
前言
在数仓的构建DWD层的时候有些数据需要去转化成拉链表来经行处理所以在今天我会着重讲解拉链表的使用以及在DWB JOIN表的时候进行的优化防止数据倾斜
一.DWD(重点)
- 1-确定业务过程:根据要分析的业务需求文档中,提取出要分析什么主题业务,去上游的业务数据的海量表中,寻找需要的哪些表的哪些字段,能满足。
- 2-声明粒度:后续的数仓的层中,每个层的数据的粒度是细还是粗的。比如DWD粒度是明细类,DWS粒度是分组聚合后的粗的。
- 3-确定维度,4-确定事实:- 在细粒度的层中,比如DWD层,确定哪些是维度表(用户维度表,地区维度表),哪些表是事实表(比如订单明细,交易明细,支付明细)- 在粗粒度的层中,比如DWS层中,一般是聚合之后的结果,确定报表结果的维度字段和指标字段。
- 5-冗余维度- 在细粒度的过程中将DWD层做了优化,优化到了DWB层,将DWD层的维度表的详细的维度字段冗余到DWD层的事实表中,让事实表展现的字段更详细,表更宽,也减少了表的个数
DWD作用
- 从ODS层将表数据抽取出来,
- DWD层和ODS层保持相同粒度
- 作用:- 对数据进行清洗转换的操作, 将清洗转换后的数据导入到DWD层- 标明哪些表是【事实表】,哪些是【维度表】,表名分别打上fact_或dim_前缀
- 生成方式:每个表继承上一层ODS的方式,用【全量覆盖】、或【仅新增】、或【新增及修改】方式生成。其中【新增及修改方式】用拉链表来实现
常见的问题:
常见清洗转换操作主要有什么呢?
1- 清洗掉标记删除的数据
2- 清洗掉为空为null的数据
3- 清洗掉特定业务要求的数据
4- 对日期进行扩宽操作: 比如原有一个字段中含有年月日, 拆解为年字段 月字段 和 日字段
5- 对标记数据转换: 比如原有用 0 1表示男 女 我们直接将其转换为 男 女 或者 将男 女 转换为 0 和 1
6- 对于JSON数据的解析拉宽操作:
比如说:一个content字段中, 存储 {'name':'张三','age':20} 此时通过SQL扩宽为两个字段: name 和 age
现在我们了解DWD的概念和作用以后我们开始引出今天的主角拉链表。
二、拉链表的实现
- 以有的事实表的数据变化为例,比如电商订单,当公司成熟时,一般很猛烈的新增,订单一旦产生就不变。
- 维度表数据的变化则没那么猛,比如用户维度,当公司成熟时,一般很温和的新增,产生后可能会偶尔修改,比如住址,手机号。
- 这就是缓慢的逐渐变化的维度。slowly changing dimension (SCD).
