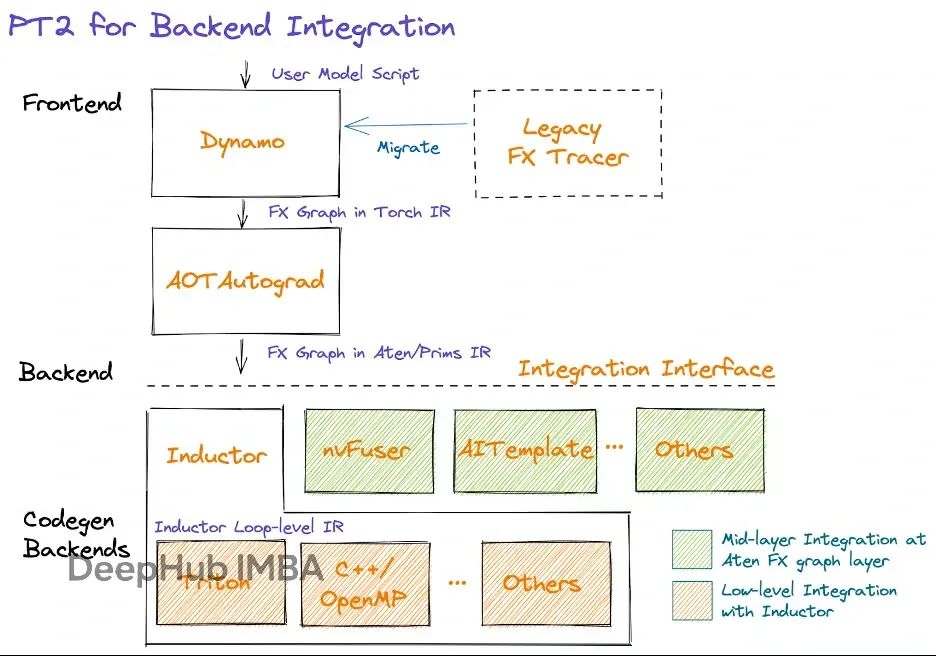
PyTorch 2.0性能优化实战:4种常见代码错误严重拖慢模型
我们将深入探讨图中断(graph breaks)和多图问题对性能的负面影响,并分析PyTorch模型开发中应当避免的常见错误模式。
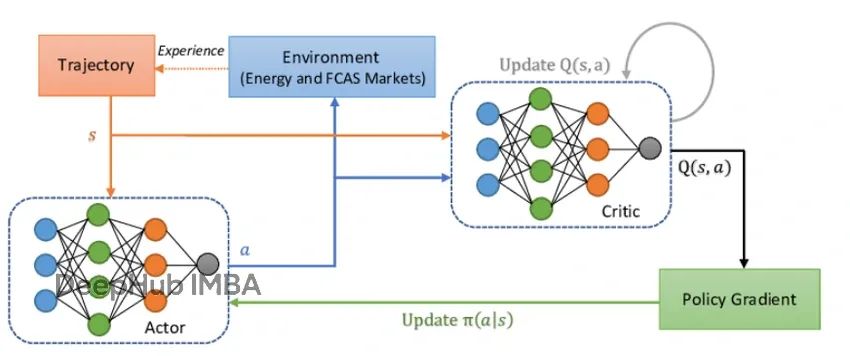
近端策略优化算法PPO的核心概念和PyTorch实现详解
本文提供了PPO算法的完整PyTorch实现方案,涵盖了从理论基础到实际应用的全流程。
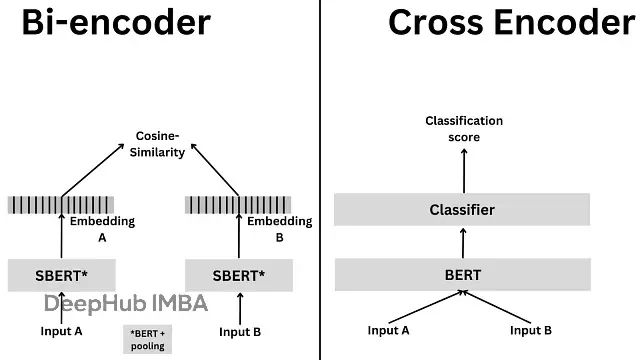
RAG系统文本检索优化:Cross-Encoder与Bi-Encoder架构技术对比与选择指南
本文将深入分析这两种编码架构的技术原理、数学基础、实现流程以及各自的优势与局限性,并探讨混合架构的应用策略。
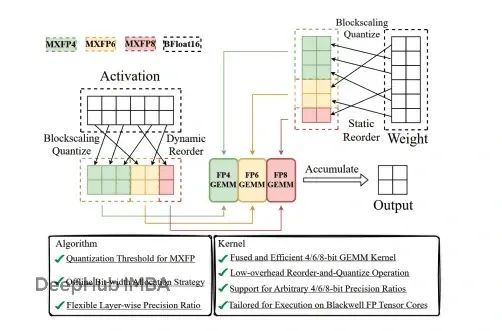
MXFP4量化:如何在80GB GPU上运行1200亿参数的GPT-OSS模型
GPT-OSS通过创新的量化技术实现了突破性进展。该系统能够在单个80GB GPU上运行1200亿参数模型,同时保持竞争性的基准测试性能。

AMD Ryzen AI Max+ 395四机并联:大语言模型集群推理深度测试
本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。
