
YOLOv8算法介绍
YOLOv8
项目地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
YOLOv8
主要有如下的优点:
- 用户友好的
API - 可以同时实现分类、检测、分割和姿态估计任务
- 速度更快、准确率更高
- 全新的结构
- 新的损失函数
Anchor free
模型
**YOLOv5 **
(300epoch)
Params(M)
FLOPs@640(B)
YOLOv8 (500epoch)
Params(M)
FLOPs@640(B)
YOLOX (300epoch)
Params(M)
FLOPs@640(B)
n
28.0
1.9
4.5
37.3
3.2
8.7
s
37.4
7.2
16.5
44.9
11.2
28.6
40.5
9.0
26.8
m
45.4
21.2
49
50.2
25.9
78.9
46.9
25.3
73.8
l
49.0
46.5
109.1
52.9
43.7
165.2
49.7
54.2
155.6
x
50.7
86.7
205.7
53.9
68.2
257.8
51.1
99.1
281.9
YOLOV5;YOLOV8;YOLOX模型对比
2.1 YOLOv8改进概述
- Backbone: 第一层卷积由原本的 6×6 卷积改为 3×3 卷积;参考 YOLOv7 ELAN 设计思想将 C3 模块换成了 C2f 模块,并配合调整了模块的深度。
- Neck:移除了 1×1 卷积的降采样层;同时也将原本的 C3 模块换成了 C2f 模块。
- Head:这部分改动较大,换成了解耦头结构,将分类任务和回归任务解耦;同时也将 Anchor-Based 换成了 Anchor-Free 。
- Loss:使用 BCE Loss 作为分类损失;使用 DFL Loss + CIOU Loss 作为回归损失。
