
文档理解是从pdf、图像和Word文档中提取关键信息的技术。这篇文章的目标是提供一个文档理解模型的概述。
文档理解算法使用编码器-解码器结构分析文档内容,该管道结合了计算机视觉(CV)和自然语言处理(NLP)方法。管道的CV部分将文档作为输入图像进行分析,生成transformer可以处理的表示形式。在下图中,CV模型生成图像嵌入,并将其馈送到多模态transformer中。

在以前,卷积神经网络(cnn)如ResNet已经主导了CV领域。最近,类似于NLP架构(如BERT)的VIT作为cnn的替代方法获得了更多的关注。ViTs首先将输入图像分割为若干块,将这些块转换为线性嵌入序列,然后将这些嵌入馈送到transformer 编码器中。这个过程如图2所示。线性嵌入的作用类似于NLP中的令牌。与NLP模型一样,transformer 的输出可用于图像分类等任务。

vit比cnn有几个优势。可以获得全局关系,并对对抗性攻击表现出更强的弹性。缺点是训练vit需要更多的样本,因为cnn有归纳偏差,允许用更少的例子来训练它们。我们可以通过使用大型图像数据集预训练VIT来缓解这个问题。vit也是计算密集型的——运行transformer 所需的计算量随着令牌数量的增加而成倍增长。VIT现在可以作为HuggingFace视觉编码解码器模型的一部分,如下面的代码片段所示。
from transformers import BertConfig, ViTConfig, VisionEncoderDecoderConfig, VisionEncoderDecoderModel
config_encoder = ViTConfig()
config_decoder = BertConfig()
config = VisionEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
model = VisionEncoderDecoderModel(config=config)
视觉编码器解码器为许多文档理解模型提供了基础。Donut[3]模型首先使用图像transformer 处理输入图像,然后将其提供给解码器以生成输入文档的结构化表示。在下面的示例中,我们使用收据的图像,并输出了一个结构化JSON,其中包含了收据的行项。
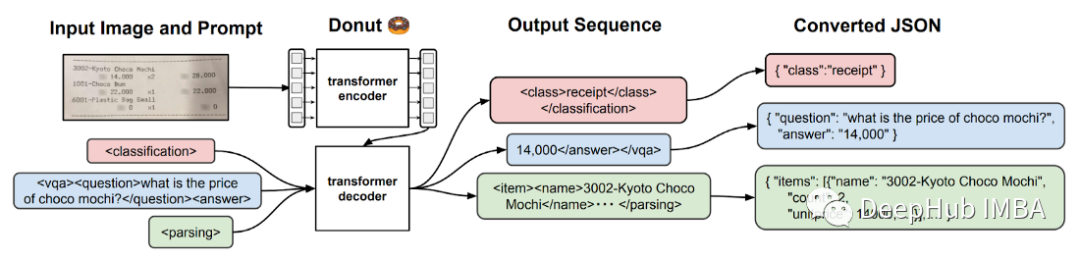
尽管一些文档理解模型(如LayoutLMv3[1])需要预处理来识别边界框并执行OCR,但Donut将输入图像直接转换为目标JSON,如下面的代码所示。这种方法的一个缺点是输出不包括边界框,因此不提供关于提取来自文档中的哪个位置的任何信息。
from donut.model import DonutModel
from PIL import Image
model = DonutModel.from_pretrained("./custom-fine-tuned-model")
prediction = model.inference(
image=Image.open("./example-invoice.jpeg"), prompt="<s_dataset-donut-generated>"
)["predictions"][0]
print(prediction)
{
"InvoiceId": "# 560578",
"VendorName": "THE LIGHT OF DANCE ACADEMY",
"VendorAddress": "680 Connecticut Avenue, Norwalk, CT, 6854, USA",
"InvoiceDate": "4/11/2003",
"AmountDue": "Balance Due:",
"CustomerName": "Eco Financing",
"customerAddress": "2900 Pepperrell Pkwy, Opelika, AL, 36801, USA",
"items": [
{
"Description": "FURminator deShedding Tool",
"Quantity": "5",
"UnitPrice": "$8.09",
"Amount": "$40.46"
},
{
"Description": "Roux Lash & Brow Tint",
"Quantity": "5",
"UnitPrice": "$68.61",
"Amount": "$343.03"
},
{
"Description": "Cranberry Tea by Alvita - 24 Bags",
"Quantity": "1",
"UnitPrice": "$42.30",
"Amount": "$42.30"
}
],
"InvoiceTotal": "$425.79"
}
以上就是文档理解的简介,西洼港对你有所帮助。
作者:Unstructured-IO