
🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅
一年一度的【博客之星】评选活动已开始啦
作为第一次且有幸能够参加评选的小博主
我诚惶诚恐
还请各位花费宝贵的几秒钟时间为我投上五星:
2022年「博客之星」参赛博主:老师我作业忘带了
✨✨✨✨✨谢谢各位✨✨✨✨✨
本项目来使用Transformer实现看图说话,即Image Caption任务。相关涉及的知识点有:迁移学习、EfficientNet、Transformer Encoder、Transformer Decoder、Self-attention。
项目效果如下:

文章末尾也展示了预测失败的时候
Image Caption:
- 让机器在图片中生成一段描述性的文字。
- 机器需要检测出图中的物体、还需要了解物体中相互的关系,最后生成合理的序言描述。
- 像这种既需要 **CV(计算机视觉) 又需要 **NLP(自然语言处理) 的称之为多模态。
Image Caption论文推荐:
- MAOJH,XU W,YANG Y,etal.Deep captioning with multi-modal recurrent neural networks (m-RNN)
- VINYALSO,TOSHEV A,BENGIOS,etal.Showandtell:A neural image caption generator
自然语言及注意力等论文推荐(新手):
- Efficient Estimation of Word Representations inVector Space
- Vaswani, Shazeer, Parmar, et al. (2017) Attention Is All You Need NeurIPS
- Devlin, Chang, Lee, Toutanova (2019) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding NAACL
- XU K,BA JL,KIROS R,etal.Show,attendandtell:Neural image caption generation with visual attention
- LU JS,XIONG C M,DEVIP,etal.Knowing whentolook: Adaptive attention via a visual sentinel for image captioning(自适应注意力机制)
项目流程如下:
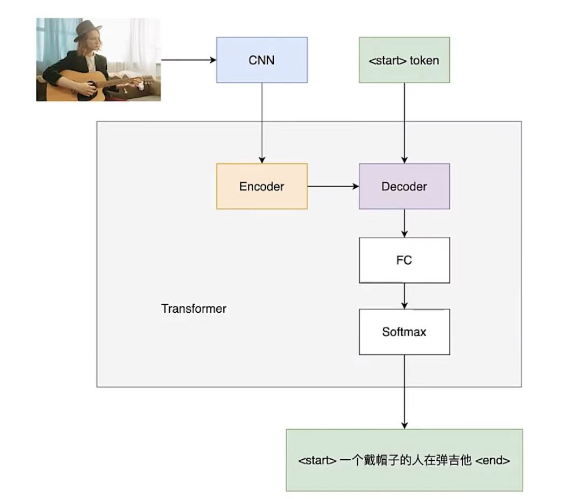
图片输入CNN进行特征提取后,输入Encoder形成序列,将token信号和Encoder的输出传递给Decoder,经过全连接和Softmax,得到输出结果。
详细网络架构:
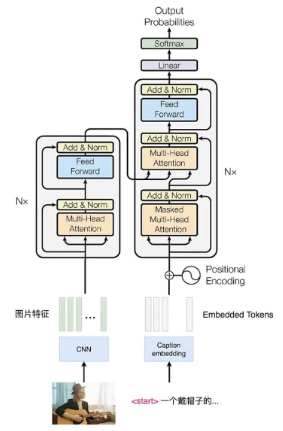
其中左下角为CNN特征提取,右下角为自然语言中的文本embedding,上方则为transformer经典网络架构。
数据文件内容如下:
下载链接: 点击此处

其中文件夹中存放本次训练使用的图片集,下方json文件则写有对应图片的标注,如:


代码流程:
本次项目代码比较多,均已写在下方,且注释我已经努力写得很详细了:
一、前期配置
**导入相关包 **
# 导入相关包
import os
import re
import cv2
import random
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 导入预训练CNN
from tensorflow.keras.applications import efficientnet
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
import json
import jieba
import tqdm
设置GPU训练
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
gpus
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
设计任务基本参数
# 设置基本参数
# 图片地址
IMAGES_PATH = "./ai_challenger_caption_validation_20170910/caption_validation_images_20170910/"
# 目标大小
IMAGE_SIZE = (299, 299)
# 词汇量大小
VOCAB_SIZE = 10000
# 输出句子单词长度
SEQ_LENGTH = 25
# 特征向量长度
EMBED_DIM = 512
# 输出层维度大小
FF_DIM = 512
# 训练参数
BATCH_SIZE = 64
EPOCHS = 30
AUTOTUNE = tf.data.AUTOTUNE
二、数据预处理
2.1 将图片和它的“label”对应起来
这一步我们把图片的相对路径和其5个caption以字典的形式对应起来,过程中要使用jieba进行中文分割,加上start和end,并且去掉带有不合格caption的例子,保证我们的输入在其中一个维度大小是5。
token_len = [] # 用于后面统计句子中词的长度
def load_captions_json(filename):
caption_mapping = {} # 映射字典 image1(path):[caption1,caption2...]
