
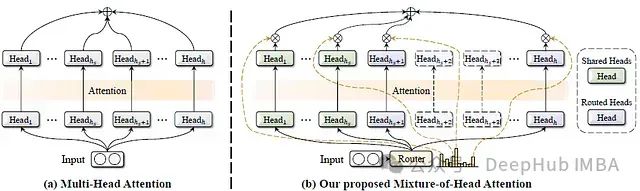
在深度学习领域,多头注意力机制一直是Transformer模型的核心组成部分,在自然语言处理和计算机视觉任务中取得了巨大成功。然而,研究表明并非所有的注意力头都具有同等重要性,许多注意力头可以在不影响模型精度的情况下被剪枝。基于这一洞察,这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。
研究的主要目的包括:
1、提出一种动态注意力头路由机制,使每个token能够自适应地选择适当的注意力头。
2、在不增加参数数量的情况下,提高模型性能和推理效率。
3、验证MoH在各种流行的模型框架中的有效性,包括Vision Transformers (ViT)、Diffusion models with Transformers (DiT)和Large Language Models (LLMs)。
4、探索将预训练的多头注意力模型(如LLaMA3-8B)继续调优为MoH模型的可能性。
方法改进
MoH的核心思想
MoH的核心思想是将注意力头视为混合专家机制(Mixture-of-Experts, MoE)中的专家。具体来说,MoH由以下部分组成:
多个注意力头: H = {H1, H2, ..., Hh},一个路由器: 激活Top-K个头,MoH的输出是K个选定头的输出的加权和:
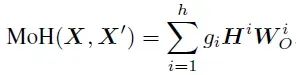
其中gi表示路由分数,只有当第i个注意力头被激活时,gi才非零。
主要改进如下
共享头:
指定一部分头为始终保持激活的共享头。
在共享头中巩固共同知识,减少其他动态路由头之间的冗余。
两阶段路由:
路由分数由每个单独头的分数和与头类型相关的分数共同决定。公式如下:
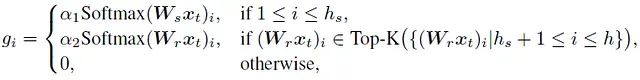
其中hs表示共享头的数量,Ws和Wr分别表示共享头和路由头的投影矩阵。
负载平衡损失:
为避免不平衡负载,应用了负载平衡损失。公式如下:
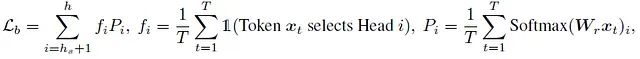
总训练目标:
总训练损失是任务特定损失和负载平衡损失的加权和:
L = Ltask + β * Lb
其中β是权衡超参数,默认设置为0.01。
MoH的优势
使每个token能够选择最相关的注意力头,提高推理效率。通过加权求和替代标准求和,增加了注意力机制的灵活性。无需增加参数数量即可提高模型性能。
实验设置
作者在多个流行的模型框架上评估了MoH的性能:
ViT用于图像分类:
在ImageNet-1K数据集上进行训练和评估。使用AdamW优化器,学习率为1e-3,权重衰减为0.05。训练300个epoch,使用余弦学习率调度器。
DiT用于类条件图像生成:
在ImageNet-1K数据集上进行256×256分辨率的类条件图像生成。使用AdamW优化器,固定学习率为1e-4,无权重衰减。使用指数移动平均(EMA)权重,衰减率为0.9999。
从头训练LLMs:
使用Megatron作为训练框架。在RedPajama、Dolma和Pile等公开数据集上进行训练。使用AdamW优化器,批量大小为400万个token,序列长度为2048。
继续调优LLaMA3-8B:
分两个阶段进行:
使用300B个token继续调优原始LLaMA3-8B模型。使用100B个token将调优后的模型转换为MoH模型。
使用AdamW优化器,批量大小为1600万个token,序列长度为8192。
实验结果
ViT图像分类结果
在ImageNet-1K分类基准测试中:
MoH-ViT-B在仅激活75%的注意力头的情况下,达到了84.9%的Top-1准确率。相比之下,基准模型TransNeXt在激活100%的头的情况下,准确率为84.8%。
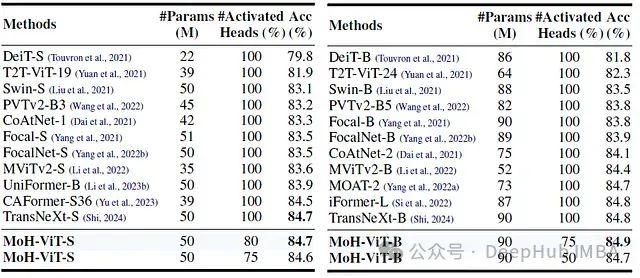
MoH-ViT模型在减少激活的注意力头数量的同时,仍能保持或略微提升性能。即使在仅激活50%头的情况下,MoH-ViT-B的性能仍与使用全部头的TransNeXt-B相当。MoH方法在不同规模的模型中都表现出良好的适应性。
DiT类条件图像生成结果
在ImageNet-1K 256×256分辨率的类条件图像生成任务中:
MoH-DiT模型在激活90%的注意力头的情况下,持续优于原始DiT模型。然而,当仅激活75%的注意力头时,MoH-DiT模型的表现略逊于激活100%注意力头的DiT模型。
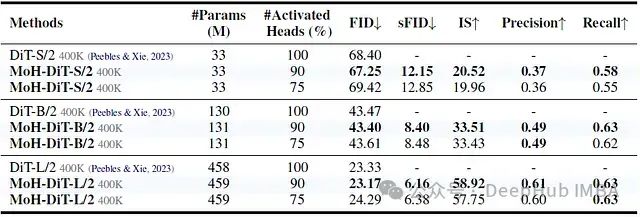
注:FID(Fréchet Inception Distance)越低越好,IS(Inception Score)越高越好。
这些结果揭示了以下几点:
在小型模型(DiT-S/2)中,MoH-DiT在激活90%头的情况下能够略微提升性能。对于大型模型(DiT-XL/2),MoH-DiT在各项指标上都显示出明显的优势。作者认为,图像生成任务对注意力头的依赖似乎比图像分类任务更强,这可能是由于需要捕捉更细粒度的像素级关系。
从头训练LLMs的结果
在多个语言任务基准测试中:
MoH-LLM-S在仅激活50%的注意力头的情况下,达到了45.4%的平均准确率。相比之下,基线模型在激活100%的注意力头的情况下,平均准确率为43.9%。
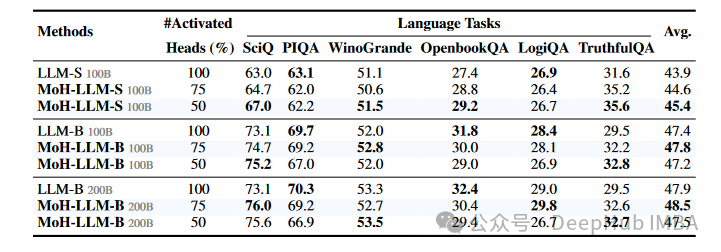
这表明MoH在大语言模型训练中也能有效提高性能和效率。
MoH-LLM在大多数任务中都能够在减少激活头数的同时保持或提升性能。在某些任务(如SciQ和TruthfulQA)上,MoH-LLM显示出明显的优势。对于较小的模型(LLM-S),激活50%的头似乎比激活75%的头效果更好,这可能是由于起到了一定的正则化作用。
继续调优LLaMA3-8B的结果
在14个基准测试中:
MoH-LLaMA3-8B在仅使用75%的注意力头的情况下,达到了64.0%的平均准确率。这比原始LLaMA3-8B模型高出2.4个百分点。
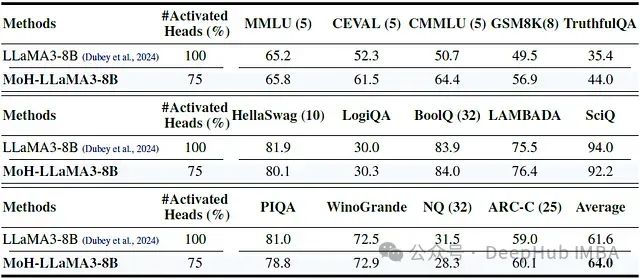
这一结果证明,预训练的多头注意力模型可以成功地继续调优为MoH模型,大大提高了MoH方法的适用性。
