AI工具FastGPT和RagFlow对比选型
FastGPT和RagFlow在AI工具领域各有千秋,在选择时应根据自身的需求和场景特点进行综合考虑。如果需要快速构建知识库和生成文本回答,FastGPT是一个不错的选择;而如果需要处理复杂格式的非结构化数据并追求更精准、更可信的问答结果,RagFlow则更具优势。
用代码构建未来:英伟达RAG线上训练营,开启我的AI炼金术
通过代码实战,我理解了如何将预训练的语言模型与检索系统结合,并通过调试模型参数来优化结果,并且这种介绍了Microsoft-phi3小模型的各个版本实践代码操作直观的让学员的有深入其境的体验。并且直接用代码demo的形式展示给学院的实践和应用的在更多的未知领域的希望和探索的可能得憧憬,我亲自实践的在
Labelme 使用指南(语义分割、实例分割、ai标注)
Labelme 使用指南(语义分割、实例分割、ai标注)
AI全景解析:探索人工智能的世界
随着人工智能技术的不断进步,我们期待它能够在更多领域发挥作用,并为解决人类面临的复杂问题提供新的解决方案。通过不断探索、创新和合作,我们将能够充分发挥人工智能的潜力,推动社会的全面发展和进步。
【RL】强化学习入门:从基础到应用
【RL】强化学习入门:从基础到应用强化学习,本文介绍了强化学习的基础和python经典实现。(Reinforcement Learning, RL)是机器学习的一个重要分支,它使得智能体通过与环境的互动来学习如何选择最优动作,以最大化累积奖励。近年来,随着深度学习技术的发展,强化学习取得了显著的进展
Windows10部署MiniCPM
安装Anaconda,参考https://blog.csdn.net/weixin_43881345/article/details/136051556创建一个基于python3.10的虚拟环境创建虚拟环境报错,根据提示删除环境变量Path中多余的引号重新创建python3.10的虚拟环境,取名mi
昇思MindSpore AI框架MindFormers实践2:基于T5的SQL语句生成模型推理
经过测试,发现可以直接在t5 = T5ForConditionalGeneration.from_pretrained(model_path) 这句话里写模型名字,如:t5 = T5ForConditionalGeneration.from_pretrained("t5_small")系统会自动下载
华为全联接大会HUAWEI Connect 2024印象(二):昇腾AI端侧推理
此次和昇腾合作的应该是Orange Pi AIPro,不过一楼的小伙似乎对产品和行业都不太熟悉,和他沟通感觉没有啥收获,我当时一度觉得此次会议白来了。后来华为的技术人员和我介绍这个机器人的比较复杂的视觉测量是在云端完成的,控制工作是在端侧完成的。华为的技术人员很专业,和我介绍了很多关于昇腾AI的内容
【AI战略思考2】技术上不断聚焦和深入,精进一艺,一技胜万全
本篇博客确定了我大致的研究方向和原则:研究方向:nlp领域下的RAG技术应用方向,企业普遍存在的一个痛点和难点,且有较大的实用价值。原则:不断聚焦和深入
【干货】5款超强大的AI数据分析工具,建议收藏
它和其他Excel的AI公式生成不一样,它会直接执行命令,无需你获取公式后再复制操作,这对于不会用Excel或是Excel公式不熟练的小伙伴相当友好!也是一款在线 AI Excel 编辑器工具,无需学习Excel繁琐的操作和公式,只需输入简单的提示语,自动进行数据操作或编写公式,非常方便地提高效率!