text_data = [] # 把合格的处理好的caption放到这里 后面用来向量化
images_to_skip = set() # 用来保存不合格的标注,后面在caption_mapping去掉对应的图片及其注释
# 打开并读取json文件
with open(filename) as f:
json_data = json.load(f)
# 遍历3W个json数据
for item in tqdm.tqdm(json_data):
# 图片的名字“id”
img_name = item['image_id']
# 图片的路径
img_path = os.path.join(IMAGES_PATH, img_name.strip())
# 遍历属于每个图片的5个标注
for caption in item['caption']:
# 分词
tokens =[word for word in jieba.cut(caption)]
# 根据tokens构造caption(空格分隔的字符串)
caption = " ".join(tokens)
# 存入句子中词的长度
token_len.append(len(tokens))
if len(tokens) < 3 or len(tokens) > SEQ_LENGTH:
images_to_skip.add(img_path)
continue
# 如果文件名以jpg结尾,且标注不在images_to_skip中
if img_path.endswith("jpg") and img_path not in images_to_skip:
# 增加开始和结束token
caption = "<start> " + caption.strip() + " <end>"
text_data.append(caption)
if img_path in caption_mapping:
# 追加
caption_mapping[img_path].append(caption)
else:
# 初始化
caption_mapping[img_path] = [caption]
# 如果文件名在images_to_skip中,则将caption_mapping中的元素删除掉
# 即这里可能有的caption不是5个
for img_path in images_to_skip:
if img_path in caption_mapping:
del caption_mapping[img_path]
return caption_mapping, text_data
# 加载数据
captions_mapping, text_data = load_captions_json("./ai_challenger_caption_validation_20170910/caption_validation_annotations_20170910.json")
# 可见句子中词的平均长度为13 符合我们上方所设置的参数 如果不符合可以进行微调
np.array(token_len).mean()
13.015133333333333
此时返回的:
captions_mapping则是一个字典,键为图片的相对路径,值是一个列表,里面是其5个caption。 text_data是一个列表,里面是全部的caption,和captions_mapping.values()结果应该是一样的。
2.2 设置训练集和测试集
train_size=0.8
# all_images列表里是所有图片的文件路径
all_images = list(captions_mapping.keys())
# 打乱顺序
np.random.shuffle(all_images)
# 获取训练集数量
train_size = int(len(captions_mapping) * train_size)
train_data = {
img_name: captions_mapping[img_name] for img_name in all_images[:train_size]
}
valid_data = {
img_name: captions_mapping[img_name] for img_name in all_images[train_size:]
}
len(train_data),len(valid_data)
(23896, 5975)
2.3 文本向量化
# 去除句子中的特殊符号
strip_chars = "!\"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"
strip_chars = strip_chars.replace("<", "") # 因为我们句子中有"<start>" "<end>"
strip_chars = strip_chars.replace(">", "")
def custom_standardization(input_string):
# 全部转为小写
lowercase = tf.strings.lower(input_string)
return tf.strings.regex_replace(lowercase, "[%s]" % re.escape(strip_chars), "")
vectorization = TextVectorization(
max_tokens=VOCAB_SIZE, # 词汇量大小 最上方设置10000
output_mode="int",
output_sequence_length=SEQ_LENGTH, # 输出句子长度 最上方设置25
standardize=custom_standardization,
)
vectorization.adapt(text_data)
# 查看所有词汇
vectorization.get_vocabulary()
