模型量化(6):Yolov5 QAT量化训练
从模型量化(5): 敏感层分析可以看出来,对于yolov5-nano模型,对最后一层detect层进行敏感层分析的时候,发现对检测精度的影响比较大。所以在PTQ/QAT在进行量化时,会跳过这些敏感层。QAT微调的模型,就是PTQ在校准后的模型。从上一小节可以看出如果PTQ中模型训练和量化是分开的,而
深度学习总结——用自己的数据集微调CLIP
在自己的数据集上微调CLIP模型
安装mmcv-full适配torch版本
比如我的cuda版本是10.1,torch版本是1.8.0,mmcv-full安装命令如下。
ByteTracker行人跟踪核心代码解读
byteTracker中因为目标检测和行人跟踪是解耦的,因此这里主要分析的是byteTracker中的代码。也即是分析当给定一帧图片frame_id,给定这帧中的box列表,行人跟踪类是怎么跟踪每条轨迹的。也就是https://github.com/ifzhang/ByteTrack中位于目录tut
查看cudnn&cuda的版本以及对应的tensorflow版本
查看cudnn&cuda的版本以及对应的tensorflow版本
torch安装找不到版本报错
torch安装找不到版本报错的4种解决办法,可按顺序来
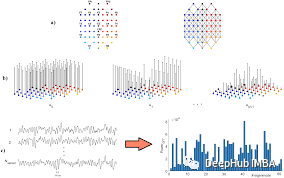
理解图傅里叶变换和图卷积
图神经网络(GNN)代表了一类强大的深度神经网络架构。本文将介绍图卷积的理论基础。深入研究图傅立叶变换的复杂性及其与图卷积的联系
扩散模型原理+DDPM案例代码解析
扩散模型 DDPM 代码实现 从数学公式到代码一步步理解
pytorch分布式训练报错RuntimeError: Socket Timeout
pytorch分布式训练中出现socket timeout情况

微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。
【域泛化综述-2022 TPAMI】Domain Generalization: A Survey
2022TPAMI 域泛化综述阅读
ClearML入门:简化机器学习解决方案的开发和管理
ClearML 是一个开源平台(之前叫TRAINS),可为全球数千个数据科学团队自动化并简化机器学习解决方案的开发和管理。它被设计为端到端的MLOps套件,允许您专注于开发ML代码和自动化,而ClearML确保您的工作可重复和可扩展。仅用 2 行代码跟踪和上传指标和模型创建一个机器人,每当模型的准确
yolov8之导出onnx(二)
yolov8之导出onnx
医学图像的 AI 框架 MONAI 详细教程(一)
最近在读 CVPR 2023 上和医学图像方向相关的论文,发现其中的 Label-Free Liver Tumor Segmentation 这篇论文使用了 MONAI 这个框架。之前关注过的一些医学图像的期刊论文上,也有 MONAI 的出现,加之前的导师有过推荐,所以了解学习了下。简单检索后,发现
Camelyon16数据集切块预处理
本文介绍了Camelyon16数据集切块预处理的过程
Failed to create CUDAExecutionProvider.
Failed to create CUDAExecutionProvider
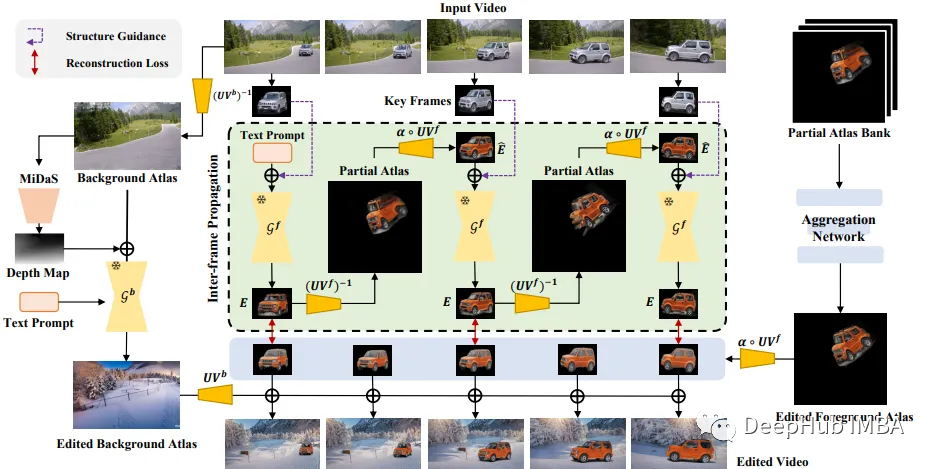
StableVideo:使用Stable Diffusion生成连续无闪烁的视频
使用Stable Diffusion生成视频一直是人们的研究目标,但是我们遇到的最大问题是视频帧和帧之间的闪烁,但是最新的论文则着力解决这个问题。
GPU版pytorch安装成功却无法使用cuda
因为这个大坑,可以说浪费了一整个晚上的时间,在借鉴了很多博客之后,下面这个博主的博客可以说是一个超级好的解决方法。在远程服务器安装pytorch,根据官网命令进行安装,但在完成之后,显示GPU不可用,故记录此大坑。安装结束之后,输入以下代码进行安装验证却显示没有成功安装!按照这个博客的引导,使用pi
nn.TransformerEncoderLayer中的src_mask,src_key_padding_mask解析
注意,不同版本的pytorch,对nn.TransformerEncdoerLayer部分代码差别很大,比如1.8.0版本中没有batch_first参数,而1.10.1版本中就增加了这个参数,笔者这里使用pytorch1.10.1版本实验。
Windows 下 AMD显卡训练模型有救了:pytorch_directml 下运行Transformers
注意,如果直接使用pipeline可能会有问题,应该是pipeline不兼容导致的。只需要自己编写具体代码,避开pipeline即可。amd GPU占用率能上去。



