
** 秋招面试专栏推荐 :**深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有60+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
在目标检测领域内,尽管YOLO系列的算法傲视群雄,但在某些方面仍然存在改进的空间。在YOLOv8提取特征的时候,卷积的核是固定的K*K大小,导致参数数量随着大小的增加呈平方级增长。显然,不同数据集和目标的形状及大小各异,而固定形状和大小的卷积核无法灵活适应这种变化。本文给大家带来的教程是将原来的普通的卷积替换为可变核的卷积AKConv。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
1.原理

论文地址: AKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
AKconv 是一种用于卷积神经网络的新型卷积操作方法,其目的是提高网络的特征提取能力,同时解决传统卷积操作中的一些固有局限性。
核心原理:
- 灵活的卷积参数数量: AKconv 提供了灵活的卷积核参数数量,可以让卷积核适应不同形状的目标,而不是像传统卷积那样依赖固定大小和形状的卷积核。这种灵活性可以通过调整卷积核的大小和采样点的数量来实现。
- 任意采样形状: AKconv 可以根据不同的目标动态调整卷积核的采样形状,而不仅仅是固定的正方形采样格子。通过引入偏移(offset),AKconv 能够更好地适应目标的形状变化,从而提高特征提取的准确性。
- 线性增长的参数数量: 与传统的卷积操作不同,AKconv 的卷积参数数量随着卷积核大小的增加呈线性增长,而不是平方增长。这种线性增长有助于降低计算和内存的开销,尤其是在需要大卷积核进行特征提取的情况下。
- 适用于不规则卷积操作: AKconv 能够执行不规则卷积操作,即允许卷积核具有不规则的采样点分布。这种灵活性使得 AKconv 能够更有效地捕获不同尺度和形状的特征,提高卷积神经网络在复杂任务中的表现。
- 与现有卷积操作的兼容性: AKconv 可以无缝替换现有的卷积操作,从而提升网络性能。此外,AKconv 还可以与其他新型卷积模块(如 FasterBlock 和 GSBottleneck)结合使用,进一步增强这些模块的性能。
AKconv 的设计旨在通过提供更大的灵活性和有效性,克服传统卷积操作中的局限性,从而为深度学习中的特征提取提供更强大的工具。AKconv 是一种用于卷积神经网络的新型卷积操作方法,其目的是提高网络的特征提取能力,同时解决传统卷积操作中的一些固有局限性。
2. 将C3_AKConv代码添加到YOLOv8中
2.1 C3_AKConv的代码实现
关键步骤一:将下面的代码粘贴到\yolov5\models\common.py中
from einops import rearrange
import math
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
super(AKConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),
nn.BatchNorm2d(outc),
nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
# generating the inital sampled shapes for the AKConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x, p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0, base_int), indexing='xy')
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x, mod_p_n_y = torch.meshgrid(
torch.arange(row_number, row_number + 1),
torch.arange(0, mod_number),indexing='xy')
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))
p_n = torch.cat([p_n_x, p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride),indexing='xy')
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
# 根据实际情况调整
index = index.clamp(min=0, max=x.shape[-1] - 1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
# using Conv3d
# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)
# using 1 × 1 Conv
# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)
# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)
x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset
class Bottleneck_AKConv(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = AKConv(c_, c2, 3, 1)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3_AKConv(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck_AKConv(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
AKConv 处理图像的主要流程可以分为以下几个关键步骤:
- 初始采样点的生成:
- 首先,AKConv 通过一个算法生成卷积核的初始采样点。这些采样点可以是任意形状和数量,不再局限于传统的正方形格子。生成的采样点既可以是规则的(如标准的 3x3 或 5x5 网格),也可以是不规则的,适应不同卷积核大小和形状的需求。
- 计算偏移量(Offsets):
- AKConv 在处理图像时,会根据输入图像的特征,计算出每个采样点的偏移量。这些偏移量用于动态调整采样点的位置,使得卷积核能够更好地适应图像中的目标形状和尺度变化。偏移量的计算通常通过一个小的神经网络来完成,该网络根据输入图像的特征生成偏移。
- 特征提取:
- 在调整采样点后,AKConv 使用这些经过偏移调整的采样点进行卷积操作,提取图像的局部特征。由于采样点的位置是动态调整的,AKConv 能够捕获更多元和复杂的特征信息,而不仅仅局限于固定位置的局部信息。
- 线性参数增长:
- 与传统卷积核的参数数量随卷积核大小平方增长不同,AKConv 的参数数量随着卷积核大小线性增长。这意味着,在处理大卷积核时,AKConv 仍然能够有效控制计算和内存开销。这一步在处理图像时直接影响到模型的效率和资源使用。
- 输出结果:
- 最终,AKConv 将通过调整后的卷积操作得到的特征图作为输出,这些特征图能够更准确地表示输入图像的内容。与传统卷积操作相比,AKConv 的输出特征具有更高的灵活性和表达力,这为后续的图像分析任务(如分类、检测等)提供了更丰富的信息。
- 集成到网络:
- AKConv 可以作为模块无缝集成到现有的卷积神经网络架构中,替换标准的卷积层以提升整个网络的性能。集成后的网络可以在处理复杂的图像任务时,展示出更强的适应性和更好的表现。
通过以上流程,AKConv 能够在处理图像时更好地捕获和表示图像中的多样性特征,特别是在目标形状和尺度变化较大的场景中,提供了显著的性能提升。

