Github上的十大RAG(信息检索增强生成)框架
随着对先进人工智能解决方案需求的不断增长,GitHub上涌现出众多开源RAG框架,每一个都提供了独特的功能和特性。
AI教父荣获2024诺贝尔物理学奖:杰弗里·辛顿和他的深度学习之路!
杰弗里·辛顿(Geoffrey Hinton)凭借在人工神经网络领域的开创性研究,获得了2024年诺贝尔物理学奖,这也使得辛顿成为了全世界首个同时获得图灵奖和诺贝尔奖的科学家。
图像生成(Text-to-Image)发展脉络
图像生成(文生图)发展脉络梳理
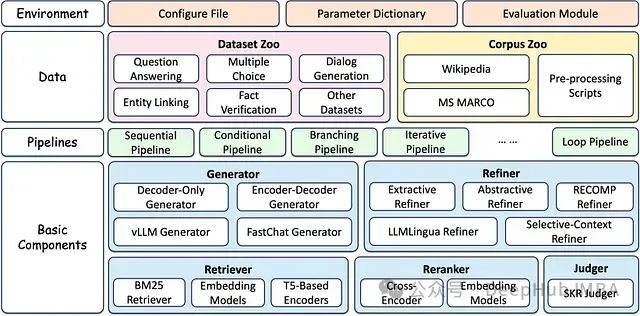
GitHub 上高星 AI 开源项目推荐
GitHub 上高星 AI 开源项目推荐
人工智能深度学习系列—深入解析:均方误差损失(MSE Loss)在深度学习中的应用与实践
在深度学习的世界里,损失函数犹如一把尺子,衡量着模型预测与实际结果之间的差距。均方误差损失(Mean Squared Error Loss,简称MSE Loss)作为回归问题中的常见损失函数,以其简单直观的特点,广泛应用于各种预测任务。本文将带您深入了解MSE Loss的背景、计算方法、使用场景以及
AI大模型系列之七:Transformer架构讲解
Transformer模型设计之初,用于解决机器翻译问题,是完全基于注意力机制构建的编码器-解码器架构,编码器和解码器均由若干个具有相同结构的层叠加而成,每一层的参数不同。编码器主要负责将输入序列转化为一个定长的向量表示,解码器则将这个向量解码为输出序列。Transformer总体架构可分为四个部分
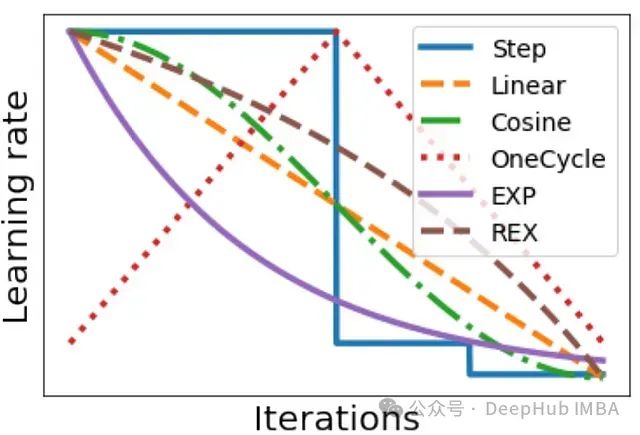
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。
【鸟类识别系统】Python+卷积神经网络算法+人工智能+深度学习+ResNet50算法+计算机课设项目
鸟类识别系统。本系统采用Python作为主要开发语言,通过使用加利福利亚大学开源的200种鸟类图像作为数据集。使用TensorFlow搭建ResNet50卷积神经网络算法模型,然后进行模型的迭代训练,得到一个识别精度较高的模型,然后在保存为本地的H5格式文件。在使用Django开发Web网页端操作界
补充:理解Query、Key和Value
Query(查询)每个输入元素(如单词、字符等)都有一个Query向量。Query向量表示我们正在寻找的信息或特征。在计算注意力权重时,Query用于匹配Key,从而确定关注哪些元素及其重要程度。Key(键)每个输入元素也有一个Key向量。Key向量表示元素的特征或内容。Key用于与Query匹配,
【交通标志识别系统】Python+卷积神经网络算法+人工智能+深度学习+机器学习+算法模型
交通标志识别系统。本系统使用Python作为主要编程语言,在交通标志图像识别功能实现中,基于TensorFlow搭建卷积神经网络算法模型,通过对收集到的58种常见的交通标志图像作为数据集,进行迭代训练最后得到一个识别精度较高的模型文件,然后保存为本地的h5格式文件。再使用Django开发Web网页端
【AI知识点】机器学习中的常用优化算法(梯度下降、SGD、Adam等)