【torch.quantile】分位数计算
torch.quantile 分位数计算方法。
用亚马逊AI代码开发助手Amazon Q Developer开发应用(上篇)
Amazon Q Developer 是一款由亚马逊云科技推出的AI驱动的软件开发助手,用于帮助开发者重新构想整个软件开发生命周期的体验,使得在亚马逊云科技或其他平台上构建、保护、管理和优化代码的过程变得更加快捷。其中比较亮点的功能是Amazon Q Developer Agent,它一个特性开发代
万字深剖!13位AI巨擘联袂,1.6万字解码生成式AI产品「全攻略」
在这场席卷全球的 AI 浪潮中,生成式 AI 产品也正在经历一场前所未有的变革。回溯过往,生成式 AI 的萌芽从算法模型的初步探索开始,当时还局限于特定领域内的简单应用。然而随着大数据的积累、计算能力的提升以及算法模型的持续优化,生成式 AI 开始展现出惊人的创造力与学习能力:从简单的文本创作到复杂
【有啥问啥】人工智能中的世界模型(World Models):详尽解析与未来展望
世界模型是AI系统内部构建的一种抽象表示,用于描述、理解和预测外部环境的状态及其变化。它融合了AI系统从传感器接收的原始数据(如图像、声音、触觉等),通过复杂的处理和分析,形成对外部世界的全面认知和预测。在具体实现中,世界模型可以以多种形式存在,如概率模型、物理模型、生成模型等。每种模型都有不同的结
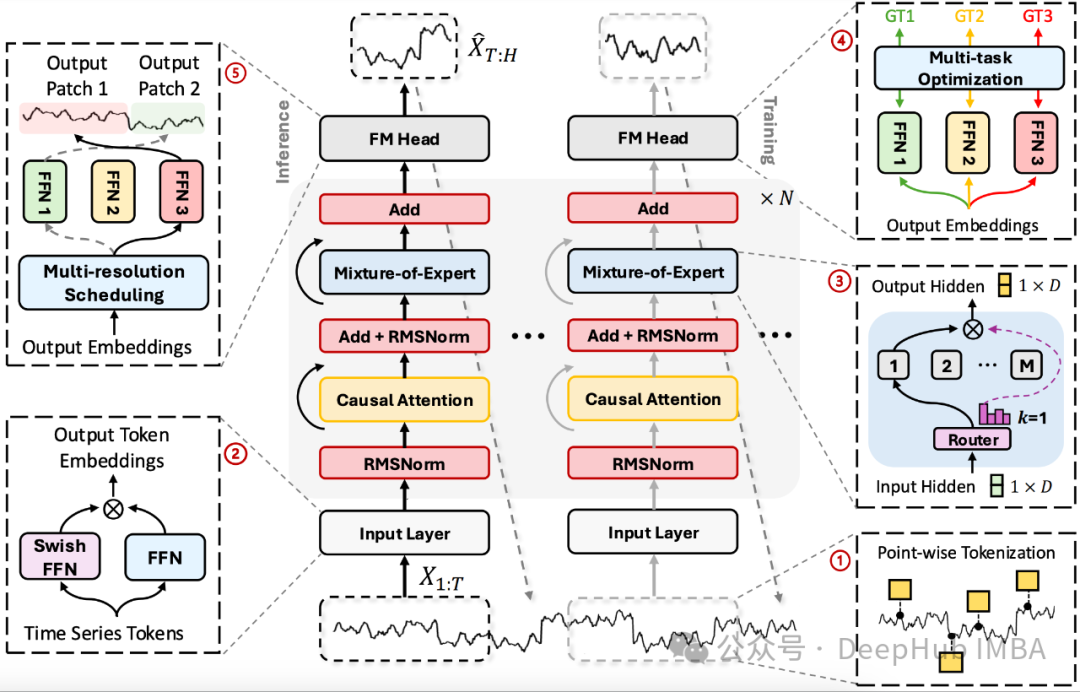
TimeMOE: 使用稀疏模型实现更大更好的时间序列预测
这是9月份刚刚发布的论文TimeMOE。它是一种新型的时间序列预测基础模型,"专家混合"(Mixture of Experts, MOE)在大语言模型中已经有了很大的发展,现在它已经来到了时间序列。
GNN会议&期刊汇总(人工智能、机器学习、深度学习、数据挖掘)
顶会顶刊:【NeurIPS】【ICLR】【AAAI】【WWW】【ICML】【LoG】【CIKM】【WSDM】【KDD】【IJCAI】【TKDE】
AI驱动TDSQL-C Serverless 数据库技术实战营-电商可视分析
详细指导开发者如何利用腾讯云的高性能应用服务 HAI 和TDSQL-C MySQL Serverless 版构建 AI电商数据分析系统。
Wordware暴走:AI社交裂变的妙用与隐患探讨
最近,推特(X)上出现了一个风靡全球的社交应用——**Wordware**。该应用引发了一场社交裂变的热潮,连埃隆·马斯克都参与其中,展示了它的社交吸引力。然而,伴随这一现象的爆发,也让我们看到了AI技术在社交网络中的巨大潜力与隐患。本文将通过技术分析与案例解读,详细探讨Wordware的妙用及其背
BlinqIO:业界首个生成式 AI 测试平台
生成式人工智能软件测试初创公司 BlinqIO 打造了业界首个生成式 AI 测试平台,由专有的大型语言模型提供支持,采用生成式人工智能技术,并宣称该平台可以替代手工测试工程师;它能够理解软件测试的需求、可以自行创建测试自动化代码,并完全自主地维护该代码;它可以在无需任何监督的情况下,执行测试脚本和维
【人工智能】OpenAI最新发布的o1-preview模型,和GPT-4o到底哪个更强?最新分析结果就在这里!
OpenAI最新发布的GPT-o1模型,和GPT-4o到底哪个更强?最新分析结果就在这里!