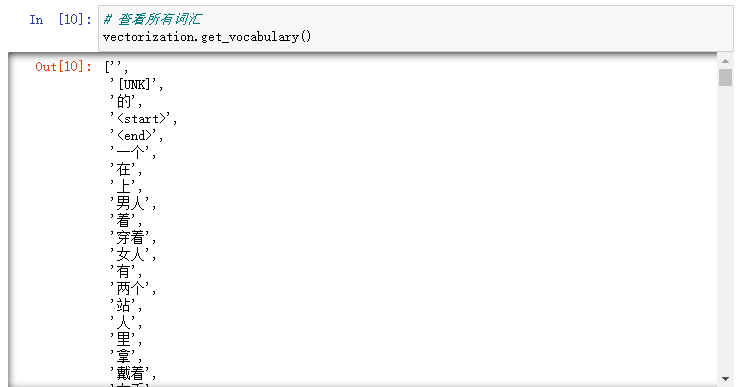
上方则是出现过的所有词,按照频率排序,索引0为空,1为未登入进来的词。
假如我们自己随便写句话:一个男人在打游戏

可以看到 '一个 男人 在 打 游戏' 这五个词的索引分别是 5,8,6,687 其中0代表补白(当然也可以看作索引0的空),如果句子短不到25就用0补充,超过25了就截断。

解码操作,vocab[向量] 如 vocab[[1,2,3]] 会得根据索引到相应的话
vocab = np.array(vectorization.get_vocabulary())
vocab[[5,8,6,67,687]]
array(['一个', '男人', '在', '打', '游戏'], dtype='<U7')
vocab[[7853,6,967,1]]
array(['我', '在', '准备', '[UNK]'], dtype='<U7')
2.4 制作数据集
这一步 我们要把train_data和valid_data这两个字典中的图片进行压缩resize 生成准备使用的数据集格式
- tf.data.Dataset.from_tensor_slices() 该函数的作用是接收tensor,对tensor的第一维度进行切分,并返回一个表示该tensor的切片数据集
def decode_and_resize(img_path):
# 读取图片,并缩放
img = tf.io.read_file(img_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, IMAGE_SIZE)
img = tf.image.convert_image_dtype(img, tf.float32)
return img
def process_input(img_path, captions):
return decode_and_resize(img_path), vectorization(captions)
def make_dataset(images, captions):
dataset = tf.data.Dataset.from_tensor_slices((images, captions))
dataset = dataset.shuffle(len(images))
dataset = dataset.map(process_input, num_parallel_calls=AUTOTUNE)
dataset = dataset.batch(BATCH_SIZE).prefetch(AUTOTUNE)
return dataset
# 制作数据集
train_dataset = make_dataset(list(train_data.keys()), list(train_data.values()))
valid_dataset = make_dataset(list(valid_data.keys()), list(valid_data.values()))
接下来我们从train_dataset中拿出数据来看一下到底是什么,因为它是一个可迭代对象,一批有64个(batch个),一共23896/64=374批只看一个就可以,所以记得加上break。
可以看到输入图片的大小是 299x299x3 后方词向量caption有5个,每个长25
for i in train_dataset:
print(i[0].shape)
print(i[1].shape)
break
(64, 299, 299, 3)
(64, 5, 25)
for i in train_dataset:
# 获取图片
img = i[0][0].numpy().astype('int')
# 获取标注(词向量)
caption = i[1][0].numpy()
# 显示
plt.imshow(img)
# 解码
print(vocab[caption])
break

2.5 数据增强
增的太强了会抑制过拟合 但会降低准确率(当然了0.0)
# 数据增强
image_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal"),
layers.experimental.preprocessing.RandomRotation(0.2),
layers.experimental.preprocessing.RandomContrast(0.3),
]
)
三、构建模型
3.1 构建CNN提取图片特征
方便起见,这里选择使用 EfficientNet 和 迁移学习 的方式来完成
其中 EfficientNet由16个移动翻转瓶颈卷积模块,2个卷积层,1个全局平均池化层和1个分类层构成。
def get_cnn_model():
# CNN模型
base_model = efficientnet.EfficientNetB0(
input_shape=(*IMAGE_SIZE, 3), include_top=False, weights="imagenet",
)
# 冻住特征提取层
base_model.trainable = False
base_model_out = base_model.output
# 我们要修改输出层,(n,100,1280)
base_model_out = layers.Reshape((-1, base_model_out.shape[-1]))(base_model_out)
cnn_model = keras.models.Model(base_model.input, base_model_out)
return cnn_model
cnn_model = get_cnn_model()
cnn_model.summary()
......
