【AI知识点】小世界网络(Small-World Networks)
小世界网络(Small-World Networks) 是一种具有独特拓扑结构的网络模型,广泛应用于研究社交网络、神经网络、互联网以及其他复杂系统中的节点间连接方式。小世界网络的特点是节点之间的平均路径长度较短,并且大多数节点的局部连接较多,同时存在少量长距离连接(也称为“捷径”)。这一网络结构使得
AI大模型系列之七:Transformer架构讲解
Transformer模型设计之初,用于解决机器翻译问题,是完全基于注意力机制构建的编码器-解码器架构,编码器和解码器均由若干个具有相同结构的层叠加而成,每一层的参数不同。编码器主要负责将输入序列转化为一个定长的向量表示,解码器则将这个向量解码为输出序列。Transformer总体架构可分为四个部分
人工智能在病理切片虚拟染色及染色标准化领域的系统进展分析|文献速递·24-07-07
这篇文章介绍了一个自动化的端到端深度学习框架,用于从未经染色的病理图像中进行分类和肿瘤定位。研究由Akram Bayat、Connor Anderson和Pratik Shah等人完成,并发表在2021年SPIE医学成像会议的图像处理卷中。背景与挑战:传统的组织病理学图像分析依赖于染色技术,但存在样
Genmo团队开发的前沿AI视频生成模型;Fragments支持安全执行 AI 生成的代码;Meta开源从视频中学习仿生
POC Python Realtime API o1助手是一个概念验证项目,旨在利用OpenAI的实时API,实现工具链的调用、o1-preview和o1-mini的集成、结构化输出的响应处理,从而展望未来的智能助手工程。Mochi 1的高效性和灵活性使其在多种行业中都有很大的潜力,虽然当前在480
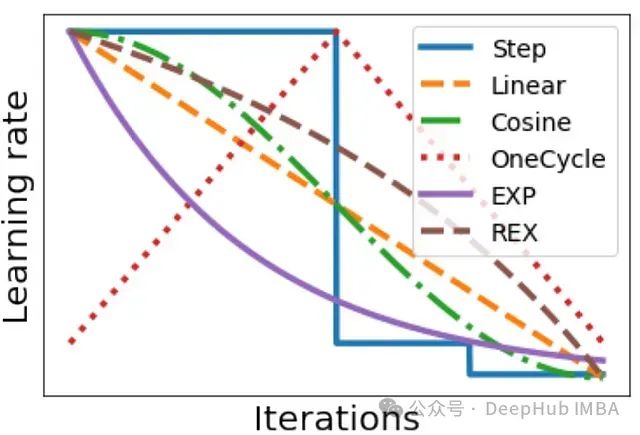
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。
什么是人工智能
更新时间: 2024-02-04 01:43:20内容人工智能AI(即)是计算机科学的一个分支,旨在让计算机模仿人类的决策能力、像人类一样思考和行动,来解决如自然语言处理、推荐、智能数据检索、预测等方面人类无法处理或难以处理的复杂工作。云计算是一种通过互联网提供计算资源和服务的技术容器是一种虚拟化技
从零开始学cv-4:图像ROI提取
在上一章,我们学习了多种常用的图像编辑算法。接下来,我们将探讨如何利用OpenCV实现图像提取。本文旨在深入探讨如何高效提取图像ROI(Region of Interest,感兴趣区域)的技术。我们将从ROI的基础概念出发,详细介绍如何通过鼠标操作、图像处理技术以及编程实践,在Python中使用Op
制造业人工智能的场景应用落地现状、难点和建议
制造业应用人工智能可以提高制造业的生产效率,推动制造业高质量发展和竞争力提升,促进国民经济的持续稳定增长。近年来,制造业人工智能的场景化应用落地不断推进,但在落地过程中遇到一些难点。本文对于制造企业应用人工智能的场景化落地的现状和难点进行分析,提出制造业人工智能的场景应用落地的建议。
【AIGC】AI文本转语音+语音转文本,构建专属领域转文本模型
我们展示了如何使用阿里百炼的语音合成和语音识别技术,实现文本转语音和语音转文本的完整流程,并讲述如何针对自己的业务构建专属转文本模型。我们获取到比较精确的转出的文字再去做别的处理,可以极大帮助我们的实际业务。
弹性AI与鲁棒性:现代人工智能的双重保障
弹性AI指的是人工智能系统在面对变化和不确定性时,能够有效调整自身行为并保持性能的能力。这种能力使得AI能够在动态环境中做出快速响应,从而实现高效的决策和操作。鲁棒性是指系统在面对外部干扰、噪声或不确定性时,依然能够保持其性能和稳定性的能力。在机器学习和人工智能中,鲁棒性尤为重要,因为模型常常面临不
Flamingo:通向多模态AI的里程碑
在深入Flamingo之前,我们首先需要理解什么是多模态建模。简单来说,多模态建模是指能够同时处理多种类型数据的机器学习模型。在人工智能领域,我们通常将文本、图像、表格、音频等不同类型的数据称为不同的"模态"。因此,能够同时理解和处理多种模态数据的模型就是多模态模型。视觉语言建模是多模态建模中最受关
芝士AI(paperzz)一天搞定!论文降重神话,75%到3%的秘密!
芝士AI(paperzz)论文写作是一款专业满足你的论文写作需求的服务平台,涵盖700+学科专业方向,致力于一键解决所有论文写作难题。它不仅能够提供智能的降重建议,还能针对不同查重平台的查重规则进行定制化的降重处理,这对于急需提交论文的同学们来说,无疑是一大福音。只需一个论文题目,即可快速构建出结构
真免费!10 款必备的语言类 AI 大模型
通义千问是阿里云推出的一个大型语言模型,它是通义系列的最新成果,能够回答问题、创作文字,还能表达观点、撰写代码,具备丰富的知识和强大的语言生成能力。它拥有强大的自然语言处理和智能交互能力,能够实现智能问答、聊天互动、文本生成等多种应用场景,并且具有丰富的知识储备,涵盖科学、技术、文化、艺术、历史等领
如何利用Ai辅助写小说,保持文笔统一,并激发灵感?
简单的说,无论你是专业的小说创作者,还是业务爱好者,只需要构思一个小说的大体内容框架,也就是“写什么样的故事”,后面的创作工作Write Wise都可以用AI助手生成,创作小白也能轻松上手!但AI工具的出现,无疑是简化了工作量,AI可以帮助我们拆解复杂的工作,并在小说创作的过程中充当协作者,帮我们答
Unity接入人工智能
Unity接入人工智能,制作对话系统
Unity AI设计 行为树与有限状态机
今天抽出一点空闲时间给大家讲解一下AI的设计实现思路的常见方法,学习游戏中那些复杂的AI行为是如何实现的。
人工智能的核心技术之机器学习
人工智能(AI)是一个快速发展的领域,其核心技术不断演进和扩展。机器学习(Machine Learning):这是AI的一个分支,使计算机能够从数据中学习并做出预测或决策。深度学习(Deep Learning):是机器学习的一个子集,它使用多层神经网络来模拟人脑的信息处理方式,处理复杂的数据模式。自
最新Prompt预设词指令教程大全ChatGPT、AI智能体(300+预设词应用)
请最新Prompt预设词指令教程大全ChatGPT、AI智能体(300+预设词应用)
国产AI新突破!通义万相视频生成模型来了
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达2024年是AIGC大爆发的一年!尤其是视频生成(Video Generation)领域已经成为当前各大公司、高校发力的重点目标。视频生成之所以如此重要,是因为它能够帮助人们快速创建各种类型的视频内容,在教育、娱乐、自动驾驶、医疗等
Rust 与生成式 AI:从语言选择到开发工具的演进
详细探讨 Rust 语言的现状与趋势,并分析它如何与生成式 AI结合,从而提升开发效率和质量。