在机器学习中优化算法(Optimization Algorithm) 的任务是找到模型参数(如权重、偏置等),使得损失函数(例如均方误差、交叉熵等)最小化。损失函数度量的是模型预测值与真实标签之间的误差。优化算法通过不断调整模型的参数,使损失函数达到全局或局部最小值。
模型微调参数3——cutoff_len
在大模型的微调过程中,cutoff_len参数用于控制输入文本的截断长度。:模型处理长文本时,计算资源和内存消耗会显著增加。通过设置cutoff_len,可以限制输入文本的最大长度,从而控制内存使用和计算负担。:较长的输入会导致训练时间的增加。截断文本可以加快训练速度,提高训练效率。:长文本可能包含
最全AI简史(中):深度学习时代
2015年,深度学习三巨头Yann LeCun、Yoshua Bengio、Geoffrey Hinton在Nature杂志上发表深度学习综述论文,并与2018年同时获得图灵奖,侧面展现了深度学习对当今时代带来的巨大影响。
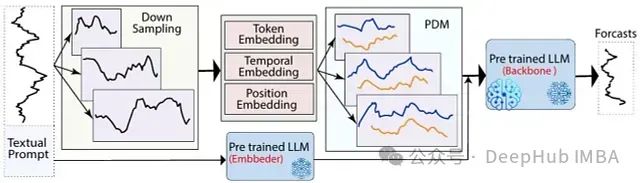
LLM-Mixer: 融合多尺度时间序列分解与预训练模型,可以精准捕捉短期波动与长期趋势
LLM-Mixer通过结合多尺度时间序列分解和预训练的LLMs,提高了时间序列预测的准确性。它利用多个时间分辨率有效地捕捉短期和长期模式,增强了模型的预测能力
用ai写论文查重率高吗?分享4款ai智能写论文软件
其次,AI生成的论文查重率受多种因素影响,包括论文的主题、内容的独特性、所使用的AI工具的能力以及查重系统的特点。通过合理使用这些AI写作工具,并结合个人的研究和观点进行编辑和优化,可以有效降低论文的查重率,提高论文的质量和可信度。3. 文通AI:文通AI是一款专业的AI论文写作工具,覆盖多个学科领
基于深度学习的AI生成式人脸图像鉴别原理
生成式AI模型的主要目标是生成与真实数据分布类似的高质量图像。当前最为流行的生成式模型是生成对抗网络(GANs)。GAN的基本原理是通过生成器和判别器的博弈,使得生成器逐步学会生成越来越逼真的图像。随着技术的发展,GAN和其变种如StyleGAN、BigGAN、CycleGAN等,已经可以生成逼真度
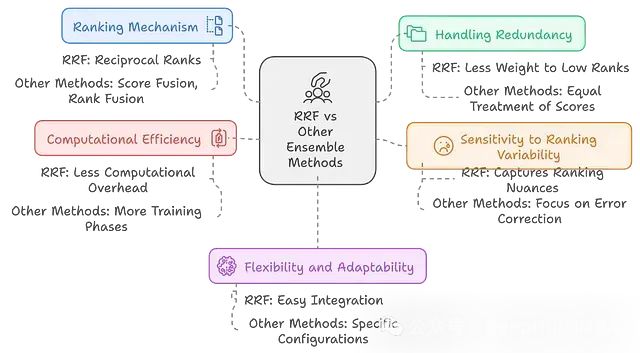
RAPTOR:多模型融合+层次结构 = 检索性能提升20%,结果还更稳健
RAPTOR通过结合多个检索模型,构建层次化的信息组织结构,并采用递归摘要等技术,显著提升了检索系统的性能和适应性。
转置卷积 transposed convolution
通过上面分析,就可以知道为什么通过对输入特征图进行填充使用转置的卷积核并且使用转置卷积核与输入特征图进行步长=1的普通卷积操作就可以得到结果。
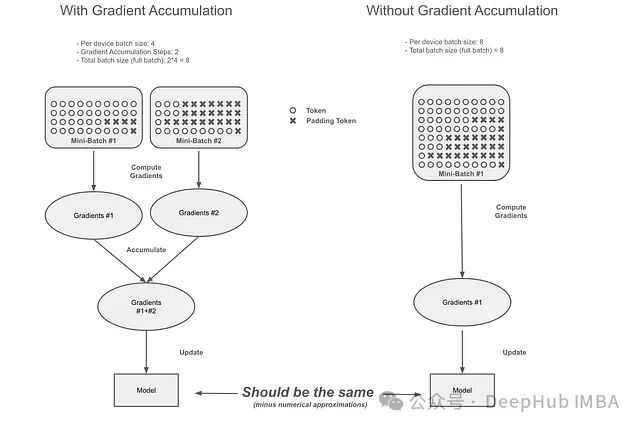
梯度累积的隐藏陷阱:Transformer库中梯度累积机制的缺陷与修正
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。
PRCV2024:可信AI向善发展与智能文档加速构建
在PRCV2024中,合合信息图像算法研发总监郭丰俊老师针对生成式人工智能时代下图像内容安全和智能文档加速的相关技术,分享了自己的独到见解,并介绍了合合信息在这两个方向上取得的进步。接下来,让我们深入了解一下GAI在智能文档领域带来的挑战与机遇。



