
随着机器学习模型的复杂性和能力不断增加。提高大型复杂模型在小数据集性能的一种有效技术是知识蒸馏,它包括训练一个更小、更有效的模型来模仿一个更大的“教师”模型的行为。

在本文中,我们将探索知识蒸馏的概念,以及如何在PyTorch中实现它。我们将看到如何使用它将一个庞大、笨重的模型压缩成一个更小、更高效的模型,并且仍然保留原始模型的准确性和性能。
我们首先定义知识蒸馏要解决的问题。
我们训练了一个大型深度神经网络来执行复杂的任务,比如图像分类或机器翻译。这个模型可能有数千层和数百万个参数,这使得它很难部署在现实应用程序、边缘设备等中。并且这个超大的模型还需要大量的计算资源来运行,这使得它在一些资源受限的平台上无法工作。
解决这个问题的一种方法是使用知识蒸馏将大模型压缩成较小的模型。这个过程包括训练一个较小的模型来模仿给定任务中大型模型的行为。
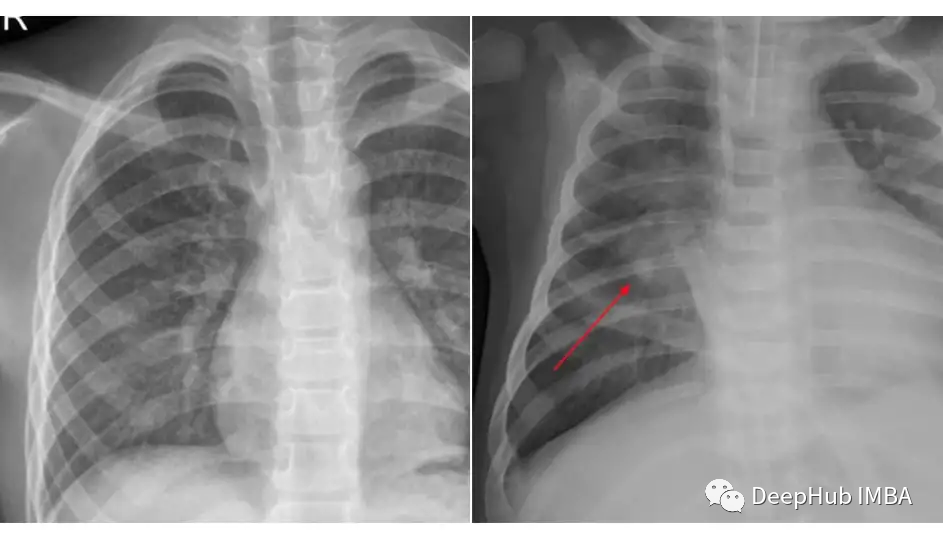
我们将使用来自Kaggle的胸部x光数据集进行肺炎分类来进行知识蒸馏的示例。我们使用的数据集被组织成3个文件夹(train, test, val),并包含每个图像类别的子文件夹(Pneumonia/Normal)。共有5,863张x射线图像(JPEG)和2个类别(肺炎/正常)。
比较一下这两个类的图片:
数据的加载和预处理与我们是否使用知识蒸馏或特定模型无关,代码片段可能如下所示:
transforms_train = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
transforms_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
train_data = ImageFolder(root=train_dir, transform=transforms_train)
test_data = ImageFolder(root=test_dir, transform=transforms_test)
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=True)
教师模型
在这个背景中教师模型我们使用Resnet-18并且在这个数据集上进行了微调。
import torch
import torch.nn as nn
import torchvision
class TeacherNet(nn.Module):
def __init__(self):
super().__init__()
self.model = torchvision.models.resnet18(pretrained=True)
for params in self.model.parameters():
params.requires_grad_ = False
n_filters = self.model.fc.in_features
self.model.fc = nn.Linear(n_filters, 2)
def forward(self, x):
x = self.model(x)
return x
微调训练的代码如下
def train(model, train_loader, test_loader, optimizer, criterion, device):
dataloaders = {'train': train_loader, 'val': test_loader}
for epoch in range(30):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
这是一个标准的微调训练步骤,训练后我们可以看到该模型在测试集上达到了91%的准确性,这也就是我们没有选择更大模型的原因,因为作为测试91的准确率已经足够作为基类模型来使用了。
我们知道模型有1170万个参数,因此不一定能够适应边缘设备或其他特定场景。
学生模型
我们的学生是一个更浅的CNN,只有几层和大约100k个参数。
class StudentNet(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 4, kernel_size=3, padding=1),
nn.BatchNorm2d(4),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Linear(4 * 112 * 112, 2)
def forward(self, x):
out = self.layer1(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
看代码就非常的简单,对吧。
如果我可以简单地训练这个更小的神经网络,我为什么还要费心进行知识蒸馏呢?我们最后会附上我们通过超参数调整等手段从头训练这个网络的结果最为对比。
但是现在我们继续我们的知识蒸馏的步骤
知识蒸馏训练
训练的基本步骤是不变的,但是区别是如何计算最终的训练损失,我们将使用教师模型损失,学生模型的损失和蒸馏损失一起来计算最终的损失。
class DistillationLoss:
def __init__(self):
self.student_loss = nn.CrossEntropyLoss()
self.distillation_loss = nn.KLDivLoss()
self.temperature = 1
self.alpha = 0.25
def __call__(self, student_logits, student_target_loss, teacher_logits):
distillation_loss = self.distillation_loss(F.log_softmax(student_logits / self.temperature, dim=1),
F.softmax(teacher_logits / self.temperature, dim=1))
loss = (1 - self.alpha) * student_target_loss + self.alpha * distillation_loss
return loss
损失函数是下面两个东西的加权和:
- 分类损失,称为student_target_loss
- 蒸馏损失,学生对数和教师对数之间的交叉熵损失
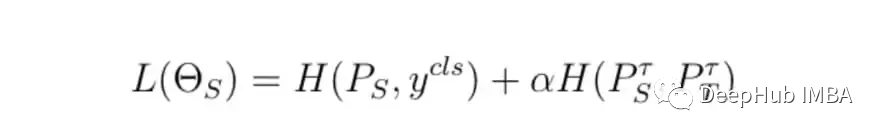
简单的讲,我们的教师模型需要教导学生如何“思考”的,这就是指的是它的不确定性;例如,如果教师模型的最终输出概率是[0.53,0.47],我们希望学生也得到同样类似结果,这些预测之间的差异就是蒸馏损失。
为了控制损失,还有有两个主要参数:
- 蒸馏损失的权重:0意味着我们只考虑蒸馏损失,反之亦然。
- 温度:衡量教师预测的不确定性。
在上面的要点中,alpha和temperature的值都是根据我们尝试过一些组合得到的最佳结果的值。
结果对比
这是这个实验的表格摘要。

我们可以清楚地看到使用更小(99.14%),更浅的CNN所获得的巨大好处:与无蒸馏训练相比,准确率提升了10点,并且比Resnet-18快11倍!也就是说,我们的小模型真的从大模型中学到了有用的东西。
作者:Alessandro Lamberti