reshape (Reshape) (None, 100, 1280) 0 top_activation[0][0]
==================================================================================================
Total params: 4,049,571
Trainable params: 0
Non-trainable params: 4,049,571
__________________________________________________________________________________________________
这样 当我们每输入一批/一个batch个数据时,就会输出一批/一个batch个数据:
即输入 64x299x299x3的图片 输出64个图片的特征,维度是100x1280
测试一下CNN
# 模拟图片测试一下
cnn_test_input = tf.random.normal([64, 299,299,3]) # 随机正态分布64张299x299x3的图片
# 输入网络
cnn_test_output = cnn_model(cnn_test_input, training=False)
cnn_test_output.shape
TensorShape([64, 100, 1280])
3.2 构建编码器transformer encoder
class TransformerEncoderBlock(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__()
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention( # multi head attention
num_heads=num_heads, key_dim=embed_dim, dropout=0.0
) # 头的数量 输出维度的大小 dropout
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.dense_1 = layers.Dense(embed_dim, activation="relu")
def call(self, inputs, training, mask=None):
# layer norm
inputs = self.layernorm_1(inputs)
inputs = self.dense_1(inputs)
# 传入 q k v
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=None,
training=training, # training:布尔值,表示推理还是训练(是否使用 dropout)
)
# residual然后再layer norm
out_1 = self.layernorm_2(inputs + attention_output_1) # 残差链接
return out_1
测试一下transformer encoder
# 测试一下 我们把CNN的特征值给它
encoder = TransformerEncoderBlock(embed_dim=EMBED_DIM, dense_dim=FF_DIM, num_heads=1)
# 输入网络
encoder_test_output = encoder(cnn_test_output, training=False)
encoder_test_output.shape
TensorShape([64, 100, 512])
3.3 位置编码Positional Embedding
这一步做的是: 每张图片对应5个词向量,我们选出一个去掉最后的""(此时长为24了),之前比如词向量是[1,6,4,2,0,0,...,0] 现在对其进行升维,比如用一个二维(该项目升维512)坐标分别表示1,6,4,...,
如: 1->[0.1, 4.2] 6->[4.1, 2.0] ...
class PositionalEmbedding(layers.Layer):
# 位置编码
def __init__(self, sequence_length, vocab_size, embed_dim, **kwargs):
super().__init__()
'''
embedding用法:https://stats.stackexchange.com/questions/270546/how-does-keras-embedding-layer-work
input_dim:词汇数量;output_dim:特征向量大小
'''
# token embedding:长度为vocab_size,特征向量为:embed_dim
self.token_embeddings = layers.Embedding(
input_dim=vocab_size, output_dim=embed_dim
)
# position_embeddings:
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=embed_dim
)
self.sequence_length = sequence_length
self.vocab_size = vocab_size
self.embed_dim = embed_dim
# 512开根号:22.627416998:https://jalammar.github.io/illustrated-transformer/
self.embed_scale = tf.math.sqrt(tf.cast(embed_dim, tf.float32))
def call(self, inputs):
# 获取caption长度,这里是24个(前24个单词,去掉<end>)
length = tf.shape(inputs)[-1]
# 生成0~length(即24)的数字
positions = tf.range(start=0, limit=length, delta=1)
# 输入的句子index转为embedding特征,大小:(N, 24, 512)
embedded_tokens = self.token_embeddings(inputs)
# 乘以22.62 上面开根号了 这里乘过去 反向传播好算
embedded_tokens = embedded_tokens * self.embed_scale
# 位置编码,大小:(24, 512)
embedded_positions = self.position_embeddings(positions)
# 加和 返回
return embedded_tokens + embedded_positions
测试一下PositionalEmbedding
# 测试模型
test_embedding_model = PositionalEmbedding(embed_dim=EMBED_DIM, sequence_length=SEQ_LENGTH, vocab_size=VOCAB_SIZE)
