
介绍
意图识别在诸多领域已经有了非常广泛的应用,例如各个品牌的智能语音助手,如今多模态模型能力迅猛增长,与LLM交流方式变得多样化,为了给LLM提供高质量有价值的上下文嵌入信息,引入意图识别变得尤为重要,其不仅能够过滤掉大部分无用但又不得不加入pipline的工具,还可以极大优化整个pipline的响应时间以获得更好的用户体验。
意图识别类似分类任务,意图分类的方法包括CNN、LSTM、基于注意力的CNN、分层注意力网络、对抗性多任务学习。在调研时看到了JointBert论文。
模型架构
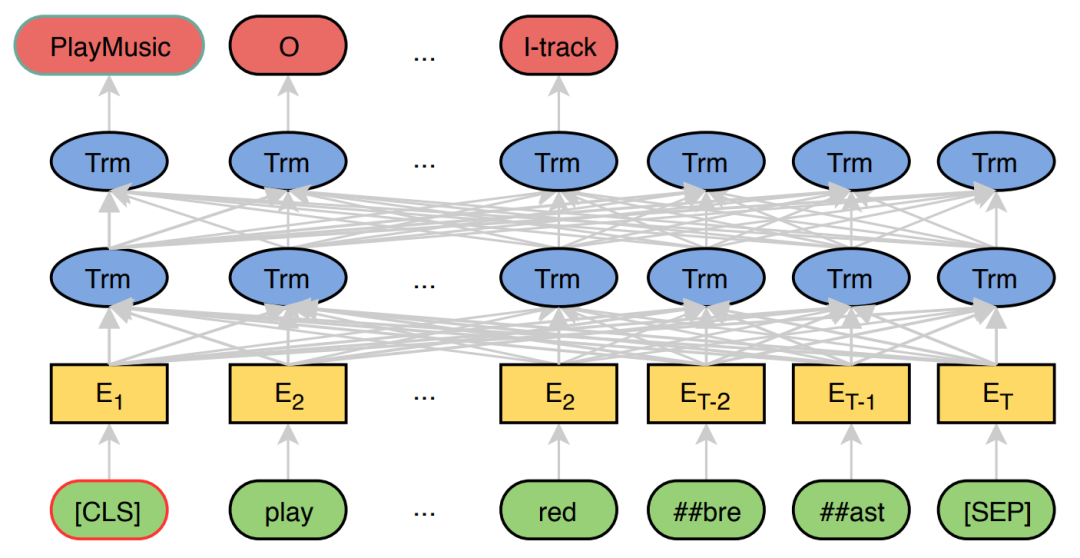
CLS([CLS])是BERT模型中的一个特殊标记(special token),位于输入序列的第一个位置。CLS标记的主要作用是表示整个输入序列的类别。在训练BERT模型时,我们将输入序列的最后一个token传给分类层,这个token就是CLS标记。分类层将这个标记作为输入,输出一个代表序列类别的向量。这个向量在预测阶段被用来判断输入序列所属的类别。
SEP([SEP])是BERT模型中的另一个特殊标记,它位于输入序列的最后一个位置。SEP标记的主要作用是分隔不同的输入序列,使BERT模型能够同时处理多个输入序列。在训练和预测阶段,我们将不同的输入序列用SEP标记分隔开,使BERT模型能够正确地处理它们。
Joint BERT模型基于BERT的架构,利用其强大的双向上下文表示能力。它通过在BERT的基础上进行简单的微调(fine-tuning),来同时处理意图分类和槽位填充任务。Joint BERT模型通过使用BERT的隐藏状态来同时预测意图和填充槽位。具体来说,它使用特殊标记[CLS]的第一个隐藏状态来预测意图,而其他标记的最终隐藏状态则用于通过softmax层分类槽位填充标签。Joint BERT模型的优化目标是最大化条件概率p(yi, ys|x),即给定输入x时,意图yi和槽位序列ys的联合概率。这通过最小化交叉熵损失来实现端到端的微调。为了改进槽位填充性能,论文中还探讨了在Joint BERT模型之上添加条件随机场(CRF)层的效果。CRF可以帮助模型学习槽位标签之间的依赖关系,从而提高槽位填充的准确性。
最佳实践
基础环境
python310
GPU Memory > 4G
得益于Bert模型的优点,我们可以在CPU上进行高效推理
conda create -n intent-cls python=3.10
conda activate intent-cls
git clone https://devops.digitalchina.com/dcg/wuhan/tai/ai-team-demo-subgroup/intent-cls
cd intent-cls
pip install -r requirements.txt
数据准备
项目提供了SMP2019数据集,结构如下
{
"text": "我们下次什么时候再来一起看电影",
"domain": "cinemas",
"intent": "DATE_QUERY",
"slots": {}
}
按照此数据集我造了20条关于与LLM交互时最常见的两种意图,分别为CHAT以及IMAGE_GENERATE
{
"text": "我们能在病毒睡觉时杀死它们吗?",
"domain": "ai",
"intent": "CHAT",
"slots": {}
}
{
"text": "呈现一座巍峨的火山正喷发的壮观景象,熔岩流淌在周围的村庄中,天空被火光染红。",
"domain": "ai",
"intent": "IMAGE_GENERATE",
"slots": {}
}
hyper parameter
lr:5e-4
epoc:10
batch_size:64
adam_epsilon:1e-8
warmup_steps:60
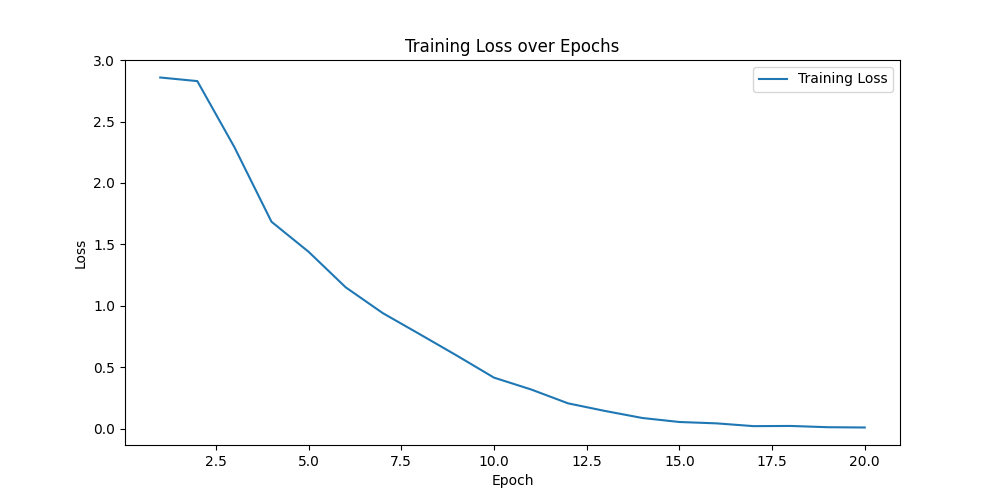
training log
batch_size=64 显存占用 4052MB
[1/20] train loss: 2.8581509590148926 dev acc: 0.3480392156862745 dev intent_avg: 0.25 def slot_avg: 0.09803921568627451 save best model: *