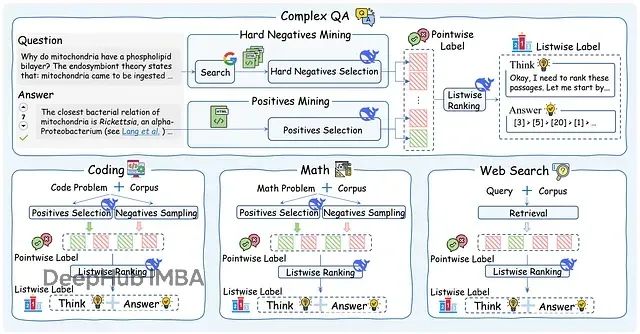
ReasonRank:从关键词匹配到逻辑推理,排序准确性大幅超越传统方法
本文深入分析ReasonRank,一个采用自动化数据合成框架和两阶段训练策略(监督微调+强化学习)的先进段落重排器,该系统在信息检索领域实现了突破性的推理能力

Dots.ocr:告别复杂多模块架构,1.7B参数单一模型统一处理所有OCR任务
本文将深入分析Dots.ocr的技术架构特点、性能表现以及在实际应用中的价值,探讨这一模型如何在参数效率与处理能力之间找到最佳平衡点。

JAX快速上手:从NumPy到GPU加速的Python高性能计算库入门教程
JAX代表了Python高性能数值计算领域的重要进展。通过提供与NumPy兼容的接口,结合强大的函数转换能力以及基于加速线性代数的高效硬件执行
提升LangChain开发效率:10个被忽视的高效组件,让AI应用性能翻倍
本文将系统分析LangChain框架中十个具有重要价值但使用率相对较低的核心组件,通过技术原理解析和实践案例说明,帮助开发者构建更高效、更智能、更具适应性的AI应用系统。
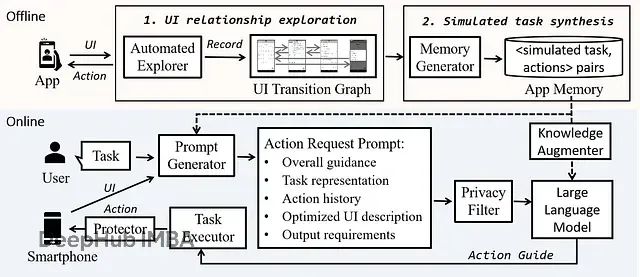
大型动作模型LAM:让企业重复任务实现80%效率提升的AI技术架构与实现方案
本文将深度剖析LAMs的技术架构,详细阐述其核心组件的设计原理、功能实现机制以及在实际业务场景中的应用模式

论文解读:单个标点符号如何欺骗LLM,攻破AI评判系统