- 样本匹配策略: 采用了 Task-Aligned Assigner 样本分配策略。
- 训练策略:新增加了最后 10 轮关闭 Mosaic 数据增强操作,该操作可以有效的提升精度。
2.2 Backbone

官方代码解析:
**torch.split()**的作用是把一个tensor拆分为多个tensor,相当于是concat的逆过程,定义如下:
torch.split(tensor, split_size_or_sections, dim=0) 第二个参数就是自定义在那个唯独进行切分,YOLOv8中利用split函数实现而不是像其他一些模块利用1*1卷积对同一个tensor降维两次。
由于每个有几个DarknetBottleneck就会分出几个分支作为残差最后concat到一起,所以代码中将每个分支都extend到一个list中,最后将这个list中所有的tensor在通道维度进行堆叠,堆叠后的tensor再经过一个1*1卷积进行降维。
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
2.2 Neck
仍然使用主流的PAFPN,除了将所有的C3模块更换成C2f外,还将YOLOX中上采样前的CBS(Conv+BN+SiLU)模块全都去掉了,C2f模块后直接就进行上采样。如下图所示:
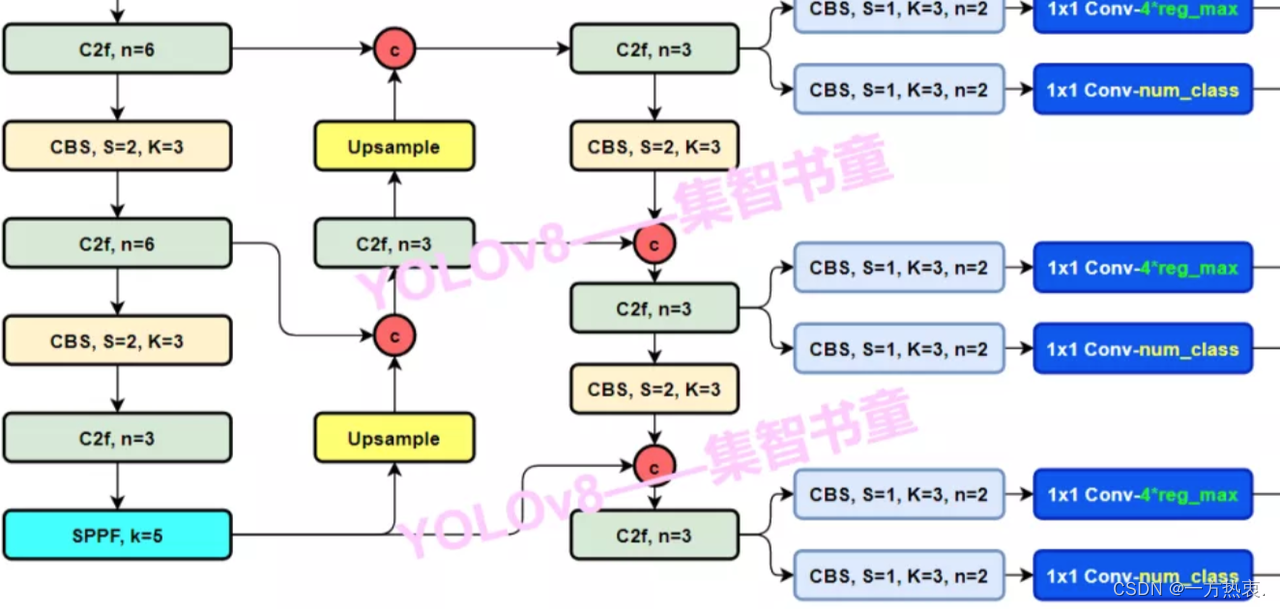
2.3 Head
YOLOv8也不再使用的传统的YOLOhead,开始使用YOLOX提出的Decoupled-Head。将分类和回归任务分离,之前的YOLOhead是合在一起的。双分支目前已经成为主流,例如YOLOv6;PP-YOLOE这些主流的检测器。
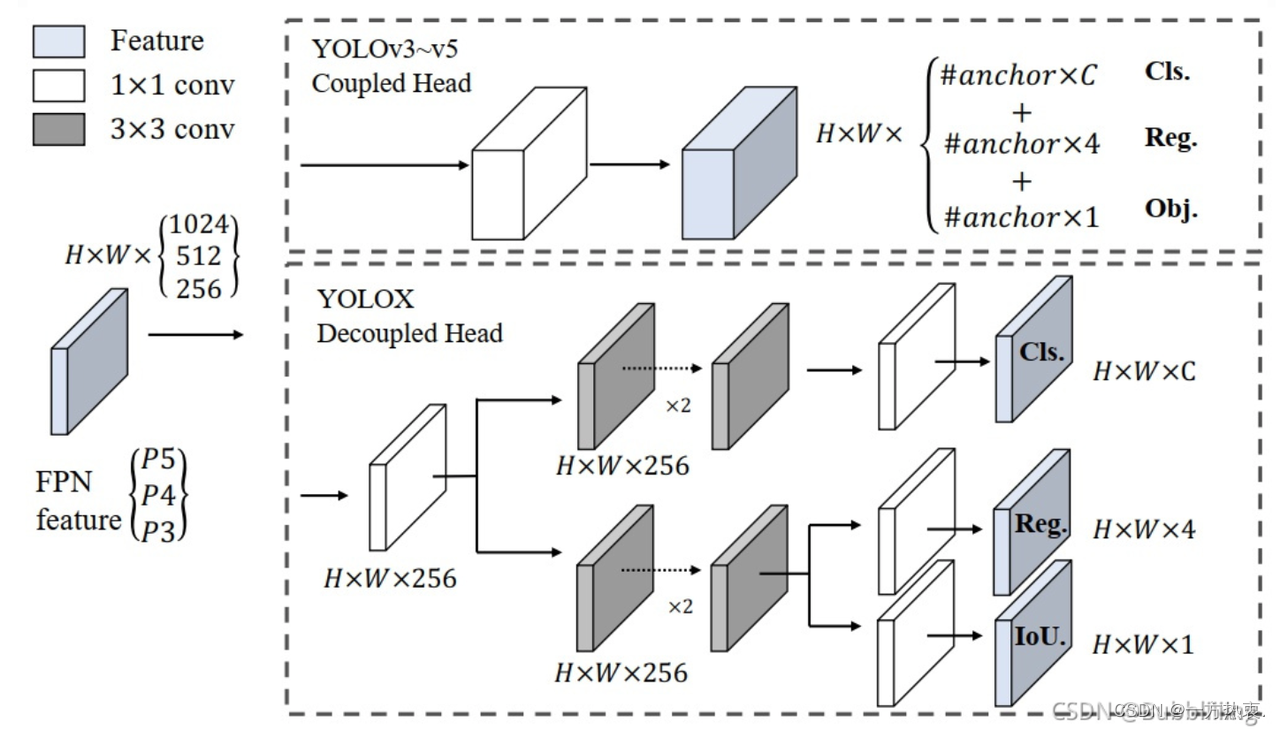