# 测试输入,选择一个batch中的第一个句子(一共有5个)
for i in train_dataset:
# 获取测试标签中的一个的前24个词 大小(64, 24)
caption = i[1][:,0,:-1]
print(caption.shape)
# 传入模型
positional_output = test_embedding_model(caption)
# 打印结果的大小
print(positional_output.shape)
break
(64, 24)
(64, 24, 512)
强制教学,原来是64x24x1 现在是(64, 24, 512) 简单来说就是词向量映射到高维了
长度为24的单词变为512的embedding向量
3.4 构建解码器transformer decoder
这里不懂的自己查一下吧 三言两语说不完
总之 这一步最后输出为VOCAB_SIZE(这里为1000)大小的向量,对应位置的大小为概率,可以查索引来获取相应原单词,比如变成(64, 24, 10000)
class TransformerDecoderBlock(layers.Layer):
def __init__(self, embed_dim, ff_dim, num_heads, **kwargs):
super().__init__()
self.embed_dim = embed_dim
self.ff_dim = ff_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim, dropout=0.1
)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim, dropout=0.1
)
self.ffn_layer_1 = layers.Dense(ff_dim, activation="relu")
self.ffn_layer_2 = layers.Dense(embed_dim)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
# 位置编码
self.embedding = PositionalEmbedding(
embed_dim=EMBED_DIM, sequence_length=SEQ_LENGTH, vocab_size=VOCAB_SIZE
)
self.out = layers.Dense(VOCAB_SIZE, activation="softmax")
self.dropout_1 = layers.Dropout(0.3)
self.dropout_2 = layers.Dropout(0.5)
self.supports_masking = True
def call(self, inputs, encoder_outputs, training, mask=None):
# 获取位置编码,(N,24) --> (N,24,512)
inputs = self.embedding(inputs)
'''
causal_mask 的 shape:(64,24,24)
64个一模一样,大小为(24, 24)的mask
'''
causal_mask = self.get_causal_attention_mask(inputs)
'''
mask (64,24) --> padding_mask (64, 24, 1)
padding_mask:64个大小为(24, 1)的mask
[[1][1][1]...[0][0][0][0][0]]
'''
padding_mask = tf.cast(mask[:, :, tf.newaxis], dtype=tf.int32)
'''
mask (64,24) --> combined_mask (64, 1, 24)
combined_mask:64个大小为(1, 24)的mask
[[1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
'''
combined_mask = tf.cast(mask[:, tf.newaxis, :], dtype=tf.int32)
'''
在combined_mask与causal_mask选择最小值,大小(64, 24, 24)
64个不再一模一样,大小为(24, 24)的mask
'''
combined_mask = tf.minimum(combined_mask, causal_mask)
# 第一个masked self attention,QKV都是inputs, mask是causal mask,强制训练时只关注输出位置左侧的token,以便模型可以自回归地推断
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=combined_mask,
training=training,
)
out_1 = self.layernorm_1(inputs + attention_output_1)
# cross attention,其中K、V来自encoder,Q来自decoder前一个的attention输出,mask是padding mask,用来遮挡25个单词中补白的部分
attention_output_2 = self.attention_2(
query=out_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
training=training,
)
out_2 = self.layernorm_2(out_1 + attention_output_2)
ffn_out = self.ffn_layer_1(out_2)
ffn_out = self.dropout_1(ffn_out, training=training)
ffn_out = self.ffn_layer_2(ffn_out)
ffn_out = self.layernorm_3(ffn_out + out_2, training=training)
ffn_out = self.dropout_2(ffn_out, training=training)
# 最后输出为VOCAB_SIZE大小的向量,对应位置的大小为概率,可以查索引来获取相应原单词
preds = self.out(ffn_out)
return preds
def get_causal_attention_mask(self, inputs):
'''
causal: 因果关系mask
'''
# (N,24,512)
input_shape = tf.shape(inputs)
# 分别为N,24
batch_size, sequence_length = input_shape[0], input_shape[1]
#范围0~24的列表,变成大小(24, 1)的数组
i = tf.range(sequence_length)[:, tf.newaxis]
#范围0~24的列表
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
