
麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上下文能力。
LongLoRA是一种新方法,它使改进大型语言计算机程序变得更容易,成本更低。训练LLM往往需要大量信息和花费大量的时间和计算机能力。使用大量数据(上下文长度为8192)进行训练所需的计算机能力是使用较少数据(上下文长度为2048)的16倍。
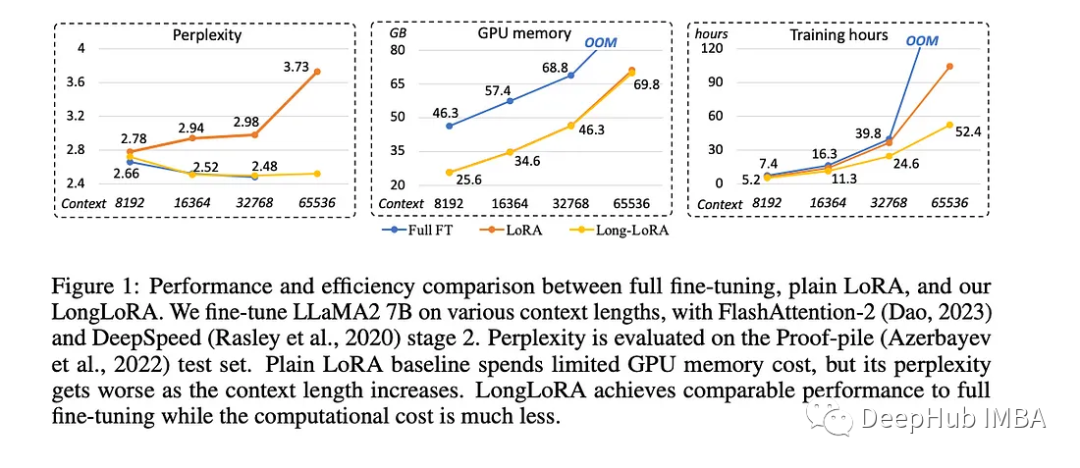
LongLoRA的研究论文中,作者分享了使这一过程更快、更便宜的两个想法。
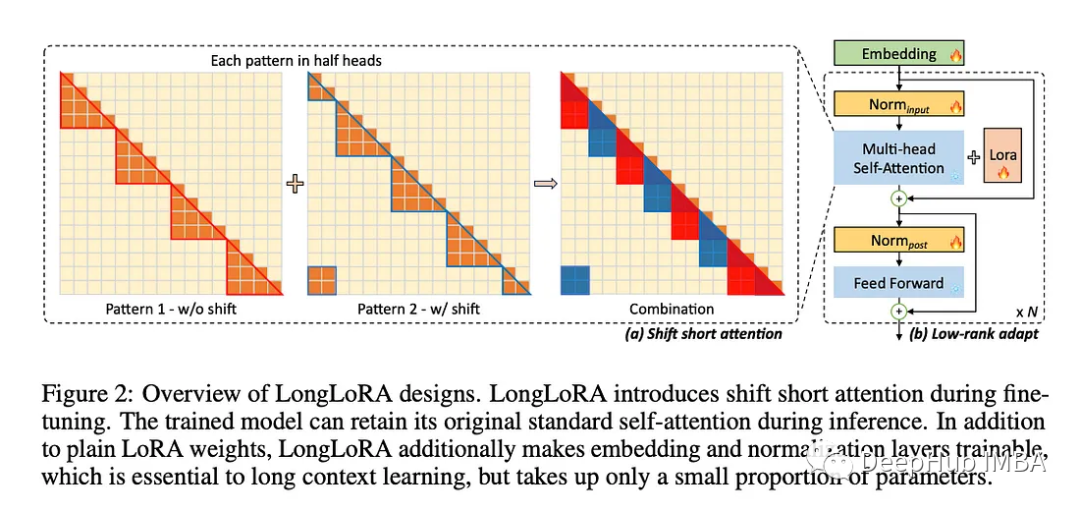
首先,他们在训练中使用一种更简单的注意力形式(专注于特定信息),他们称之为转移短暂注意力(S2-Attn)。这种新的注意力方法有助于节省大量的计算机功率,并且几乎和通常的注意力方法一样有效。
其次,他们重新审视一种有效扩展上下文(用于训练的信息量)的方法。
LongLoRA在各种任务上都显示出很好的效果,可以用于不同规模的llm。它可以将用于训练的数据量从一个模型的4k增加到100k,另一个模型的数据量增加到32k,所有这些都可以在一台功能强大的计算机上完成。
作者还整合了一个名为LongQA的数据集,其中包含3000多对用于训练的问题和答案。这使得LongLoRA成为有效改进大型语言计算机程序的一个非常有用的工具。
LongLoRA
长序列语言建模研究评估了Proof-pile和PG19数据集上的不同模型。研究发现,在训练过程中,随着上下文大小的增加,模型表现得更好,这表明了LongLoRA的微调方法的有效性。简单地说,有更多信息的训练可以带来更好的结果。例如当上下文窗口大小从8192增加到32768时,一个模型的性能在困惑度方面从2.72提高到2.50。
最大上下文长度研究探讨了模型在一台机器上可以处理多少上下文。他们将模型扩展到处理非常长的上下文,并发现模型仍然表现良好,尽管在较小的上下文尺寸下性能有所下降。
除了语言建模之外,该研究还在一个基于检索的任务中测试了这些模型。这个任务中要求在很长的对话中找到特定的主题。模型在这项任务中的表现与最先进的模型相似,甚至在某些情况下表现得更好。与竞争对手相比,他们的模型更有效地适应了开源数据。
LongLoRA表明,大模型能够处理的信息越多,理解语言的能力就越强。并且它不仅擅长处理长文本,而且LongLoRA也非常擅长在长对话中找到特定的主题。这表明它可以处理现实世界中复杂而混乱的任务。
因为加大了上下文窗口,所以LongLoRA在处理较短的文本片段时会有一些问题,这个问题作者还没有找到原因。
总结
最近围绕语言模型(如LLaMA和Falcon)的讨论已经将焦点从仅仅增加模型参数转移到考虑上下文令牌的数量或上下文长度。LongLoRA的出现强调了上下文长度在语言模型的发展中所起的关键作用,为扩展其功能提供了一种经济有效的途径。
我们再总结一下LongLoRA的重点:
LongLoRA是一种新的微调方法,可以在不需要过多计算的情况下提高大型语言模型(llm)的上下文容量。
它采用稀疏的局部关注(S2-Attn)进行上下文扩展,在保持性能的同时降低了计算成本。
LongLoRA将LoRA与可训练的嵌入和规范化相结合,实现了显著的上下文扩展。
在一台机器上,LongLoRA可以将LLaMA2 7B的上下文从4k扩展到100k或LLaMA2 70B的32k。
LongQA数据集增强了监督微调的实用性。
训练过程中更长的上下文大小可以显著提高模型性能。
即使在扩展的上下文中,模型也表现良好,尽管在较小的上下文大小中略有下降。
在基于检索的任务中,配备longlora的模型优于竞争对手,特别是在使用开源数据时。
论文地址:LONGLORA: EFFICIENT FINE-TUNING OF LONG - CONTEXT LARGE LANGUAGE MODELS
https://arxiv.org/pdf/2309.12307v1.pdf
代码,已经可以下载测试了: