
通常在机器学习面试中,问完常见基础知识的技术问题之后会有具体的项目问题的讨论,所以这里准备了一些项目相关的话题,以可以帮助你准备和通过计算机视觉相关的面试。

计算机视觉的主要任务
- 分类:模型学习图片包含了什么物体
- 目标检测:模型查找对象位置,并且它周围画一个包围框
- 目标跟踪:模型定位对象并查看对象下一步的去向
- 人脸识别:模型知道图像中的人是谁
- 边缘检测:模型知道物体边缘的位置
- 分割-模型知道对象的确切位置,我们可以在它上面创建像素掩码
分割又分为两个主要的小类
- 语义分割:同一类别的所有对象的颜色相同
- 实例分割:每个对象实例都与其他对象实例分开
常见计算机视觉模型和工具
CNN(历史始于上个世纪)-卷积神经网络概念,无论图像上的特征在哪里,它都能检测到,不需要太多的图像预处理
AlexNet (2012)
- ReLU取代了当时的标准tanh(使网络更快)
- 首先使用连续的卷积层
- 第一次使用dropout图层(技术当时刚刚发明)
- 包括多个gpu的优化
- 2012年赢得ILSVRC (ImageNet大规模视觉识别挑战赛),是第一个赢得图像识别比赛的基于gpu的cnn
VGGNet (2014) - CNN使用比AlexNet更小的过滤器,比AlexNet更少的参数,具有更好的性能。
GoogleNet / Inception v1 (2014) - CNN提出了在同一级别上运行的多种大小的过滤器,使网络更宽,而不是更深。2014年赢得ILSVRC(VGG第二)。
ResNet(2015) -残差网络,他解决了梯度消失问题,所以可以更深。并且它的大小更小(由于使用全局平均池化,而不是完全连接的层)。他是2015年获得ILSVRC冠军,并且到现在还在作为基类的模型进行对比
UNet(2015) -用于图像分割的网络,由于u形架构而得名。它的一部分也使用CNN。并且不需要大量的训练数据。
YOLO (2015) - You Only Look Once是一个用于实时目标检测的CNN。最初基于GoogleNet和VGGNet,被称为Darknet。它将输入分割成一个单元格网格,每个单元格预测一个边界框和对象类,然后合并为最终的预测。2015年在ISBI(国际生物医学影像研讨会)多次获得挑战冠军
EfficientNet(2019) -通过“暴力”的超参数搜索,获得比ResNet更强大和准确的结果
上面的每个网络都与CNN架构有关,除此以外还有一些非CNN的网络
GAN(2014年)-生成对抗网络概念,能够生成数据。使用噪声+生成器和鉴别器网络相互竞争,可以使生成器改进生成的输出,使其更接近真实输入,鉴别器尝试猜测输入是真还是假。
ViT(2020年)Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究,目前来说VIT已经做为目标检测和分割的骨干模型。
常用的计算机视觉数据集和工具
ImageNet是最大的数据集之一(每个人都知道)ILSVRC上的许多新的神经网络都是在它上面进行评估的。但是每天都会又更新和更加专业的数据集出现,以下是一些最受欢迎的计算机视觉任务数据集和工具:
图像预处理:我们在将图像输入网络之前或在进行推断之前对图像进行格式化的步骤。它涉及图像变换。
图像变换:改变图像的操作集,如镜像,旋转,裁剪,改变光线或颜色,添加噪声等。例如,在Pytorch中,torchvision.transforms 模块。
数据增强:在训练模型之前,通过创建数据项的更改副本来增加输入数据样本的数量。对于图像是通过图像变换完成的。当我们有一个小数据集时,它是非常有用的,但通常来说,它是一个很好的做法,因为我们希望我们的模型更准确。
下面是fast.ai提供的数据增加强工具的截图:

常见的计算机视觉问题
1、计算机视觉处理流程是什么样子的?
