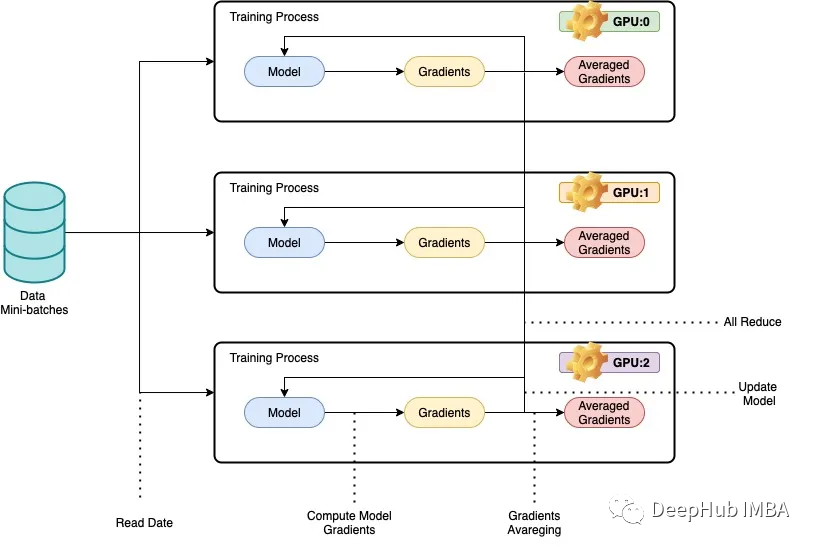
PyTorch 并行训练 DistributedDataParallel完整代码示例
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。在本文中我们将演示使用 PyTorch 的数据并行性和模型并行性。
Opencv项目实战:19 手势控制鼠标
在Opencv项目实战:15 手势缩放图片中,我们搭建了HandTrackingModule模块,但在这里你还得用本节的HandTrackingModule,因为有些功能并不需要,且也是分散了一些函数的功能。在这一节中,我的想法是通过点单个食指控制move,双指合并控制click,这样就能够实现手势
一文读懂ChatGPT模型原理
(本文是ChatGPT原理介绍,但没有任何数学公式,可以放心食用)前言这两天,ChatGPT模型真可谓称得上是狂拽酷炫D炸天的存在了。一度登上了知乎热搜,这对科技类话题是非常难的存在。不光是做人工智能、机器学习的人关注,而是大量的各行各业从业人员都来关注这个模型,真可谓空前盛世。我赶紧把 OpenA
63.Isaac教程--Flatsim
ISAAC教程合集地址: https://blog.csdn.net/kunhe0512/category_12163211.htmlflatsim 代表平面世界模拟,是一个小型模拟应用程序,可让您运行几乎完整的 Isaac 导航堆栈。 flatsim 应用程序通过在给定的占用网格图中投射光线来模
关于 ChatGPT 必看的 10 篇论文
2022年11月,OpenAI推出人工智能聊天原型ChatGPT,再次赚足眼球,为AI界引发了类似AIGC让艺术家失业的大讨论。ChatGPT 是一种专注于对话生成的语言模型。它能够根据用户的文本输入,产生相应的智能回答。这个回答可以是简短的词语,也可以是长篇大论。其中 GPT 是 Generati
yolov8训练自己的数据集
yolov8真的来了!U神出品的yolov8,虽然还没正式公布,但是已经放出代码了。代码有着很强烈的yolov5风格。学的速度还跟不上别人更新的速度,咋玩呀!先看看yolov8seg、det的炼丹。再看看map::都快卷秃噜皮了。yolov8s已经达到了0.6ms了。先看看ONNX图:这个是带NMS
图像处理:Tiler制作你的专属卡通头像和LOGO(圣诞特别篇)
快来用图像处理技术,生成你的专属卡通头像或LOGO吧!
Python CNN卷积神经网络实例讲解,CNN实战,CNN代码实例,超实用
Python CNN卷积神经网络实例讲解,CNN实战,CNN代码实例,套用简单
Transformer与看图说话
Transformer与看图说话
YOLO_V8训练自己的数据集
YOLO_V8训练自己的数据集
分布式链路追踪在数字化金融场景的最佳实践
从用户体验角度的监控运维一体化。打通移动端和服务端,从用户体验角度实现端到端的全链路监控。用户体验如手机银行、网贷、移动支付等代表了业务收入KPI,对齐科技部门和业务部门的目标,是企业数字化的关键,本质是从科技辅助业务,到科技和业务的知行合一。从人工智能角度的根因定位一体化。金融机构对AIOps的需
最近爆火chatGTP是人工智能还是人工智障?
1、目前的chatGTP局限性很多,有时候给出的回答不完善,不全面,没有真实性。2、现在更多仅可以作为简单的工具生成,或者灵感参考。3、训练所有的知识库截止于2021年,ChatGPT目前还没有连接网络,一旦它能够从网络上获取知识和信息,未来的潜力会更加可怕。4、希望未来能更加完善给生活带来更加便利
机器学习--决策树、线性模型、随机梯度下降
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取
YOLOV5损失函数
classification loss 分类损失localization loss 定位损失,预测框和真实框之间的误差confidence loss 置信度损失,框的目标性总损失函数为三者的和 classification loss + localization loss + confidence
一文速学(二十四)-数据分析之Pandas数据展示选项设置详解+实例代码操作展示
Pandas选项一般在数据展示和分析使用的比较频繁,尤其是配合上Jupyter Notebook使用敏捷开发时进行数据展示时,总会遇到一两个展示的问题比较头疼。而这又会牵扯到很多可视化效果的问题(比如pandas表默认科学计数法,无法展示全部数据等)。故了解Pandas选项设置是有必要的,这篇文章我
onnx文件及其结构、正确导出onnx、onnx读取、onnx创建、onnx修改、onnx解析器
通过onnx-ml.proto这个文件交给protoc,protoc是Protobuf提供的编译程序,把它。
超强AI绘画Midjourney使用教程
用户只需要输入一段图片的文字描述,即可生成精美的绘画。如果选择V1-V4,机器人就会根据你选择的图片基础上在重新生成4张图片。第六步:通常需要1分钟左右的时间,会根据你的文字描述生成四张图片。,将这个链接复制到浏览器打开,如果有人机验证,就验证一下。后按回车键,然后在输入想要生成图片的文字描述,等待
Opencv调参神器——trackBar控件
通过trackBur控件实现调参可视化,本文通过trackBar控件调整图片颜色、案例二:trackBar控件调整Canny算子参数、trackBar控件调整图像融合参数三个不同案例详细说明了trackBur控件的是用方法,相信能给您在计算机视觉Opencv调参节省不少时间!
OpenCV安装教程(全网最细,小白直接上手!!!)
OpenCV是Python、Ruby、MATLAB的接口,OpenCV在计算机视觉的发展中发挥了重要的作用,使成千上万的人能够在视觉上做更多的工作。由于在VSLAM技术研究过程中,经常会涉及OpenCV不同版本在ubuntu系统下的安装。文章简单总结了一下两个版本的OpenCV在ubuntu系统下的
计算机视觉框架OpenMMLab开源学习(六):语义分割基础
本系列第六篇文章主要介绍语义分割知识,了解计算机视觉框架OpenMMLab的MMSegmentation工具基本原理及使用,为后续语义分割实战做铺垫。