如何处理缓慢渐变维度呢在这里就要用到SCD2又称为拉链表
- 在原有表增加2个字段(start_time, end_time), 通过这两个字段,管理数据的多个历史版本。
- 使用时要where指定某具体时刻,它只会介于1个历史时段中。
- 比如下面where '2012-02-01' >Valid_from and '2012-02-01' < Valid_to 只会筛选出Beijing这条数据。
- 如果数据当前及未来都生效,则ValidTo可以写成9999-99-99或者9999-12-31

在这里出一道很常见的面试题
** 请讲述在你的项目中如何实现拉链表的? 讲清楚即可 贴和项目可以以其中一个表举例 **
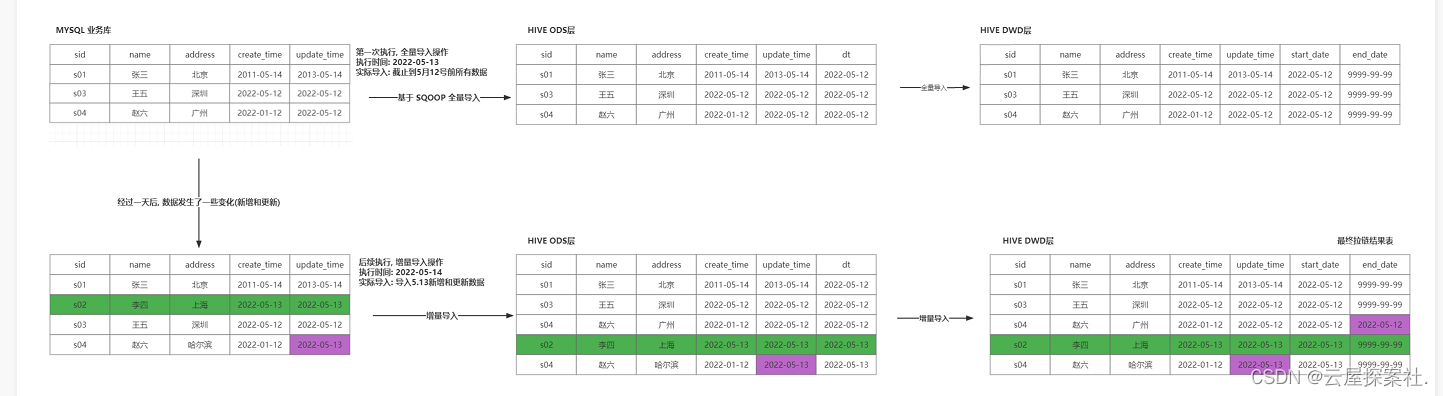
** **** 关于拉链表一般是用于在DWD中遇见这数据会有新增以及之前的数据会发生变化在这我才会才去采用SCD2来处理缓慢渐变维度。**
首先在我首日上线运行我会将数据进行全部开链以店铺的订单表为例
假设呢我是2022-06-06上线的我会把06-05日及以前的历史数据都导入到2022-06-05日的分区内
因为分区是采用动态分区所以我还要设置一下开启动态分区以及非严格模式和一下关于文件压缩的命令分区是以start_date进行分区但是ods并没有这样的数据呢么我去ods层查看发现dt就是开始的时间所以以dt as start_date并且在这里我会将一些数据清洗比如在这里是要求我们显示小程序 ios等呢么ods层显示的数字所以在这里我将数字转换为文字,利用case when来转化之后我会加end_date 和start_date在这里要注意由于分区要以start分区顺序不能颠倒要把start放在最后然后并且把end_date修改为"9999-99-99"
之后到了第二天以后如果发现有些数据及新增和修改我会将变动的新数据 新增和修改都改为开链并且修改旧记录的end_date设置为昨天的日期并且整个代码结构类似于封链union开链并且在闭链的过程中我会将更新的数据end_date修改为今天的日期-1把他毙掉并且还要考虑是否有多重修改的数据因为如果只考虑昨日修的数据会发生差错所以还要考虑end date是否为9999-99-99 封链代码中有一句话【or old.end_date!='9999-99-99'】意思是不要牵连到历史多次封链过的数据,他们是无辜的不用封为昨日。 我们对左表old中的某些数据封链,我们需要左表old的全部,右表new只是为了辅助判断给左表的end_end打上新的标记,如果符合封链条件就打上封链标记,否则维持原来的标记。对于开练部分我只需考虑将end设置为9999-99-99已经将这些数据放在今天的区内即可
并且把这些数据暂时放在临时表中查看数据是否正确。
代码如下
-- 假设2022-05-24日首次上线运行,需要将ODS表的2022-05-23日及以前的历史数据
-- 都导入到DWD表的2022-05-23日的分区内
--开启动态分区方式
set hive.exec.dynamic.partition=true;
--设置动态分区用非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
--开启hive中间MapReduce过程压缩
set hive.exec.compress.intermediate=true;
--开启hive的保存文件的压缩
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 下面的partition括号内只写了字段,没写值,意味着使用动态分区的方式,
-- 这要求下面的select部分的顺序的最后的字段要跟分区字段对应上。
insert overwrite table yp_dwd.fact_shop_order partition (start_date)
select id,
order_num,
buyer_id,
store_id,
--DWD层会做一些清洗转换的处理,下面就是典型的转换
case when order_from=1 then '安卓'
when order_from=2 then 'ios'
when order_from=3 then '小程序'
when order_from=4 then 'PC'
end as order_from,
order_state,
create_date,
finnshed_time,
is_settlement,
is_delete,
evaluation_state,
way,
is_stock_up,
create_user,
create_time,
update_user,
update_time,
is_valid,
'9999-99-99' as end_date, -- 让所有数据都生效。
dt as start_date
from yp_ods.t_shop_order where dt<= '2022-05-23';
后续新增即修改
-- 假设第二天2022-05-25日,需要将2022-05-24日内的新增及修改的数据,用拉链表的形式,导入的DWD层
--开启动态分区方式
set hive.exec.dynamic.partition=true;
--设置动态分区用非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
--开启hive中间MapReduce过程压缩
set hive.exec.compress.intermediate=true;
--开启hive的保存文件的压缩
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--创建一个临时表,来存放最终的结果,以方便校验结果
drop table if exists yp_dwd.fact_shop_order_temp;
create table yp_dwd.fact_shop_order_temp like yp_dwd.fact_shop_order;
desc yp_dwd.fact_shop_order_temp;
insert overwrite table yp_dwd.fact_shop_order_temp partition (start_date)
-- 处理闭链
select old.id,
old.order_num,
old.buyer_id,
old.store_id,
old.order_from,
old.order_state,
old.create_date,
old.finnshed_time,
old.is_settlement,
old.is_delete,
old.evaluation_state,
old.way,
old.is_stock_up,
old.create_user,
old.create_time,
old.update_user,
old.update_time,
old.is_valid,
case when new.id is null or old.end_date!='9999-99-99' then old.end_date
else date_add(new.dt,-1)
end as end_date,
old.start_date
from (select * from yp_dwd.fact_shop_order where start_date<='2022-05-23') as old
left join (select * from yp_ods.t_shop_order where dt='2022-05-24') as new
on old.id=new.id
union all
-- 处理开链
select id,
order_num,
buyer_id,
store_id,
--DWD层会做一些清洗转换的处理,下面就是典型的转换
case when order_from=1 then '安卓'
when order_from=2 then 'ios'
when order_from=3 then '小程序'
when order_from=4 then 'PC'
end as order_from,
order_state,
create_date,
finnshed_time,
is_settlement,
is_delete,
evaluation_state,
way,
is_stock_up,
create_user,
create_time,
update_user,
update_time,
is_valid,
'9999-99-99' as end_date,
dt as start_date
from yp_ods.t_shop_order where dt='2022-05-24';
show partitions yp_dwd.fact_shop_order_temp;
select * from yp_dwd.fact_shop_order_temp where start_date='2022-05-24';
-- 如果临时表的结果,验证无误,则覆盖导回到DWD原表
insert overwrite table yp_dwd.fact_shop_order partition (start_date)
select * from yp_dwd.fact_shop_order_temp;
--临时表的数据可以清空,给下次使用
drop table if exists yp_dwd.fact_shop_order_temp;
create table yp_dwd.fact_shop_order_temp like yp_dwd.fact_shop_order;
三、JOIN优化的三种方案