# 大小为(1, 24, 24)
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
scale = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)],
axis=0,
)
# (1, 24, 24)铺成(64, 24, 24)
result = tf.tile(mask, scale)
return result
测试一下transformer decoder
# 测试模型
decoder = TransformerDecoderBlock(embed_dim=EMBED_DIM, ff_dim=FF_DIM, num_heads=2)
# decoder.summary()
# 测试输入
for i in train_dataset:
# 前0~ -1(24)个单词(去尾)
batch_seq_inp = i[1][:,0,:-1]
# print(batch_seq_inp.shape)
# 前1~ 个(24)个单词(掐头),用做ground truth标注
batch_seq_true = i[1][:,0,1:]
# print(batch_seq_true.shape)
# 将batch_seq_true中的每一个元素和0作对比,返回类似[true,true,false]形式的mask,遇到0,则会变成false,0表示字符串中长度不够25的补白部分(padding)
mask = tf.math.not_equal(batch_seq_true, 0)
# print(mask.shape)
# 输入decoder预测的序列
batch_seq_pred = decoder(
batch_seq_inp, encoder_test_output, training=False, mask=mask
)
print(batch_seq_pred.shape)
break
(64, 24, 10000)
3.5 构建ImageCaption任务模型
这里调用到上方CNN、encoder和decoder 顺序为该项目的模型流程
- 获取图片CNN特征--》
- 传给encoder--》
- 1.对于decoder先提供<start>--》
- 2.传给decoder推理--》
- 3.不断投喂给模型,直到遇到停止.
- 4.如果循环次数超出句子长度,也停止.
class ImageCaptioningModel(keras.Model):
def __init__(
self, cnn_model, encoder, decoder, num_captions_per_image=5, image_aug=None,
):
super().__init__()
self.cnn_model = cnn_model
self.encoder = encoder
self.decoder = decoder
self.loss_tracker = keras.metrics.Mean(name="loss")
self.acc_tracker = keras.metrics.Mean(name="accuracy")
self.num_captions_per_image = num_captions_per_image
self.image_aug = image_aug
def calculate_loss(self, y_true, y_pred, mask):
loss = self.loss(y_true, y_pred)
mask = tf.cast(mask, dtype=loss.dtype)
loss *= mask
return tf.reduce_sum(loss) / tf.reduce_sum(mask)
def calculate_accuracy(self, y_true, y_pred, mask):
accuracy = tf.equal(y_true, tf.argmax(y_pred, axis=2))
accuracy = tf.math.logical_and(mask, accuracy)
accuracy = tf.cast(accuracy, dtype=tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
return tf.reduce_sum(accuracy) / tf.reduce_sum(mask)
def _compute_caption_loss_and_acc(self, img_embed, batch_seq, training=True):
'''
计算loss
'''
# 图片的embedding特征输入encoder,得到新的seq,大小(N,100,512)
encoder_out = self.encoder(img_embed, training=training)
# batch_seq的shape:(64, 25)
# 前24个单词(去尾)
batch_seq_inp = batch_seq[:, :-1]
# 后24个单词(掐头),用做ground truth标注
batch_seq_true = batch_seq[:, 1:]
# mask掩码,将batch_seq_true中的每一个元素和0作对比,返回类似[true,true,false]形式的mask,遇到0,则会变成false,0表示字符串中长度不够25的补白部分(padding)
mask = tf.math.not_equal(batch_seq_true, 0)
# 输入decoder预测的序列
batch_seq_pred = self.decoder(
batch_seq_inp, encoder_out, training=training, mask=mask
)
# 计算loss和acc
loss = self.calculate_loss(batch_seq_true, batch_seq_pred, mask)
acc = self.calculate_accuracy(batch_seq_true, batch_seq_pred, mask)
return loss, acc
def train_step(self, batch_data):
'''
训练步骤
'''
# 获取图片和标注
batch_img, batch_seq = batch_data
# 初始化
batch_loss = 0
batch_acc = 0
# 是否使用数据增强
if self.image_aug:
batch_img = self.image_aug(batch_img)
# 获取图片embedding特征
img_embed = self.cnn_model(batch_img)
# 遍历5个文本标注
for i in range(self.num_captions_per_image):
with tf.GradientTape() as tape:
# 计算loss和acc
# batch_seq的shape:(64, 5, 25)
loss, acc = self._compute_caption_loss_and_acc(