MoH-LLaMA3-8B在大多数任务上都超越了原始LLaMA3-8B模型,特别是在CEVAL、CMMLU和TruthfulQA等任务上表现突出。在某些任务(如PIQA和NQ)上,MoH-LLaMA3-8B的性能略有下降,这可能是由于这些任务对特定类型的知识更为敏感。
总体而言,MoH-LLaMA3-8B在仅使用75%注意力头的情况下,平均性能提升了2.4个百分点,这是一个显著的改进。
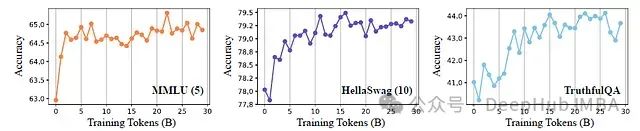
MoH-LLaMA3-8B在继续调优过程中的性能演变
消融实验
作者进行了一系列消融实验,以评估MoH中各个组件的重要性:

这些结果表明:
共享头机制显著提升了模型性能,可能是因为它有效捕捉了常见知识。两阶段路由进一步微调了性能,提供了更灵活的注意力分配策略。
作者还探讨了共享头比例对性能的影响:

这表明模型性能在较广范围的共享头比例下保持稳定,为实际应用提供了灵活性。
最后作者对MoH模型中注意力头的使用情况进行了深入分析。如图3所示,不同类别和任务主题的注意力头分配存在显著差异。
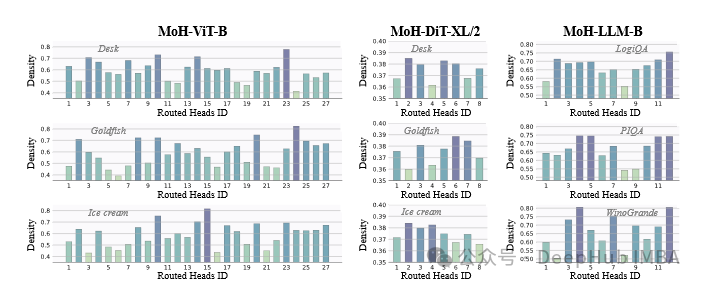
这表明:
MoH模型能够根据不同的任务类型自适应地分配注意力资源。某些头可能专门处理特定类型的信息或特征。这种动态分配机制使得参数利用效率高于标准的多头注意力。
讨论与未来方向
MoH与MoA的比较
作者指出了MoH与之前提出的Mixture-of-Attention (MoA) 方法的几个关键区别:
动机不同:MoH旨在提高注意力机制的效率和性能,而不增加参数数量。MoA则更类似于MoE,目标是在保持推理成本低的同时扩展模型参数。
方法学差异:
MoH引入了共享头和两阶段路由来增强标准MoE方法。MoH证明了预训练的多头注意力模型可以继续调优为MoH模型,大大提高了其适用性。MoA直接将多头注意力与MoE结合,并且由于采用共享键和值,必须从头训练。
应用范围:MoH在多个模型框架(ViT、DiT、仅解码器LLMs)和任务上进行了验证,而MoA仅在编码器-解码器架构的语言任务上进行了验证。
局限性与未来工作
- 异构注意力头:探索在MoH框架中使用不同隐藏大小的注意力头。
- 更低的激活率:目前MoH使用50%~90%的注意力头就能超越多头注意力。未来工作可以尝试进一步降低激活率。
- 多模态输入:研究MoH在处理不同模态输入(如视觉和文本)时的注意力模式。
- 更多下游任务:在更广泛的任务中评估MoH的性能,如音频处理和多模态任务。
- 更大规模模型:将MoH扩展到参数量超过8B的更大模型中。
总结
MoH作为多头注意力的改进版本,在多个任务和模型框架中展现出了卓越的性能和效率。通过引入动态路由机制、共享头和两阶段路由等创新,MoH能够在减少激活头数的同时保持或提升模型性能。特别是MoH能够成功地应用于预训练模型的继续调优,这大大增强了其实用性。
作者认为MoH为开发更先进和高效的基于注意力的模型奠定了坚实的基础,有望在学术研究和工业应用中产生深远影响。未来的工作将进一步探索MoH的潜力,包括在更多样化的任务、更大规模的模型和多模态场景中的应用。