吸引到了,这个新闻大致是讲,谷歌研究员通过提交自己和AI的对话记录,试图让上司明白AI已经初具人格(即有人的意识)而被带薪休假。我关注的不是他为何被处理,我更希望的是去看看,这个可以令谷歌研究员走火入魔的AI到底达到了什么样的水平了,于是,我亲自去看了它的原版
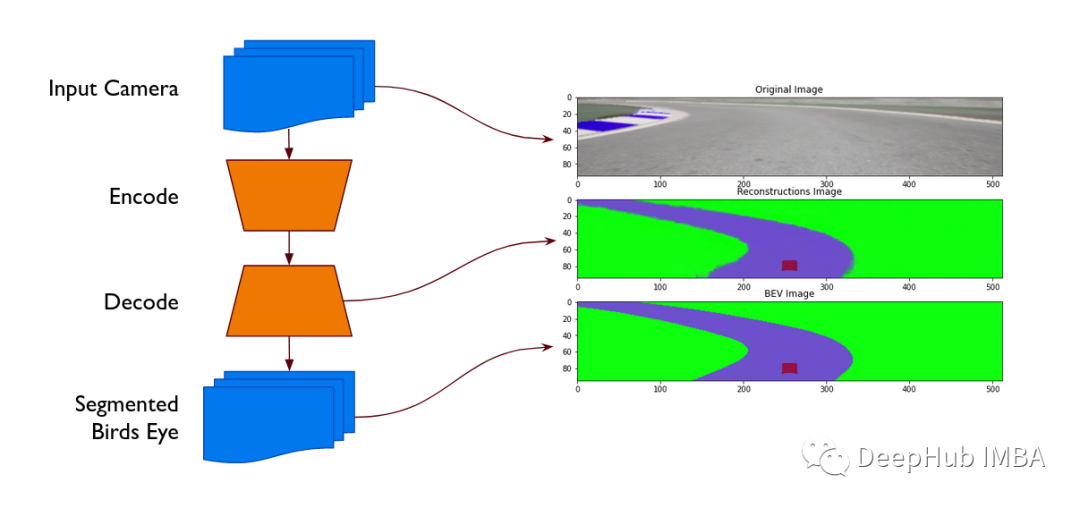
基于自动编码器的赛车视角转换与分割
本文将利用vae将汽车前置视像头的图像转换成分割后的鸟瞰图
Python图像处理
python图像处理
PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测
PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测
【机器学习】梯度下降之数据标准化
吴恩达机器学习笔记在线性回归中,尤其是多变量回归模型,由于各个的数据之间量化纲位不同,如果数据范围分别是是【0~1000,0 ~5】或者【-0.00004 ~ 0.00002,10 ~ 30】, 那么在使用梯度下降算法时,他们的等高线是一个又窄又高的等高线,如下图:因为一个他们量化纲位不同会出现
KMean算法精讲
KMeas算法是一种聚类算法,同时也是一种无监督的算法,即在训练模型时并不需要标签,其主要目的是通过循环迭代,将样本数据分成K类。
浅谈sklearn中的数据预处理
sklearn中的数据预处理
机器学习之数据处理与可视化【鸢尾花数据分类|特征属性比较】
大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的数值表示。大部分情况下,收集得到的数据需要经过处理后才能够为算法所使用。通常情况下,一个数据集当中存在很多种不同的特征,其中一些可能是多余的或者与我们要预测的值无关的,可通过数据处理和可视化进行筛选。特征选择技术的必要性也体