在做关于DWB层时我们需要降维所以在这一块我们需要进行价位并且根据模块将一些模块汇总成一个大表所以在这里我们需要join一些表所以在这里我们需要避免一些数据倾斜 但是有一点你要明白所有优化的前提都是要有资源的, 如果没有资源, 优化方案恰恰关闭优化
map join
正常情况下普通的join是利用reduce join但是如果用reduce join可能会出现数据倾斜并且reduce的压力会很大在这里呢可以用map joun把reduce的工作压力分给map join map Join中, 需要将一个表数据写入到每一个MapTask的内存中, 会导致内存空间占用率提高了, 这样导致无法向内存中放置一个大表, 只能放置一些小表数据因为maptask数量是由文件切片决定的所以每一个maptask再读取的时会产生一个块缓存然后和maptask的数据进行匹配
--适用于: 小表 和 大表的 JOIN操作
使用方案:
set hive.auto.convert.join=true; -- 是否开启 Map Join 默认为 True
set hive.auto.convert.join.noconditionaltask.size=512000000; -- 最大的小表的阈值 单位 字节 默认:20M
Bucket Map Join
在使用Bucket Map Join时要先清楚表格的大小一般为小表阈值10倍和大表在进行关联 并且Bucket Map Join使用是有一些条件的首先保证是在map task的基础上去构建的另外保证两个表都为分桶表并且分桶表是利用JOIN关联字段的 分桶的数量必须是另一个分桶表的倍数或者因子 必须开启bucket Map JOIN支持:
set hive.optimize.bucketmapjoin = true;
利用分桶表还是有一些优势的可以减少我们数据的扫描次数并且提升我们代码执行的效率以此来减少笛卡尔积
1- 需要保证两个JOIN的表必须为分桶表
2- 分桶的字段必须是JOIN的关联条件字段
3- 分桶的数量必须是另一个分桶表的倍数或者因子
4- 必须开启bucket Map JOIN支持:
set hive.optimize.bucketmapjoin = true;
5- 必须建立在map Join基础上
中型表需要分多少个桶呢? 取决于 中型表数据大小 和 小表阈值的倍数
SMB Join
对于SMB Join一般是用在大表和大表之间进行Join在我们使用SMB JOIN时要注意对于开SMB是很严苛的
1.需要保证两个表都为分桶表而且分桶的字段必须是JOIN的关联条件字段
2.两个表分桶数量要一致,
3.而且必须按照分桶的字段进行排序
4.必须建立在bucket Map JOIN
5.必须开启bucket Map JOIN支持:
代码如下(示例):
开启 SMB 相关的参数
--写入数据强制分桶
set hive.enforce.bucketing=true;
--写入数据强制排序
set hive.enforce.sorting=true;
--开启SMB Join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
-- 自动尝试SMB连接
set hive.optimize.bucketmapjoin.sortedmerge=true
优化面试题(希望大家掌握):
在你的项目中你是用了哪几种优化如何应用?
是这样子的我在做在我的项目中主要是用map join进行优化另外还用到一些bucket join的优化 其次对于一些表在join的时我会进行初步的判断看表的数据是否量很多以及表与表之间的关系来进行初步判断如果数据量不是很多我不会去采取优化因为采取优化是要有资源的所以为了节省资源我会优先不考虑优化其次在做一些小表对大表之间的join时为了提高速度 比如一些地区维度join宽表时我会采取map join优化因为这样子能避免数据倾斜但是map join也是很占用资源的我也会尽量让map join控制在一定量来节省资源 因为项目初期阶段我们的资源还是很有限的 同时在一些数据量较多时我会采取用bucket join来进行优化在优化前我会提前将两个表设置为分桶表并且是在map join的基础上去实用的还要考虑分桶的数量是否符合倍数和因子关系的我才会采取bucket join并且在sql中开启桶分区这样子会提高我们的代码查找速度以及减少笛卡尔积 所以当符合情况时我才会考虑用bucket join ,其次我也会采取reduce join 采取reduce join时我会设置reduce的数量来避免数据倾斜,同时我也会碰到一些特殊情况比如两个表的数据量都过于大 一般我会采取分而治之呢当资源充足时我会优先考虑利用SMB Join 但是在用之前考虑一些问题是否两个表都为分桶表是否都是join的关联字段并且分桶的数量是一样而且而按照分桶的字段进行排序并且呢是在bucket join支持 否则我是不会去考虑采用的,只是用在一些特殊的情况下我才会去使用并且开启相关的参数 以上就是我在项目中进行的优化
版权归原作者 云屋探案社. 所有, 如有侵权,请联系我们删除。