
本文将介绍MemLong,这是一种创新的长文本语言模型生成方法。MemLong通过整合外部检索器来增强模型处理长上下文的能力,从而显著提升了大型语言模型(LLM)在长文本处理任务中的表现。
核心概念
MemLong的设计理念主要包括以下几点:
- 高效扩展LLM上下文窗口的轻量级方法。
- 利用不可训练的外部记忆库存储历史上下文和知识。
- 通过检索相关的块级键值(K-V)对来增强模型输入。
- 适用于各种仅解码器的预训练语言模型。
- 引入额外的记忆检索(ret-mem)组件和检索因果注意力模块。
MemLong的工作流程如图1所示:
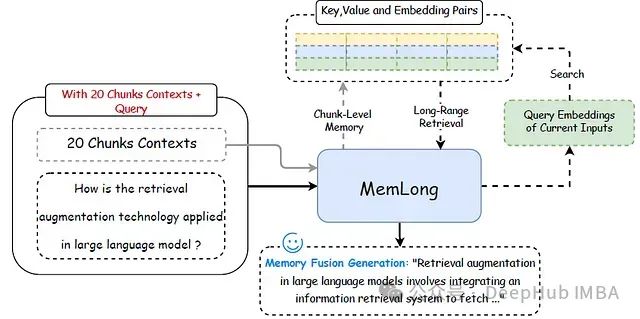
图1:MemLong的记忆和检索过程示意图
MemLong的技术优势
1. 分布一致性
MemLong克服了传统方法中将信息存储在记忆中导致的分布偏移问题。通过精心设计的记忆机制,MemLong确保了缓存信息的分布与原始数据保持一致,从而提高了模型的稳定性和性能。
2. 训练效率
MemLong采用了创新的训练策略:
- 冻结模型的底层参数,仅微调上层结构。
- 显著降低了计算资源需求,例如:- 3B参数版本的MemLong在0.5B个token上的微调仅需8张3090 GPU运行8小时。
这种方法大幅提高了模型的训练效率,使得在有限资源条件下也能实现高效的模型优化。
3. 扩展的上下文窗口
MemLong在处理长文本方面表现出色:
- 能够在单个3090 GPU上将上下文窗口扩展到80k个token。
- 通过仅记忆单层的K-V对,有效控制了内存使用。
这一特性使MemLong在处理长文档、长对话等任务时具有显著优势,能够捕捉更长距离的语义依赖关系。
MemLong架构详解
概述
MemLong的核心架构如图2所示:
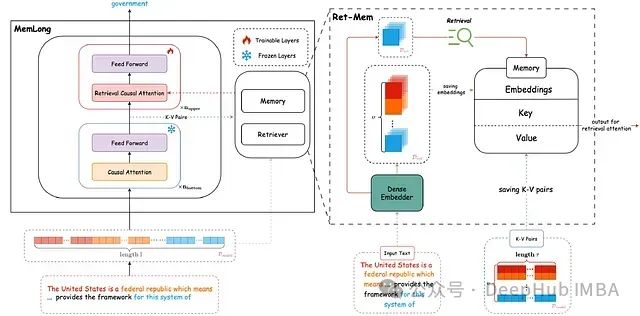
图2:MemLong架构示例
工作流程主要包括以下步骤:
- 输入处理:将输入文本分割成块(ci),每个块对应原始文本ti。
- 底层处理:在冻结的底层中应用标准因果注意力机制。
- 记忆层操作:在最后一个底层(记忆层)后执行两个关键操作:- 检索:利用ti获取最相关的K-V对。- 缓存:存储获得的K-V对及其相关的块表示。
- 上层处理:在可训练的上层中,整合检索到的K-V对与当前输入上下文,并调整模型参数以优化检索过程。
这种设计允许模型有效地利用历史信息,同时保持计算效率和模型的适应性。
在接下来的部分中,我们将深入探讨MemLong的检索器设计、动态记忆管理策略、注意力机制重构以及推理过程等技术细节。
MemLong技术细节
检索器和动态记忆管理
检索过程
MemLong的检索过程是其核心功能之一,具体步骤如下:
- 对于每个查询块cq(等同于ci)及其对应的文本块tq(等同于ti),首先通过检索器R处理,得到表示嵌入rq:rq = R(tq), 其中 rq ∈ Rdret
- 利用得到的表示嵌入,对记忆M中的嵌入进行检索,获取k个最相关的块级索引。
- 计算检索表示rq与记忆M中存储的嵌入之间的余弦相似度。
- 选取相似度最高的k个索引:zq = TopK{Cos(rq)}, 其中 zq ∈ Rk
- 基于获得的索引,从记忆中检索相应的K-V对:˜zq ∈ Rk×τ×dmodel
这种方法允许模型高效地获取与当前输入最相关的历史信息。
记忆过程
记忆过程是MemLong保持长期记忆的关键,其主要特点包括:
- 同步存储:记忆层的K-V对与用于检索的表示嵌入同步存储,确保索引的准确对应。
- 双重存储:- 缓存K-V对- 存储相应的表示
- 一致性保证:由于较低层在训练期间被冻结,输出K-V对的分布保持一致。
- 记忆更新:完成所有块对的检索后,执行记忆操作M(k, v; rm),同步更新记忆中的键值对及其对应表示。
动态记忆更新
为了有效管理长期记忆并防止记忆溢出,MemLong采用了动态记忆更新策略:
- 记忆分配:- 保留最新的10%记忆内容(可能相关)- 丢弃最旧的10%(可能已过时)- 根据检索频率优先考虑中间80%
- 内存控制:当记忆使用超过阈值时,删除最少访问的条目,直到使用率降至50%。
- 平衡机制:这种选择性修剪在保留有价值信息和删除不相关数据之间取得平衡。
- 效率保证:动态更新有效控制记忆大小,防止内存不足,同时保持检索效率。
注意力机制重构
MemLong对传统注意力机制进行了创新性的重构,以更好地融合长期记忆:
检索因果注意力
- 联合注意力机制:将标准注意力扩展为包含本地和长期记忆的联合机制。
- 长期记忆融合:使每个token能够同时关注局部上下文和具有完整连续语义的块级历史上下文。
- 双向注意力:通过检索方法获得的块级K-V对支持双向注意力,同时避免信息泄露。
图3展示了检索因果注意力的工作原理:
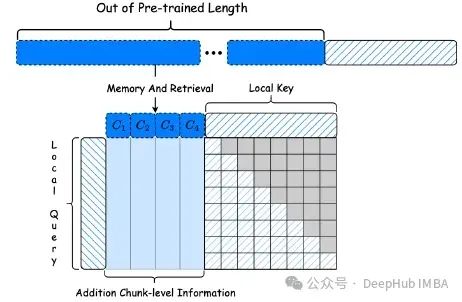
图3:检索因果注意力示意图
注意力计算
给定前一层的头部隐藏状态输出Hl−1 ∈ R|x|×dmodel和检索到的键值对˜zq = { ˜Ki, ˜ Vi} ωi=1 ∈ Rk×τ×dmodel,下一层的输出隐藏状态Hl的计算如下:
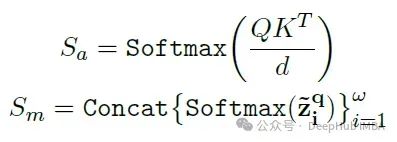
为避免训练初期检索注意力分数Sm可能造成的干扰,MemLong采用多头注意力机制:
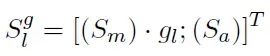
最终,通过连接˜V和V得到Hl:
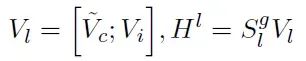
这种注意力机制设计允许模型有效地整合局部和长期信息,提高了对长距离依赖的建模能力。
MemLong推理过程
MemLong在处理超长输入时采用了特殊的推理策略:
- 输入分割:将输入分为前缀和主体两部分。
- 前缀处理:- 将前缀分成多个非重叠的块- 通过记忆层处理每个块,确保参与注意力的token数量等于块大小- 注意块间的相互关联性(第t个块需要处理前t-1个块的信息)
- 主体处理:- 为主体选择k个最相关的块,基于块级检索表示- 获取这些块的键和值表示
- 上层检索:在上层检索层中,注意力窗口大小为k * τ,通常小于输入总长度。
- 高效执行:同时进行长度受限的因果注意力和检索注意力计算。
这种策略使MemLong能够高效处理远超其预训练长度的输入,同时保持计算效率和内存使用的平衡。
在下一部分中,我们将详细介绍MemLong的实验设置和结果,展示其在各种长文本任务中的优越性能。
MemLong实验评估与结论
实验设置
实现细节
训练配置
- 基础模型:使用带有旋转位置编码的OpenLLaMA-3B作为预训练骨干网络。
- 训练规模:在0.5B个token上进行检索增强适应训练,序列长度设置为1024。
位置编码策略
为了适应MemLong的特殊架构,采用了以下位置编码策略:
- 局部上下文(最多2048个token):使用标准的旋转位置编码。
- 记忆键:被编码为在局部上下文窗口中位置为0。
这种策略确保了模型能够有效区分和利用局部和长期信息。
评估数据集
为全面评估MemLong的性能,选择了四个广泛使用的长文本基准数据集:
- PG-19:英语图书数据集
- BookCorpus:另一个英语图书数据集
- Wikitext-103:维基百科文章集
- Proof-Pile:数学论文集
这些数据集涵盖了不同领域和文体的长文本,为模型的泛化能力提供了全面的测试。
评估指标
主要使用困惑度(Perplexity, PPL)作为评估指标。对每个序列的最后2048个token计算PPL,较低的PPL值表示更强的语言建模能力。
基线模型
选择OpenLLaMA-3B作为主要基线模型,同时与LLaMA-2-7B等其他模型进行了对比。
实验结果与分析
长上下文语言建模
图7展示了MemLong与基线模型在不同数据集和输入长度下的性能比较:
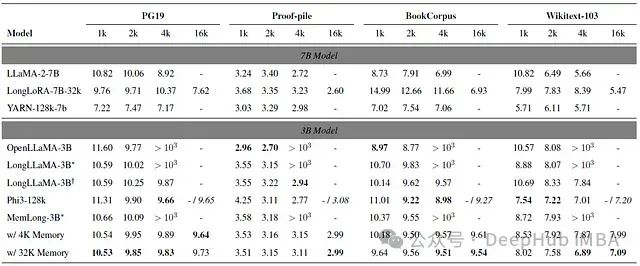
图7:不同模型在各数据集上的困惑度(PPL)比较
关键发现:
- 预训练长度内的性能:在不超过预训练长度(OpenLLaMA-3B为2048,LLaMA-2-7B为4096)的测试中,MemLong与完全微调的模型表现相当。
- 超长输入处理能力:- MemLong在超过预训练和微调长度的输入上仍能持续降低困惑度,展现出优秀的泛化能力。- 相比之下,OpenLLaMA-3B和LLaMA-2-7B在超出预训练长度的输入上表现明显下降。
- 计算效率:- MemLong通过外部检索器有效处理长输入,同时保持较低的内存开销。- 传统模型在处理超长输入时,由于注意力机制的二次复杂度,内存消耗显著增加。
- 一致性改进:MemLong在各个数据集上都实现了困惑度的降低,表明其方法的有效性和稳定性。
上下文学习能力
表1展示了MemLong在5个NLU任务上的少样本学习(4-shot和20-shot)性能:
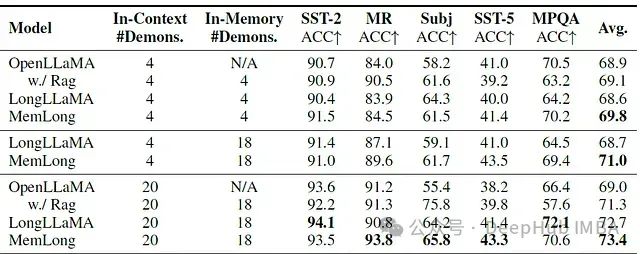
表1:不同模型在NLU任务上的少样本学习准确率(%)
关键观察:
- 记忆利用:与仅依赖非参数知识的OpenLLaMA相比,MemLong能有效利用存储在记忆中的额外示例,提高性能。
- 示例数量影响:随着记忆中示例数量的增加,MemLong的性能进一步提升或保持稳定,显示出良好的可扩展性。
- 与LongLLaMA对比:在相同的内存演示条件下,MemLong在大多数数据集上优于LongLLaMA,证明了其记忆机制的优越性。
- 任务适应性:MemLong在不同类型的NLU任务中均表现出色,表明其具有广泛的应用潜力。
局限性讨论
尽管MemLong展现出优秀的性能,研究团队也认识到以下局限性:
- 模型规模限制:当前研究主要集中在OpenLLaMA-3B上,未来需要在更大规模的模型上进行验证。
- 信息稳定性:观察到单层K-V对提供的额外语义信息可能存在不稳定性,这一问题需要在未来的研究中进一步探讨和解决。
- 领域特异性:虽然在多个数据集上进行了测试,但可能还需要在更多特定领域的任务中评估MemLong的表现。
- 计算复杂度:虽然MemLong相对高效,但在处理极长文本时的计算需求仍需进一步优化。
总结
MemLong作为一种创新的长文本处理方法,在以下方面展现了显著优势:
- 上下文扩展:成功将模型的有效上下文窗口从2k扩展到80k个token,大幅提升了长文本处理能力。
- 性能提升:在长距离文本建模和理解任务中,MemLong展现出明显的竞争优势,相比全上下文模型,在某些任务中实现了高达10.4个百分点的性能改进。
- 效率平衡:通过创新的记忆和检索机制,MemLong在保持高性能的同时,有效控制了计算复杂度和内存使用。
- 广泛适用性:在多种NLU任务和不同类型的长文本数据集上均表现出色,显示出良好的泛化能力。
MemLong的成功为长文本语言模型的发展开辟了新的方向,其核心思想和技术可能对未来的大规模语言模型设计产生深远影响。未来的研究方向可能包括进一步优化记忆机制、探索更大规模模型的应用,以及在更多领域特定任务中的表现验证。