Mask RCNN详解
MaskR-CNN是对FasterR-CNN的直观扩展,网络的主干有RPN转换为主干网络为ResNet的添加了一个分支用于预测每个感兴趣区域(RoI)上的分割掩模,与现有的用于分类和边界盒回归的分支并行(图1)。
计算模型的GFLOPs和参数量 & 举例VGG16和DETR
近期忙于写论文,分享一下论文中表格数据的计算方法。FLOPS:注意S是大写,是“每秒所执行的浮点运算次数”(floating-point operations per second)的缩写。它常被用来估算电脑的执行效能,尤其是在使用到大量浮点运算的科学计算领域中。正因为FLOPS字尾的那个S,代表秒
AI遮天传 DL-多层感知机
本文介绍多层感知机,会先按照历史顺序介绍多层感知机诞生前的一些模型,后面介绍具体实现与其算法。
【Make YOLO Great Again】最终版本YOLOv1-v7全系列大解析(全网最详细汇总篇)
全网最详细YOLOv1-v7全系列大解析汇总篇
MMLab
MMLabMMLab的主要研究方向:机器学习、强化学习、半监督/弱监督/自监督学习等方向的前沿方法和理论长视频理解、3D视觉、生成模型等的计算机视觉新兴方向物体检测、动作识别等核心方向的性能突破深度学习的创新应用探索,以及与医疗、社会科学、艺术创作等领域的交叉创新深度学习时代,算法与计算、系统框架、
python3.7安装、Anaconda安装、更新驱动CUDA11.7、安装GPU版本的pytorch
python3.7安装、Anaconda安装、更新驱动CUDA11.7、安装GPU版本的pythorch
绝了,超越YOLOv7、v8,YOLOv6 v3.0正式发布
YOLOv6 全新版本v3.0正式发布!引入新的网络架构和训练方案,其中YOLOv6-S以484 FPS的速度达到45.0% AP,超过YOLOv5-S、YOLOv8-S,其代码刚刚开源。由于前段时间Ultralytics公司透露出V8的发布消息,美团也坐不住了,YOLO社区一直情绪高涨!随着中
深度学习系列25:注意力机制
1. 从embedding到Encoder-Decoder1.1 Embedding首先需要用到embedding,把K维的0-1特征向量用k维的浮点数特征向量表示。直观代码如下:from keras.models import Sequentialfrom keras.layers import
torch.nn.functional.interpolate()函数详解
通常可以使用pytorch中的torch.nn.functional.interpolate()实现插值和上采样。上采样,在深度学习框架中,可以简单理解为任何可以让你的图像变成更高分辨率的技术。input(Tensor):输入张量size(intor Tuple[int] or Tuple[int,
【深度学习】--图像处理中的注意力机制
注意力机制是一个非常有效的trick,注意力机制的实现方式有许多。可以在知网上搜索一下yolov下的目标监测的硕士论文,没有一篇没有提到注意力机制的迭代修改的,所以很有必要学一下,最后给出了一个例子。输入还是等于输出,可是却是已经获取和注意力的特征.正是因为这个特点,所以注意力机制可以任意插拔。 *
超实用的7种 pytorch 网络可视化方法,进来收藏一波
引导前言1. torchsummary2. graphviz + torchviz3. Jupyter Notebook + tensorwatch4. tensorboardX5. netron6. hiddenlayer7. PlotNeuralNet结语前言网络可视化的目的一般是检查网络结构的
毕业设计-基于深度学习火灾烟雾检测识别系统-yolo
毕业设计-基于深度学习火灾烟雾检测识别系统-yolo
YOLOv8项目推理从CPU到GPU
YOLOv8项目推理从CPU到GPU;YOLOv8;从CPU到GPU。

Huggingface微调BART的代码示例:WMT16数据集训练新的标记进行翻译
BART模型是用来预训练seq-to-seq模型的降噪自动编码器(autoencoder)。它是一个序列到序列的模型,具有对损坏文本的双向编码器和一个从左到右的自回归解码器,所以它可以完美的执行翻译任务。
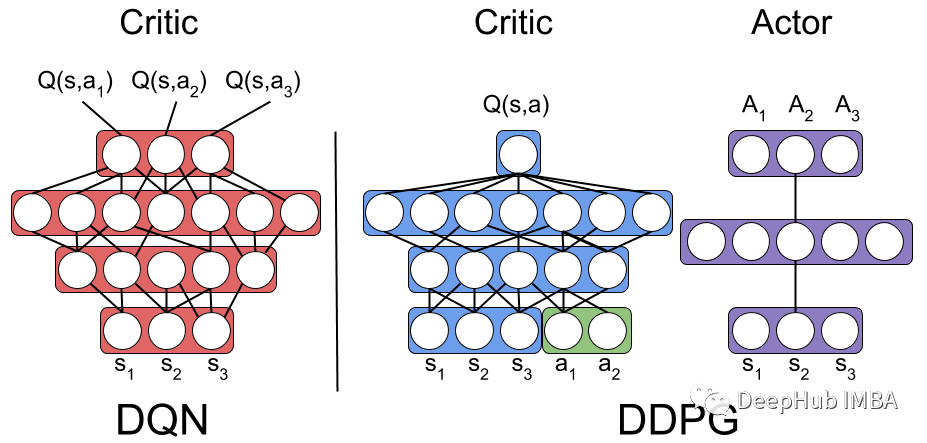
DDPG强化学习的PyTorch代码实现和逐步讲解
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)是受Deep Q-Network启发的无模型、非策略深度强化算法,是基于使用策略梯度的Actor-Critic,本文将使用pytorch对其进行完整的实现和讲解
pytorch2.0安装与体验
pytorch2.0 相对1.x进行了大版本更新,向下兼容!!!!通过官网阅读可知他最大的更新是torch.compile(),通过编译的方式,用一行代码实现模型的稳定加速。这个语句返回一个原来模型的引用,但是将forward函数编译成了一个更优化的版本。PyTorch 2.0 中支撑 torch.

NLP / LLMs中的Temperature 是什么?
ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数
AI风暴 :文心一言 VS GPT-4
AI风暴 :文心一言 VS GPT-4
yolov7数据集格式用于目标识别与实例分割
解释yolov7目标识别与实例分割使用的数据集格式
经典神经网络论文超详细解读(七)——SENet(注意力机制)学习笔记(翻译+精读+代码复现)
SENet论文(《Squeeze-and-Excitation Networks》)超详细解读。翻译+总结。文末有代码复现