img_embed, batch_seq[:, i, :], training=True
)
# 更新loss和acc
batch_loss += loss
batch_acc += acc
# 获取所有可训练参数
train_vars = (
self.encoder.trainable_variables + self.decoder.trainable_variables
)
# 获取梯度
grads = tape.gradient(loss, train_vars)
# 更新参数
self.optimizer.apply_gradients(zip(grads, train_vars))
# 更新
batch_acc /= float(self.num_captions_per_image)
self.loss_tracker.update_state(batch_loss)
self.acc_tracker.update_state(batch_acc)
return {"loss": self.loss_tracker.result(), "acc": self.acc_tracker.result()}
def test_step(self, batch_data):
batch_img, batch_seq = batch_data
batch_loss = 0
batch_acc = 0
# 获取图片embedding特征
img_embed = self.cnn_model(batch_img)
# 遍历5个文本标注
for i in range(self.num_captions_per_image):
loss, acc = self._compute_caption_loss_and_acc(
img_embed, batch_seq[:, i, :], training=False
)
batch_loss += loss
batch_acc += acc
batch_acc /= float(self.num_captions_per_image)
self.loss_tracker.update_state(batch_loss)
self.acc_tracker.update_state(batch_acc)
return {"loss": self.loss_tracker.result(), "acc": self.acc_tracker.result()}
@property
def metrics(self):
return [self.loss_tracker, self.acc_tracker]
四、编译模型
4.1 模型实例化
cnn_model = get_cnn_model()
encoder = TransformerEncoderBlock(embed_dim=EMBED_DIM, dense_dim=FF_DIM, num_heads=1)
decoder = TransformerDecoderBlock(embed_dim=EMBED_DIM, ff_dim=FF_DIM, num_heads=2)
caption_model = ImageCaptioningModel(
cnn_model=cnn_model, encoder=encoder, decoder=decoder, image_aug=image_augmentation,
)
4.2 设置loss、早停参数
# loss
cross_entropy = keras.losses.SparseCategoricalCrossentropy(
from_logits=False, reduction="none"
)
# 提前终止
early_stopping = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
class LRSchedule(keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, post_warmup_learning_rate, warmup_steps):
super().__init__()
self.post_warmup_learning_rate = post_warmup_learning_rate
self.warmup_steps = warmup_steps
def __call__(self, step):
global_step = tf.cast(step, tf.float32)
warmup_steps = tf.cast(self.warmup_steps, tf.float32)
warmup_progress = global_step / warmup_steps
warmup_learning_rate = self.post_warmup_learning_rate * warmup_progress
return tf.cond(
global_step < warmup_steps,
lambda: warmup_learning_rate,
lambda: self.post_warmup_learning_rate,
)
# LR调节
num_train_steps = len(train_dataset) * EPOCHS
num_warmup_steps = num_train_steps // 15
lr_schedule = LRSchedule(post_warmup_learning_rate=1e-4, warmup_steps=num_warmup_steps)
4.3 编译并训练
# 编译
caption_model.compile(optimizer=keras.optimizers.Adam(lr_schedule), loss=cross_entropy)
# 训练
caption_model.fit(
train_dataset,
epochs=EPOCHS,
validation_data=valid_dataset,
callbacks=[early_stopping],
)
4.4 保存权重
caption_model.save_weights("./my_model/checkpoint")
4.5 加载权重进行测试
load_status = caption_model.load_weights("./my_model/checkpoint")
vocab = vectorization.get_vocabulary()
index_lookup = dict(zip(range(len(vocab)), vocab))
max_decoded_sentence_length = SEQ_LENGTH - 1
valid_images = list(valid_data.keys())
valid_caption = list(valid_data.values())
valid_len = len(valid_images)
- 获取图片CNN特征--》
- 传给encoder--》
- 1.对于decoder先提供<start>--》
- 2.传给decoder推理--》
- 3.不断投喂给模型,直到遇到停止.
- 4.如果循环次数超出句子长度,也停止.
def generate_caption():
# 在测试集中随机取一张图片
random_index = random.randrange(0,valid_len)
sample_img = valid_images[random_index]
sample_caption = valid_caption[random_index][0]
# 读取图片
sample_img = decode_and_resize(sample_img)
img_show = sample_img.numpy().clip(0, 255).astype(np.uint8)
plt.imshow(img_show)
plt.axis('off')
plt.show()
# 保存
cv2.imwrite('./img/raw.jpg',cv2.cvtColor(img_show,cv2.COLOR_RGB2BGR))
# 获取CNN特征
img = tf.expand_dims(sample_img, 0)
img = caption_model.cnn_model(img)
# 传给encoder
encoded_img = caption_model.encoder(img, training=False)
# 1.先提供"<start> "
# 2.传给decoder推理,
# 3.不断投喂给模型,直到遇到<end>停止
# 4.如果循环次数超出句子长度,也停止
decoded_caption = "<start> "
for i in range(max_decoded_sentence_length): # 24
tokenized_caption = vectorization([decoded_caption])[:, :-1]
mask = tf.math.not_equal(tokenized_caption, 0)
# 预测
predictions = caption_model.decoder(
tokenized_caption, encoded_img, training=False, mask=mask
)
sampled_token_index = np.argmax(predictions[0, i, :])
sampled_token = index_lookup[sampled_token_index]
if sampled_token == " <end>":
break
decoded_caption += " " + sampled_token
decoded_caption = decoded_caption.replace("<start> ", "")
decoded_caption = decoded_caption.replace(" <end>", "").strip()
sample_caption = sample_caption.replace("<start> ", "")
sample_caption = sample_caption.replace(" <end>", "").strip()
print("预测: ", decoded_caption)
print('真实:',sample_caption)
generate_caption()

generate_caption()

4.6 测试自己的图片
def predict_imgs(path):
input_img = decode_and_resize(path).numpy().clip(0, 255).astype(np.uint8)
plt.imshow(input_img)
plt.axis('off')
plt.show()
# 获取CNN特征
img = tf.expand_dims(input_img, 0)
img = caption_model.cnn_model(img)
# 传给encoder
encoded_img = caption_model.encoder(img, training=False)
# 1.先提供"<start> "
# 2.传给decoder推理,
# 3.不断投喂给模型,直到遇到<end>停止
# 4.如果循环次数超出句子长度,也停止
decoded_caption = "<start> "
for i in range(max_decoded_sentence_length): # 24
tokenized_caption = vectorization([decoded_caption])[:, :-1]
mask = tf.math.not_equal(tokenized_caption, 0)
# 预测
predictions = caption_model.decoder(
tokenized_caption, encoded_img, training=False, mask=mask
)
sampled_token_index = np.argmax(predictions[0, i, :])
sampled_token = index_lookup[sampled_token_index]
if sampled_token == " <end>":
break
decoded_caption += " " + sampled_token
decoded_caption = decoded_caption.replace("<start> ", "")
decoded_caption = decoded_caption.replace(" <end>", "").strip()
print("预测: ", decoded_caption)
path = './a01.jpg'
predict_imgs(path)

主要原因是我们的数据集见识比较少,导致预测错误。
path = './a02.jpg'
predict_imgs(path)

这次模型将功补过,成功悟出了一代巨星的动作!
版权归原作者 老师我作业忘带了 所有, 如有侵权,请联系我们删除。