2.2 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_C3_AKConv.yaml并将下面代码复制进去
- 目标检测yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_AKConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 语义分割yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_AKConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
]
温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
2.3 注册模块
关键步骤三:在yolo.py的parse_model函数中注册C3_AKConv

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_C3_AKConv.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments
0 -1 1 7040 models.common.Conv [3, 64, 6, 2, 2]
1 -1 1 73984 models.common.Conv [64, 128, 3, 2]
2 -1 3 156928 models.common.C3 [128, 128, 3]
3 -1 1 295424 models.common.Conv [128, 256, 3, 2]
4 -1 6 1118208 models.common.C3 [256, 256, 6]
5 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
6 -1 9 6433792 models.common.C3 [512, 512, 9]
7 -1 1 4720640 models.common.Conv [512, 1024, 3, 2]
8 -1 3 5336082 models.common.C3_AKConv [1024, 1024, 3]
9 -1 1 2624512 models.common.SPPF [1024, 1024, 5]
10 -1 1 525312 models.common.Conv [1024, 512, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 3 2757632 models.common.C3 [1024, 512, 3, False]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 3 690688 models.common.C3 [512, 256, 3, False]
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 2495488 models.common.C3 [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 9971712 models.common.C3 [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5_C3_AKConv summary: 377 layers, 41928079 parameters, 41928079 gradients, 105.9 GFLOPs
3. 完整代码分享
https://pan.baidu.com/s/1uINNfjTgC8Nx-qsNQf1XGg?pwd=v5g9
提取码: v5g9
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
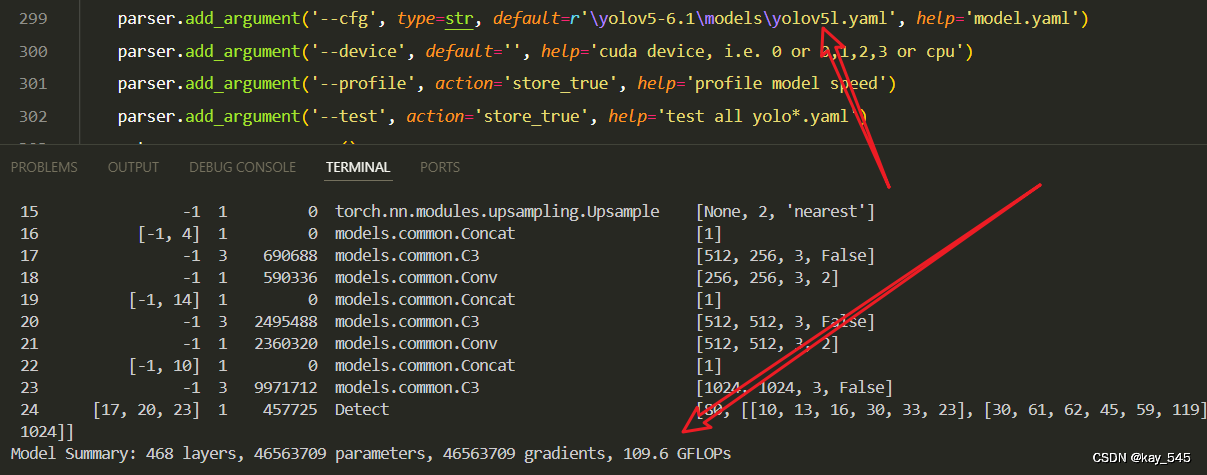
改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
AKConv 的主要原理在于通过灵活调整卷积核的参数数量和采样形状,克服传统卷积操作的局限性,实现更高效的特征提取。具体而言,AKConv 允许卷积核的参数数量随需求线性增长,而非传统的平方增长,这大大减少了计算和内存开销。此外,AKConv 能够动态调整卷积核的采样位置,以适应不同目标的形状变化,从而提高对复杂特征的捕捉能力。它支持不规则的卷积操作,能够灵活处理各种尺寸和形状的卷积核,使得网络在复杂任务中的表现更加出色。最重要的是,AKConv 可以无缝集成到现有的卷积神经网络中,替换传统卷积操作,从而提升网络的整体性能。
版权归原作者 kay_545 所有, 如有侵权,请联系我们删除。