Halcon图像的 OCR 识别&训练字符
算子:create_ocr_class_mlp( : : WidthCharacter, HeightCharacter, Interpolation, Features, Characters, NumHidden, Preprocessing, NumComponents, RandSeed :
艺术创作的新纪元:如何训练Lora模型打造令人惊叹的AI绘画
在数字时代的今天,人工智能(AI)技术正不断改变着我们的生活,也给艺术领域带来了前所未有的革新。AI绘画模型,作为其中的一颗明星,让计算机能够像艺术家一样创作绘画作品,引发了广泛关注。然而,AI绘画模型的训练对计算资源和时间的要求较高,这对于大部分人来说是一项挑战。幸运的是,云端平台的出现可以完美的
排序之损失函数List-wise loss(系列3)
在pointwise 中,我们将每一个 作为一个训练样本来训练一个分类模型。这种方法没有考虑文档之间的顺序关系;而在pariwise 方法中考虑了同一个query 下的任意两个文档的相关性,但同样有上面已经讲过的缺点;在listwise 中,我们将一个 作为一个样本来训练。论文中还提出了概率分布的方
神经网络:训练模型+转化为k210上跑的kmodel
深度学习(1):训练模型+转化为k210上跑的kmodel
从零构建自己的神经网络————数据集篇
例如,可以将图片文件命名为1.jpg,2.jpg,3.jpg等,对应的标注文件命名为1.txt,2.txt,3.txt等。其中,txt_path是包含数据集信息的文本文件的路径,transform是对数据集进行预处理的函数或变换。每张图片都有一个唯一的标识符(比如图片的文件名或者数据库中的id),在
YOLOv7目标检测数据集划分
数据集划分
softmax是什么?
Softmax是一种常用的分类函数,它将一个n维向量(通常用于表示某个实体的特征向量)输入,并将其标准化为一个n维概率分布,其中每个元素的值都介于0和1之间,并且所有元素的和为1。softmax函数通过将n维向量z的每个元素除以所有元素的和来计算归一化概率分布。softmaxzi∑j1nezj
CVPR2023对抗攻击相关论文
在各种计算机视觉应用中,现实世界的对抗性物理补丁被证明在妥协最先进的模型中是成功的。基于输入梯度或特征分析的现有防御已经被最近基于 GAN 的攻击所破坏,这些攻击会产生自然补丁。在本文中,我们提出了Jedi,这是一种针对对抗性补丁的新防御,它对现实补丁攻击具有弹性。Jedi从信息论的角度解决了补丁定
AI大模型的神经网络模型量化技术:INT8 还是 INT4 ?
如果要量化的目的是实现硬件加速,则应首选确定性量化,因为可以预先指定适当的量化级别,以便在专用硬件上运行量化网络,对硬件的性能预期得到改善。QAT量化方法在付出重新训练的代价后,采用INT4的量化模型应用场合会较大,但稳定性还是需要大量的实验验证,尤其是安全性要求很高的自动驾驶领域,大家不得不慎重考
【Runtimeerror】解决张量维度不匹配报错信息
【Runtimeerror】解决张量维度不匹配报错信息
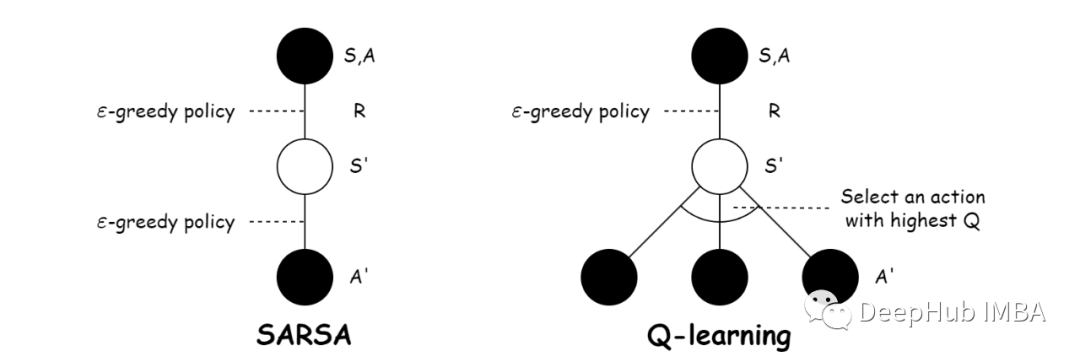
基于时态差分法的强化学习:Sarsa和Q-learning
时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。
适合新手搭建ResNet50残差网络的架构图(最全)
适合新手搭建ResNet50残差网络的架构图+代码(最全),全网最简单详细
什么是GPT模型,GPT下载和国内镜像
什么是GPT模型,GPT模型是通过预训练的方式,采用无监督学习方式,大量语料输入,经过多次训练后得到模型。它能够自动学习并理解自然语言中的语义、句法和语法信息,并可以用于文本生成、对话系统、情感分析、机器翻译等自然语言处理任务中。今天聊聊GPT国内镜像和GPT怎么下载。
Torch对应的torchvision版本
安装torch和torchvision时,两者之间存在依赖关系,版本需要对应起来。
不是Nvidia(英伟达)显卡可以安装CUDA跑深度学习算法吗?
不是Nvidia(英伟达)显卡可以安装CUDA跑深度学习算法吗?
一探究竟:人工智能、机器学习、深度学习
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。人工智能(Artificial Intelligence),简称AI,是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域
SadTalker AI模型使用一张图片与一段音频便可以自动生成视频
SadTalker模型是一个使用图片与音频文件自动合成人物说话动画的开源模型,我们自己给模型一张图片以及一段音频文件,模型会根据音频文件把传递的图片进行人脸的相应动作,比如张嘴,眨眼,移动头部等动作。然后就可以git sadtalker的工程目录,并安装相应的第三方库,这里主要是torch相关的库,
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)
ONNXRuntime介绍及如何使用ONNXRuntime进行模型推理
本文介绍了ONNXRuntime的基本使用方法,包括安装ONNXRuntime、加载模型和进行模型推理。ONNXRuntime提供了简单易用的API,使得使用者可以方便地进行模型推理。同时,其高性能、可扩展、跨平台的特点也让其成为一个优秀的深度学习推理引擎。
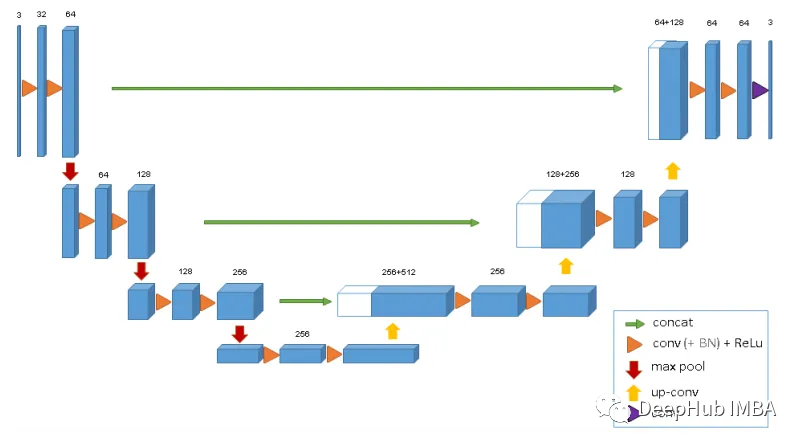
用于3D MRI和CT扫描的深度学习模型总结
本文中将介绍6种神经网络架构,可以使用它们来训练3D医疗数据上的深度学习模型。



