
注意,不同版本的pytorch,对nn.TransformerEncdoerLayer部分代码差别很大,比如1.8.0版本中没有batch_first参数,而1.10.1版本中就增加了这个参数,笔者这里使用pytorch1.10.1版本实验。
attention mask
要搞清楚src_mask和src_key_padding_mask的区别,关键在于搞清楚在self-attention中attention mask的作用是啥。
a
t
t
e
t
n
i
o
n
s
c
o
r
e
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
attetnion \ score = softmax({QK^{T} \over \sqrt d_{k} })V
attetnion score=softmax(dkQKT)V
上式中,并没有体现出pad的token,认为所有token都是有用的,但是实际写代码时使用batch进行训练,所以要将所有token序列pad到相同的长度。
attention mask的作用就是,在计算注意力分数的时候,告诉模型,哪些token是pad的,不应该分配注意力分数。
针对一条长度为
L
L
L的token序列,其attention mask的矩阵应该是
L
∗
L
L*L
L∗L,下图是一个attention mask,蓝色的表示不是pad的token,灰色的表示pad的token。
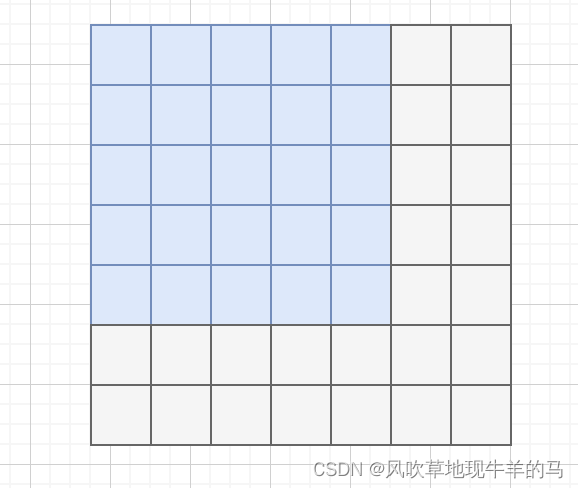
但是针对attention mask中蓝色位置和灰色位置中的值,目前有两种做法:
- 在huggingface的transformers中实现是,将蓝色位置填1 ,灰色位置填0,也就是1表示真实序列,不需要被mask,而0表示pad序列,需要被mask。但是为了用户操作,huggingface并没有要求用户输入一个 B ∗ L ∗ L BLL B∗L∗L的mask矩阵,而是输入 B ∗ L BL B∗L的矩阵即可,然后在forward函数中使用get_extended_attention_mask方法将其扩展为 B ∗ L ∗ L BL*L B∗L∗L的mask矩阵。
- 在pytorch的transformers中的实现是,蓝色的位置填0,灰色的位置填float(“-inf”),但是在实现时,又分为了src_mask和src_key_padding_mask,而最终的attention mask矩阵,是通过这个两个矩阵得到的。 其中:
src_mask: 必须是2D或者3D的矩阵,形状为
[
L
,
S
]
[L,S]
[L,S]或者
[
B
∗
n
u
m
_
h
e
a
d
s
,
L
,
S
]
[B*num\_heads, L, S]
[B∗num_heads,L,S],
L
L
L是目标序列长度,
S
S
S是源序列长度(只有涉及到机器翻译这种encoder-decoder框架目标序列和源序列才有意义,如果只是用transformer encoder做编码,则
L
=
S
L=S
L=S),
B
B
B是batch size,
n
u
m
h
e
a
d
num\ head
num head表示头数。另外src_mask的取值有三种,
- 可以是binary mask,True的位置表示需要被mask,
- 可以是byte mask,非零的位置表示需要被mask,
- 可以float mask,这时float(“-inf”)的位置需要被mask。
src_key_padding_mask:是一个2D的矩阵,形状为
[
B
,
S
]
[B, S]
[B,S],取值有两种,
- 可以是binary mask,True的位置表示key矩阵需要被mask,
- 可以是byte mask,非零的位置表示key矩阵需要被mask,
这里的key矩阵应该也是为了涵盖encoder-decoder这样的情况,对于只用transformer encoder的情况,src_key_padding_mask则更像是huggingface 中的attention mask。
其实在pytorch官方代码中,是通过src_mask和src_key_padding_mask二者综合得到最终的attention_mask。对于绝大多数情况,我们只需要使用src_key_padding_mask即可。
本文转载自: https://blog.csdn.net/mch2869253130/article/details/129521454
版权归原作者 风吹草地现牛羊的马 所有, 如有侵权,请联系我们删除。
版权归原作者 风吹草地现牛羊的马 所有, 如有侵权,请联系我们删除。