这实际上取决于职位或公司。有人希望你提到数据收集,有人想从任务形式化到部署(尽管这甚至不是你的工作)讨论它,有人只是想在中间听点什么。所以总体看起来是这样的:
任务确认→提取算法和模型架构→数据收集(如果不存在,则标记)→预处理和增强→特征提取→模型训练→推理和测试→分析和优化→更多测试→部署上线→收集反馈→模型改进(在线,离线训练)
2、如何为训练准备图像?
- 检查每个图像是否代表已标记的类或包含所需的数据
- 删除其他可能产生问题的图像
- 图像预处理
- 使用适当的任务转换进行增强
3、什么时候使用灰度图像?
有时颜色与任务无关:比如希望模型学习其他特征,而不是对象的颜色表示,这是一个很好的选择。它不仅可以更好地进行预测,它还会提高模型的性能。例如,如果你训练一个检测骰子上有多少个点的模型——你不需要颜色。不过,如果需要它来进行现实世界中图像分类时,最好还是使用原图。
4、如何评估计算机视觉模型?
机器学习模型常用的评价指标(不仅仅是图像)是:准确率,精度和召回率,F1分数,对于分类来说,与一般的机器学习模型时相同的,但是对于目标检测则有一些特殊的指标:
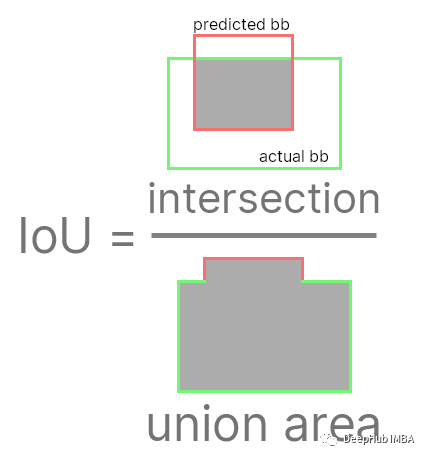
IoU (Intersection over Union):预测边界框的重叠面积与实际边界框的重叠面积与联合边界框的公共面积的比率。通常选择阈值0.5来决定预测是否良好,但这取决于模型要解决的问题。它还解决了一个目标问题的多个预测:只选择一个(最精确的)。
mAP(平均精度均值)——一个借助IoU、精度和召回率以及精确召回率曲线进行统计的度量。我们必须计算一个类的 IoU,然后计算精度和召回率。最后建立一条精度召回曲线,然后计算平均精度(曲线下的面积)并为所有的类进行相同的计算,这样就可以计算出平均值。
5、如何减少图像上的噪声?
高斯滤波器模糊图像并再次锐化它,中值滤波器用周围像素的平均值替换图像中的每个像素
6、如何检测图像中物体的边缘?
为了知道边缘在哪里,必须寻找亮度不连续性或图像梯度。
边缘检测操作可以通过计算来实现:
- 基于高斯的(Canny边缘检测器,高斯拉普拉斯算子)
- 基于梯度的(Sobel算子,Prewitt算子,Robert算子)
在这些算法中,Canny边缘检测算子可能是最流行也是最有效的一种。
CNN网络也用于寻找边缘:在找到所有其他特征之前,通常先找到边缘特征。
神经网络在边缘检测方面也取得了一些进展:
- CASENet(2017)——具有语义边缘检测
- dexine(2020)——不需要事先训练,在不需要微调的情况下可在各种数据集上工作
- RINDNet(2021)——不仅检测边缘,还知道它们的类型:normal, illumination, depth, reflection
- PiDiNet(2021)——轻量级高效的边缘检测
7、计算机视觉的应用领域?
- 医学研究
- 机器人和自动驾驶汽车
- 制造业
- 在其他需要目标检测和跟踪的地方
- 人脸识别
- 教育
- 架构与设计
- 太空研究
这时一个开放性问题,可以根据了解程度来进行回答
以上就是 一些在面试中可能常被问道的话题,希望对你有所帮助
作者:Maryna Klokova