
YOLO_V8在2023年开年横空出世,在春节前还得卷一下。
由于YOLO_V8和YOLO_V5是同一个作者,所以很多操作都是一样的,下面主要描述一下如何用自己的数据集进行训练和测试(非命令行的方式)。
1、训练数据和模型的目录结构
这里以口罩数据集为例,该数据集分为两类,戴口罩和不戴口罩:['mask', 'no-mask'],由于本文是进行目标检测任务,直接将数据集放到“detect”目录下,实际使用时可将“MaskDataSet”文件夹放到工程中的任何位置。
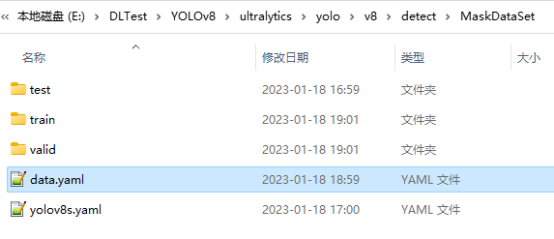
MaskDataSet
├─ test
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
├─ train
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
├─ valid
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
├─ data.yaml
└─ yolov8s.yaml
2、训练数据集的说明
train文件夹下主要包含训练图片images和标签labels,其中图片名和标签文件(.txt)名一一对应,且标签文件中保存的是对应图片中各个目标的类别和坐标(和YOLO_V5一样),例如:
类别+坐标
0 0.4669 0.2392 0.1822 0.3123
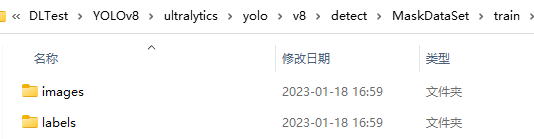
test和valid存储的东西和train完全一致。
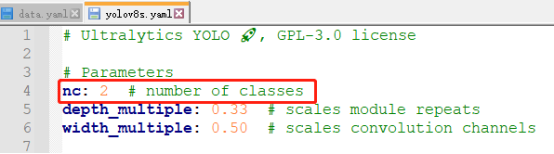
3、数据集参数文件data.yaml
data.yaml文件保存训练数据集的目录,类别数,类别名,如图所示:

我这里由于数据集的路径太深,直接使用了绝对路径,可根据需求自行修改。
4、模型参数文件yolov8s.yaml
YOLO_V8包含5种模型,主要差异还是在:depth_multiple和width_multiple
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.50 # scales convolution channels

本文以YOLOv8s为例进行说明,将yolov8s.yaml中的nc改为2即可。
5、训练前的参数配置
之前的YOLO_V5实在train.py文件中配置模型路径,数据路径,epochs等参数的,但是YOLO_V8做了较大的改变,将所有的参数整合到一个文件中集中配置(.\YOLOv8\ultralytics\yolo\configs\default.yaml),并且划分了检测、分类、分割任务,便于后续集成多个项目,特别容易维护。
task: "detect" # choices=['detect', 'segment', 'classify', 'init'] # init is a special case. Specify task to run.
mode: "predict" # choices=['train', 'val', 'predict', 'export'] # mode to run task in.
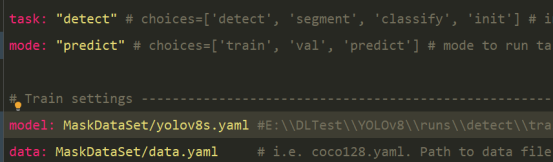
特别注意:mode应该加一个‘export’,在模型格式转换时就选择的是export。
6、开始训练
运行:YOLOv8\ultralytics\yolo\v8\detect\train.py,即可开始训练。
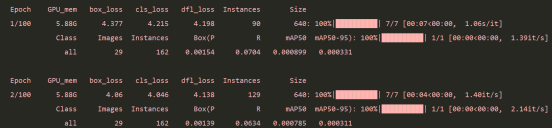
7、可能遇到的问题
1> OSError: [WinError 1455]页面文件太小,无法完成操作。
解决方法: 修改train.py中配置项workers的默认值,从初始值8修改为0(也可以试试1或2等较小的数)。
错误原因: workers=2, # 每个gpu分配的线程数,给每一个GPU喂数据的进程,GPU性能越强,取值越大,这样才能充分利用GPU的算力。如果用自己的电脑训练,这个值需要取小一些。
我在使用过程中直接将workers改为0
参考:https://blog.csdn.net/q839039228/article/details/124514664
版权归原作者 那年聪聪 所有, 如有侵权,请联系我们删除。