
【深度学习环境】如何查看CUDA版本 | 两个CUDA版本各表示什么 | 是否可以在同一设备安装多个CUDA版本
【深度学习环境】如何查看CUDA版本 | 两个CUDA版本各表示什么 | 是否可以在同一设备安装多个CUDA版本
改进YOLO系列:改进YOLOv8,教你YOLOv8如何添加20多种注意力机制,并实验不同位置。
注意力机制(Attention Mechanism)是深度学习中一种重要的技术,它可以帮助模型更好地关注输入数据中的关键信息,从而提高模型的性能。注意力机制最早在自然语言处理领域的序列到序列(seq2seq)模型中得到广泛应用,后来逐渐扩展到了计算机视觉、语音识别等多个领域。注意力机制的基本思想是为
Wandb是啥,怎么用
使用Wandb非常简单,首先需要安装Wandb的Python包,可以通过pip或conda来安装。安装完成后,需要在Python脚本中导入wandb库,登录Wandb,创建一个项目并设置实验。在实验中,可以记录各种指标、超参数、模型权重等,并进行可视化分析。最后,可以将实验的结果保存在Wandb的云
LabelImg安装使用教程:
LabelImg
CUDA与TensorRT(5)之TensorRT介绍
CUDA与TensorRT(5)之TensorRT介绍
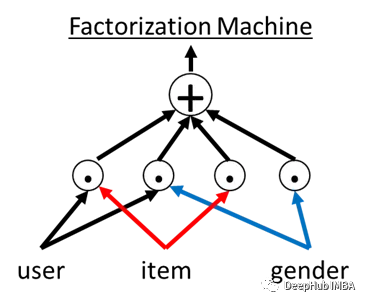
因子分解机介绍和PyTorch代码实现
因子分解机(Factorization Machines,简称FM)是一种用于解决推荐系统、回归和分类等机器学习任务的模型
如何利用ChatGPT进行论文润色-ChatGPT润色文章怎么样
ChatGPT可以润色文章,使用其润色功能可以为用户提供更加整洁、清晰、文采动人的文本。但需要注意以下几点:需要保持文本的一致性和完整性。当使用ChatGPT进行润色时,需要注意保持文本的一致性和完整性。不应改变原始文章的意义、论点和逻辑结构,尤其是在非常规文章类型上,比较灵活的润色方式和人为的润色
手把手教学YOLOV5在RK3568的部署应用及代码实现
YOLOV5模型移植在RK3568
【超详细小白必懂】Pytorch 直接加载ResNet50模型和参数实现迁移学习