[2/20] train loss: 2.828829526901245 dev acc: 1.0 dev intent_avg: 0.5 def slot_avg: 0.5 save best model: *
[3/20] train loss: 2.2913732528686523 dev acc: 1.0882352941176472 dev intent_avg: 0.5 def slot_avg: 0.5882352941176471 save best model: *
[4/20] train loss: 1.6844485998153687 dev acc: 1.1666666666666665 dev intent_avg: 0.5 def slot_avg: 0.6666666666666666 save best model: *
[5/20] train loss: 1.4401047229766846 dev acc: 1.2745098039215685 dev intent_avg: 0.5 def slot_avg: 0.7745098039215687 save best model: *
[6/20] train loss: 1.1510858535766602 dev acc: 1.4117647058823528 dev intent_avg: 0.5 def slot_avg: 0.9117647058823529 save best model: *
[7/20] train loss: 0.9410368204116821 dev acc: 1.4607843137254903 dev intent_avg: 0.5 def slot_avg: 0.9607843137254902 save best model: *
[8/20] train loss: 0.7689159512519836 dev acc: 1.7058823529411766 dev intent_avg: 0.75 def slot_avg: 0.9558823529411765 save best model: *
[9/20] train loss: 0.5948187112808228 dev acc: 1.7058823529411766 dev intent_avg: 0.75 def slot_avg: 0.9558823529411765 save best model:
[10/20] train loss: 0.4157700538635254 dev acc: 1.7058823529411766 dev intent_avg: 0.75 def slot_avg: 0.9558823529411765 save best model:
[11/20] train loss: 0.31954818964004517 dev acc: 1.7058823529411766 dev intent_avg: 0.75 def slot_avg: 0.9558823529411765 save best model:
[12/20] train loss: 0.20628906786441803 dev acc: 1.7058823529411766 dev intent_avg: 0.75 def slot_avg: 0.9558823529411765 save best model:
[13/20] train loss: 0.14416351914405823 dev acc: 1.9558823529411766 dev intent_avg: 1.0 def slot_avg: 0.9558823529411765 save best model: *
[14/20] train loss: 0.0873243659734726 dev acc: 1.965686274509804 dev intent_avg: 1.0 def slot_avg: 0.9656862745098039 save best model: *