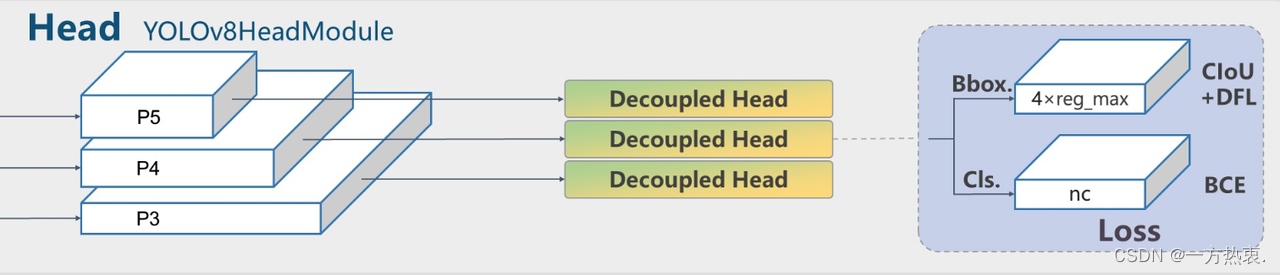
头部的改动是最大的,直接将原本的耦合头改成了解耦头,值得注意力的是,这个解耦头不再有之前的
objectness
分支,而是直接解耦成了两路,并且其回归分支使用了
Distribution Focal Loss
2.4 正负样本分配策略
在目标检测中,正负样本分配策略通常用于在训练期间为每个样本分配一个权重,以便模型更加关注困难的样本和重要的样本。动态分配策略和静态分配策略是两种常见的正负样本分配策略。
静态分配策略通常是在训练开始之前确定的,固定为一组预先定义的权重,这些权重不会在训练过程中改变。这种分配策略通常基于经验得出,可以根据数据集的特点进行调整,但是不够灵活,可能无法充分利用样本的信息,导致训练效果不佳。
相比之下,动态分配策略可以根据训练的进展和样本的特点动态地调整权重。在训练初期,模型可能会很难区分正负样本,因此应该更加关注那些容易被错分的样本。随着训练的进行,模型逐渐变得更加强大,可以更好地区分样本,因此应该逐渐减小困难样本的权重,同时增加易分样本的权重。动态分配策略可以根据训练损失或者其他指标来进行调整,可以更好地适应不同的数据集和模型。
总的来说,动态分配策略通常比静态分配策略更加灵活和高效,可以帮助模型更好地利用样本信息,提高训练效果。
动态样本分配策略:
SimOTA:
SimOTA可以看成是一个最优传输的问题。举一个通俗易懂的例子就是,有2个分配基地与6个周围城市,现在需要考虑一个最优的配送方式来确保分配东西到这几个城市的运输成本是最低的。而对于目标检测来说,这个最优传输问题也就是一个最优分配问题,如何实现把这些anchor point分配给gt的代价(cost)是最低的。这个代价就是iou损失,分类损失等内容,cost公式:
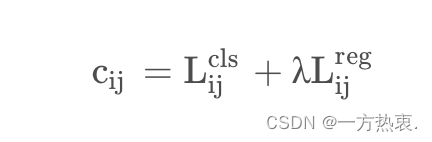
SimOTA步骤如下
- 确定正样本选择区间,选择区间为真实框(绿色)范围加上以真实框中心点为中心构建一个自定义范围的矩形(黄色),正样本将在这个区间进行选择
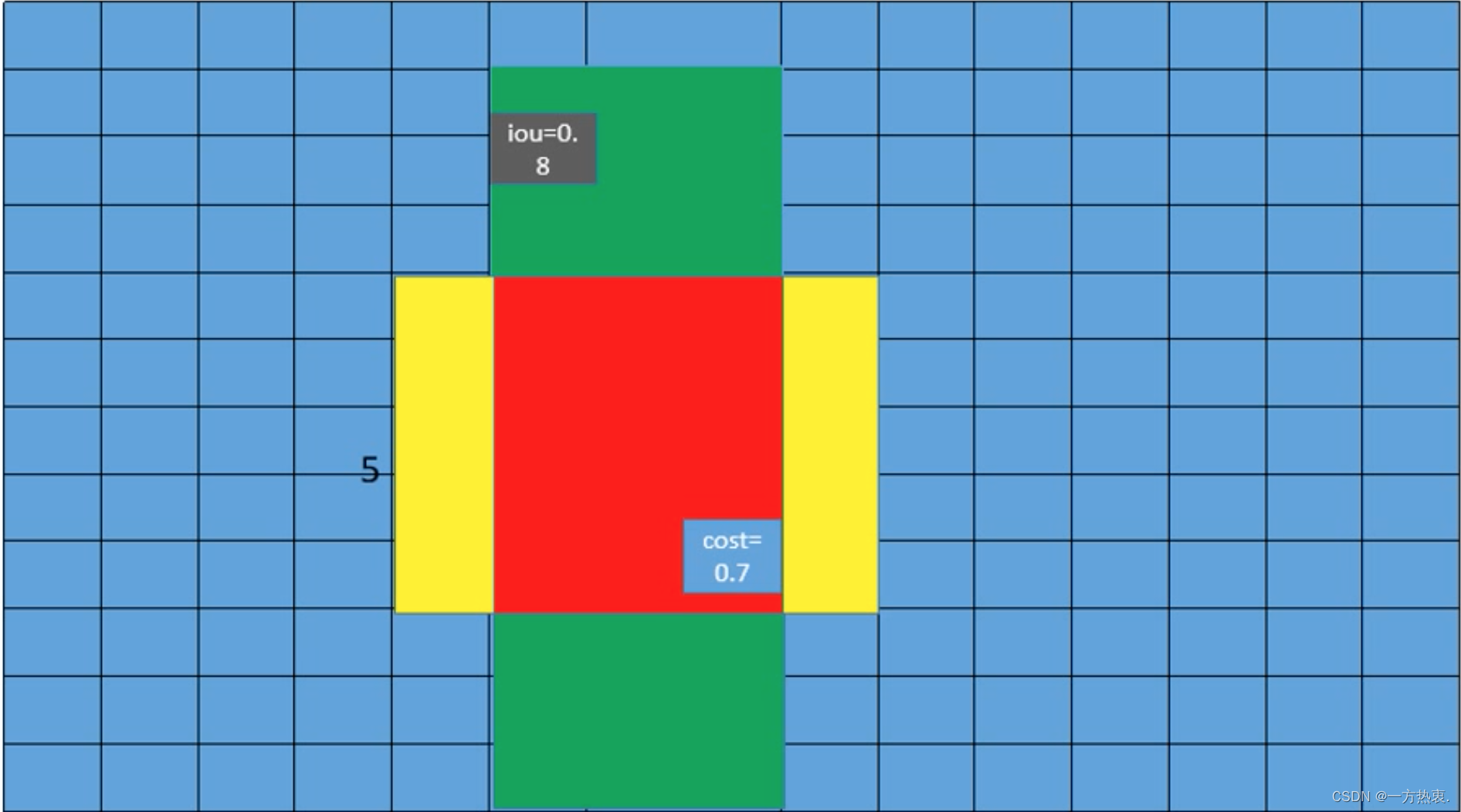
计算其中每一个样本对每个GT的reg+cls loss
计算cost
根据loss计算出cost
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
pair_wise_cls_loss就是每个样本与每个GT之间的分类损失
pair_wise_ious_loss是每个样本与每个GT之间的回归损失
is_in_boxes_and_center代表那些落入GT Bbox与黄色矩形交集内的样本,即上图中红色区域,然后这里进行了取反 ~ 表示不在GT Bbox与黄色矩形区域交集内的样本(黄色区域)接着又乘以100000.0,也就是说对于GT Bbox与黄色矩形交集外的样本cost加上了一个非常大的数,这样在最小化cost过程中会优先选择红色区域样本。
*SimOTA所需要考虑的问题就是,如何筛选出优质的正样本来匹配gt box,从而减少这个匹配过程所产生的代价(cost)*
cost的值应该越小越好,将计算出来的区域内所有cost从小到大进行排序
- 计算IOU
计算区域内所有预测框和真实框的iou,并从大到小进行排序,选取前十个求平均并向下取整得到k ,k的取值范围 (0<k<10)
- 为每个GT分配正样本
根据第四步中的计算iou获得的k,选取前k个cost的对应的预测框作为该GT的正样本
TAL:
任务对齐学习(
Task Alignment Learning
,TAL)最早是在
TOOD
中提出的,其中设计了一个分类分数和预测框质量的统一度量。