【超详细小白必懂】Pytorch 直接加载ResNet50模型和参数实现迁移学习
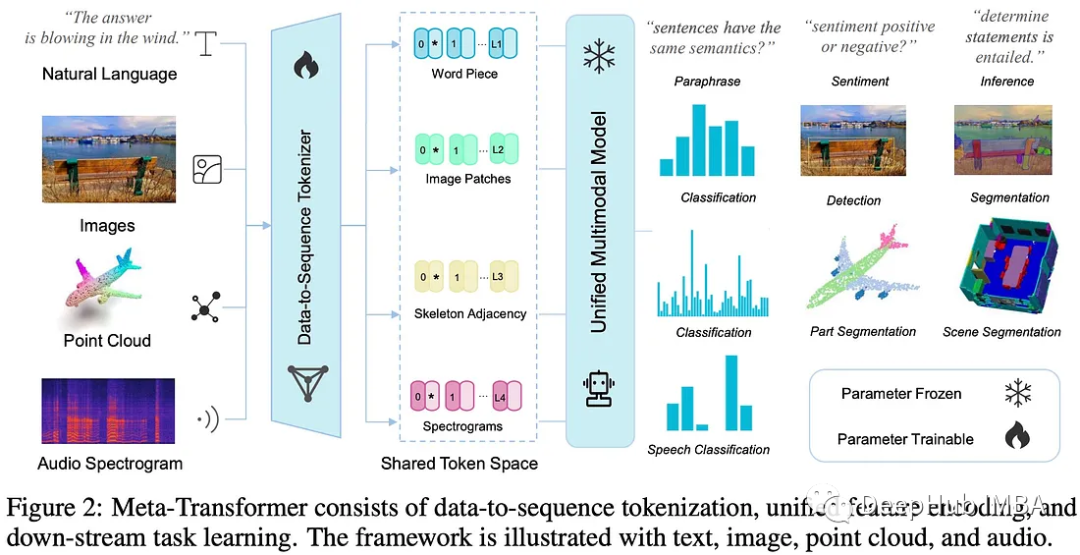
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息
卸载cpu版本的torch并离线安装对应的gpu版本
每次从github上安装项目对应的库,利用requirements.txt安装很容易出现版本不对应的情况,尤其是将torch的gpu版本安装成cpu。这里记录一些查看版本的指令和离线安装的方法,就不用每次百度啦!(注:其他库的离线安装也可以用同样的方法,只需要去相应的网站下载wheel即可)第一个框
Pytorch 多GPU训练
Pytorch 多GPU训练
Darknet53详细原理(含torch版源码)
Darknet53详细原理(含torch版源码)—— cifar10
MSELoss详解+避坑指南
MSELoss详解+避坑指南
【YOLOX简述】
YOLOX简述
YOLOv7改进:在不同位置添加biformer
为了缓解多头自注意力()的可扩展性问题,先前的一些方法提出了不同的稀疏注意力机制,其中每个查询只关注少量的键值对,而非全部。为此,作者探索了一种动态的、查询感知的稀疏注意力机制,其关键思想是在粗糙区域级别过滤掉大部分不相关的键值对,以便只保留一小部分路由区域(这不就把冗余的信息干掉了吗老铁们)。其次
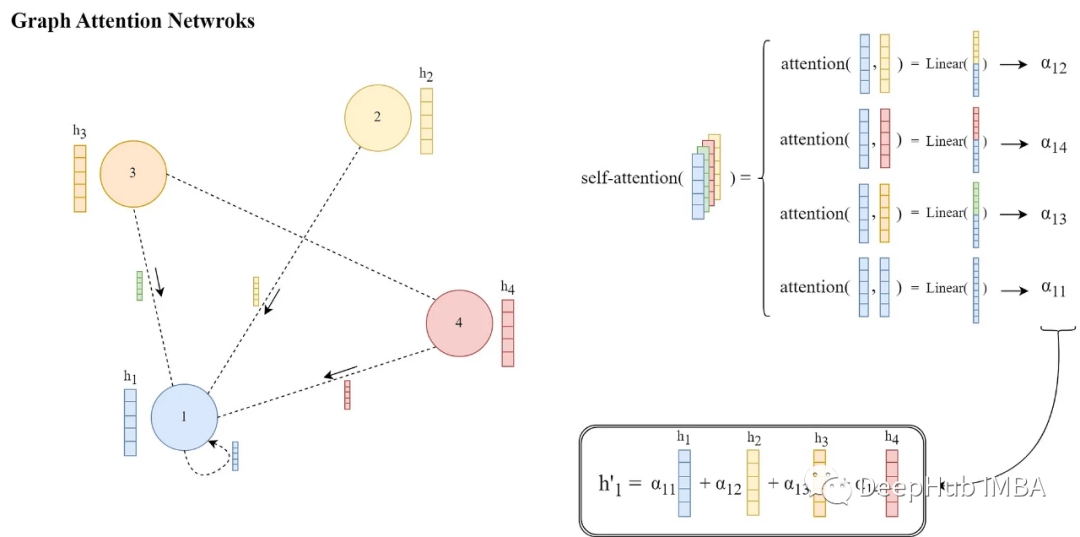
图注意力网络论文详解和PyTorch实现
图注意力网络(GAT)[1]是一类特殊的gnn,主要的改进是消息传递的方式。他们引入了一种可学习的注意力机制,通过在每个源节点和目标节点之间分配权重,
dropout层简介
这就是dropout层的思想了,**为什么dropout能够用于防止过拟合呢?**因为约大的神经网络就越有可能产生过拟合,因此我们随机删除一些神经元就可以防止其过拟合了,也就是让我们拟合的结果没那么准确。dropout顾名思义就是被拿掉的意思,正因为我们在神经网络当中拿掉了一些神经元,所以才叫做dr
A30、V100性能测试对比报告
共压80000数据,同时请求500数据。