[15/20] train loss: 0.05459991469979286 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model: *
[16/20] train loss: 0.04355735704302788 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model:
[17/20] train loss: 0.02095913328230381 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model:
[18/20] train loss: 0.02244378998875618 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model:
[19/20] train loss: 0.012173544615507126 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model:
[20/20] train loss: 0.009846788831055164 dev acc: 1.9803921568627452 dev intent_avg: 1.0 def slot_avg: 0.9803921568627451 save best model:
last model dev intent_avg: 1.0 def slot_avg: 0.9803921568627451
training loss
模型评估
由于数据集较少,训练集与测试集按照8:2的比例划分,训练后测试集的100%正确率并不能有效说明最终效果。
项目中提供了fastapi的部署脚本,可以快速启动一个异步推理服务,详情请参见README。
请求CURL
curl --location 'http://127.0.0.1:8000/detect' \
--header 'Content-Type: application/json' \
--data '{
"text": "xxxx"
}'
测试结果如下
{
"text": "火箭迟早要上天,为什么不在天上发射?"
},
{
"text": "火箭迟早要上天,为什么不在天上发射?",
"intent": "CHAT",
"slots": {}
}
{
"text": "导盲犬禁止入内,是给盲人看的,还是给导盲犬看的?"
},
{
"text": "导盲犬禁止入内,是给盲人看的,还是给导盲犬看的?",
"intent": "CHAT",
"slots": {}
}
{
"text": "森林,女孩,短发,战靴,光晕"
},
{
"text": "森林,女孩,短发,战靴,光晕",
"intent": "IMAGE_GENERATE",
"slots": {}
}
{
"text": "帮我画一个昏暗的房间,里面有很多魔法阵,魔法阵泛着各种光芒,一位智者正在看书"
},
{
"text": "帮我画一个昏暗的房间,里面有很多魔法阵,魔法阵泛着各种光芒,一位智者正在看书",
"intent": "IMAGE_GENERATE",
"slots": {}
}
补充
这里并没有使用槽位填充,是因为这个场景并不需要信息抽取,只需判断用户意图即可用于后续处理。如若需要信息抽取请按照SMP2019数据集格式给出slot槽位的内容。
意图标签:以txt格式给出,每行一个意图,未识别意图以[UNK]标签表示。以SMP2019为例。
槽位标签:与意图标签类似,以txt格式给出。包括三个特殊标签:[PAD]表示输入序列中的padding token, [UNK]表示未识别序列标签, [O]表示没有槽位的token标签。对于有含义的槽位标签,又分为以'B_'开头的槽位开始的标签, 以及以'I_'开头的其余槽位标记两种。
另外,意图识别数据应需要不断的收集与维护,初始数据集不用很多,但要在项目中做好数据采集与清洗,定期进行模型训练并更新,对于一些bad case需要人为判断缺陷并改善数据集中的类似case,正确率才会越来越高。
版权归原作者 DigitalChina_DCG 所有, 如有侵权,请联系我们删除。