IoU
被这个指标替换以分配对象标签。在一定程度上缓解了任务错位(分类和框回归)的问题。
设计了以下度量标准来计算每个实例的锚定级别对齐:
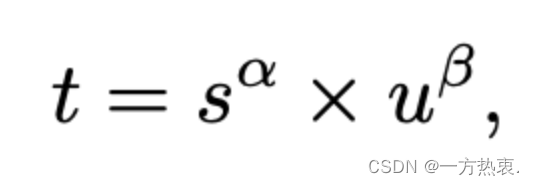
其中s为为分类得分,u为预测框和GT之间的IOU,α和β可以用来控制得分和IoU对这个指标的影响程度,用分类得分和预测框和gt的IoU的高阶组合来表示这个度量t,t 可以同时控制分类得分和 IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。采用一种简单的分配规则选择训练样本:对每个实例,选择 m 个具有最大 t 值的 Anchor 作为正样本,选择其余的 Anchor 作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
2.5 Loss
在介绍CIOU前先回顾一下几种常见的IOU损失
首先IOUloss是最多被使用的一个损失,通过计算IOU(交并比)进行损失计算,但是在IOU等于0的时候代表两个框之间没有任何交集,不能正确反映两者的距离大小例如:
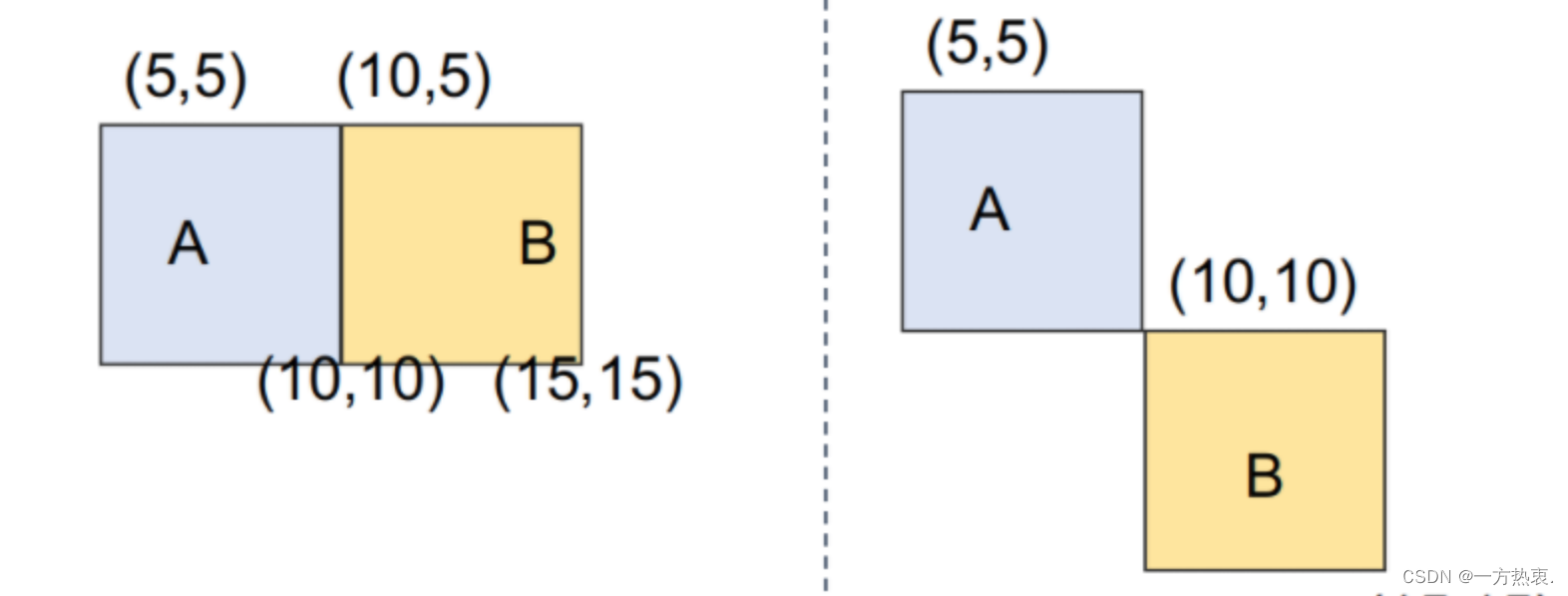
虽然两个框没有任何交集但是经过学习,框还是很有可能拟合的。此外,IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IOU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
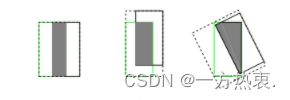
因此为应对IOUloss的缺点提出GIOU:
GIOU公式:
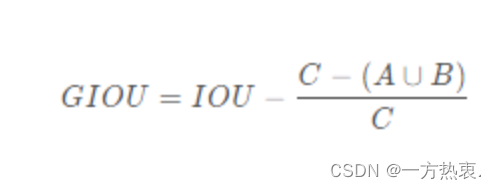
GIOU计算过程如下:
1.假设A为预测框,B为真实框
2.不管A与B是否相交,C是包含A与B的最小框(包含A与B的最小凸闭合框)
3.首先计算IoU,A与B的交并比
4.再计算C框中没有A与B的面积,比上C框面积;
5.IoU减去前面算出的比;得到GIoU

当IOU为0时,意味着A与B非常远时,同理当IOU为1时,两框重合,所以GIOU的取值为(-1, 1]。
GIOU作为loss函数时,为Loss = 1 − GIOU ,当A、B两框不相交时A ∪ B A∪B值不变,最大化G I O U 就是就小化C,这样就会促使两个框不断靠近。
尽管GIoU解决了在IoU作为损失函数时梯度无法计算的问题,且加入了最小外包框作为惩罚项。但是它仍然存在一些问题。例如下面三个图在这种情况下GIOU就会回退回IOU无法评价好坏。

对此,DIOU又被提出:
DIOU公式:
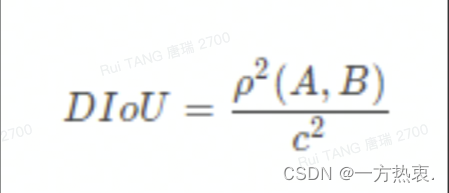
DIOU 在IOU的基础上加入了中心点归一化,将预测框和真实框之间的距离、重叠率、尺度都考虑了进去,能够直接最小化两个检测框之间的距离,使得目标边界框回归变得更加稳定,收敛速度更快。
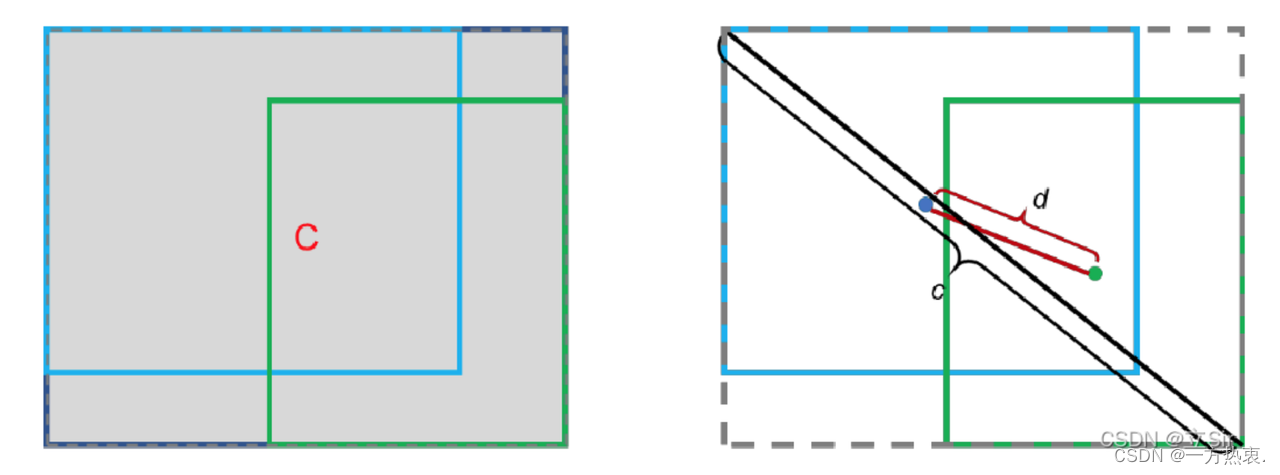
b 代表预测框的中心点坐标,b_gt 代表真实框的中心点坐标,p代表两个中心点之间的欧式距离,c 代表两个目标边界框外接矩形的对角线的长度。公式如下:
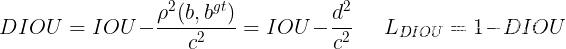
当两个边界框完美重合在一起时,距离d=0,IOU=1,此时DIOU=1。当两个边界框完全分离时,IOU=0,距离d^2 和 c^2 的比值等于1,此时DIOU=-1。因此,DIOU的值域是 [-1, 1],Loss_DIOU 值域是[0, 2]。
其优点如下:
1、DIoU的惩罚项是基于中心点的距离和对角线距离的比值,避免了像GIoU在两框距离较远时,产生较大的外包框,Loss值较大难以优化(因为它的惩罚项是A ∪ B比上最小外包框的面积)。所以DIoU Loss收敛速度会比GIoU Loss快。
2、即使在一个框包含另一个框的情况下,c值不变,但d值也可以进行有效度量。
3、与GIoU loss类似,DIoU loss在与目标框不重叠时,仍然可以为边界框提供移动方向。
4、DIoU loss可以直接最小化两个目标框的距离,而GIOU loss优化的是两个目标框之间的面积,因此比GIoU loss收敛快得多。
5、对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失
一个好的目标框回归损失应该考虑三个重要的几何因素:重叠面积、中心点距离、长宽比。
GIoU:为了归一化坐标尺度,利用IoU,并初步解决IoU为零的情况。
DIoU:DIoU损失同时考虑了边界框的重叠面积和中心点距离。
然而,当两个框如果中心重合时候c,d就不再发生变化。此外,anchor框和目标框之间的长宽比的一致性也是极其重要的。基于此提出YOLOv8中使用的CIOUloss
CIOU:
公式:
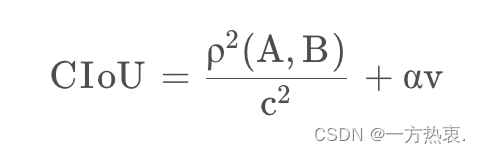
CIOU在DIOU的基础上添加了权重函数并使用v来度量宽高比的一致性:

到这里关于IOU的loss结束
DFL(Distribution Focal Loss)loss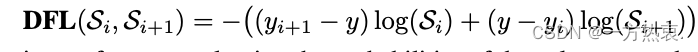
目的让网络快速聚焦到标签附近的数值,使标签处的概率密度尽量大。思想是使用交叉熵函数,来优化标签y附近左右两个位置的概率,使网络分布聚焦到标签值附近。
总体结构图:
版权归原作者 一方热衷. 所有, 如有侵权,请联系我们删除。