本研究深入揭示了现有LLM评判器面临的系统性安全隐患,并提出了有效的防御解决方案。通过Master-RM模型的成功构建,证明了针对性的对抗训练能够在保持模型通用性能的前提下显著提升安全防护能力。
普通电脑也能跑AI:10个8GB内存的小型本地LLM模型推荐
本文将深入分析如何在本地硬件环境中部署先进的AI模型,并详细介绍当前最具代表性的轻量级模型解决方案。
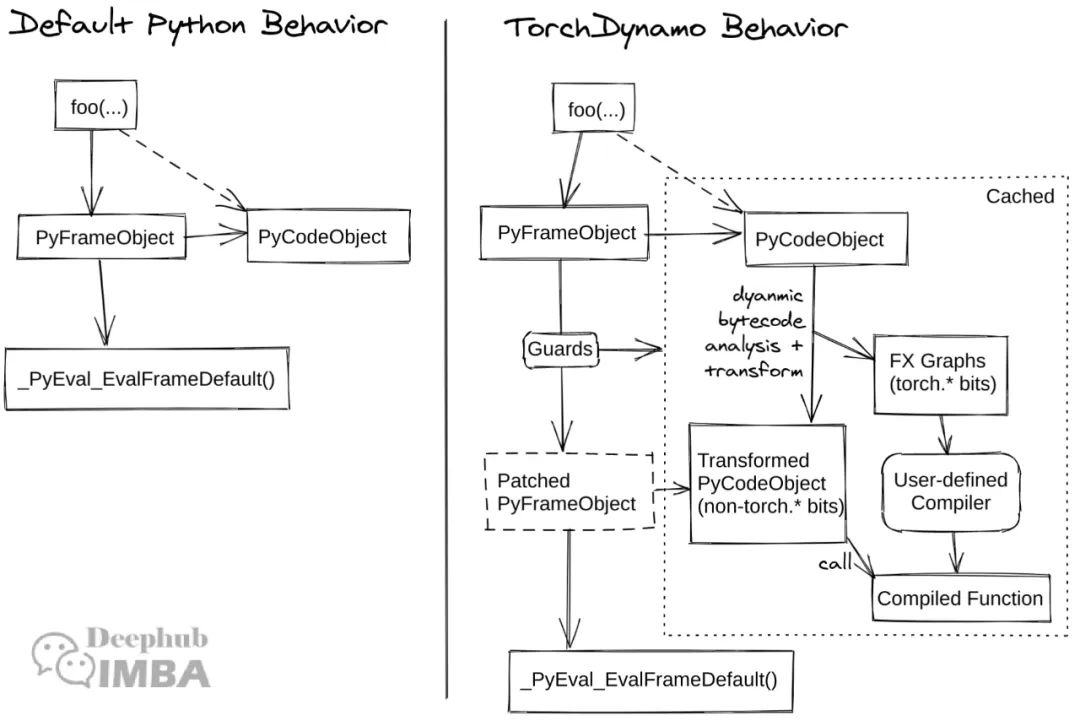
TorchDynamo源码解析:从字节码拦截到性能优化的设计与实践
本文深入解析PyTorch中TorchDynamo的核心架构和实现机制,通过PyTorch源码分析和关键文件导览,为开发者提供在Dynamo基础上设计扩展功能或新特性的技术指南。
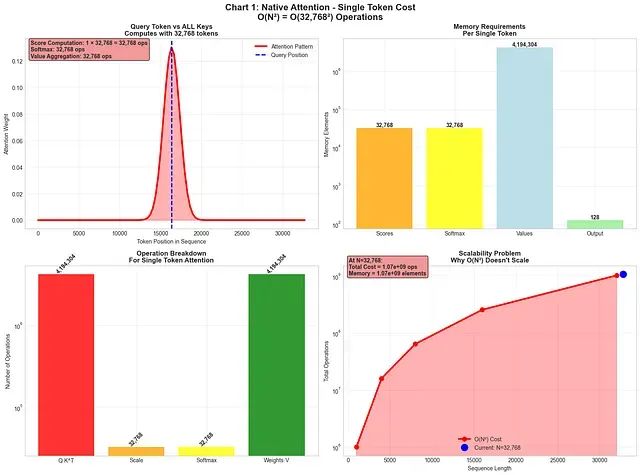
NSA稀疏注意力深度解析:DeepSeek如何将Transformer复杂度从O(N²)降至线性,实现9倍训练加速
本文将深入分析NSA的架构设计,通过详细的示例、可视化展示和数学推导,构建对其工作机制的全面理解,从高层策略到底层硬件实现均有涉及。
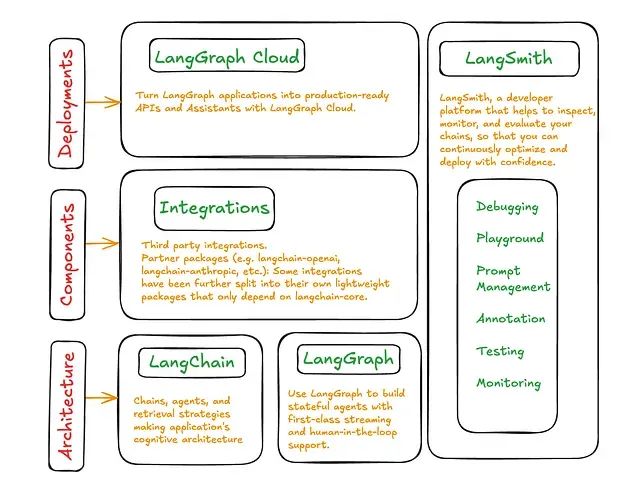
从零开始构建AI Agent评估体系:12种LangSmith评估方法详解
本文将深入探讨十二种不同的智能体评估技术,详细阐述每种技术的适用场景和实施方法。这些技术涵盖了从传统的预测答案与标准答案比较,到先进的实时反馈评估等多个层面,其中标准答案会随时间动态变化。
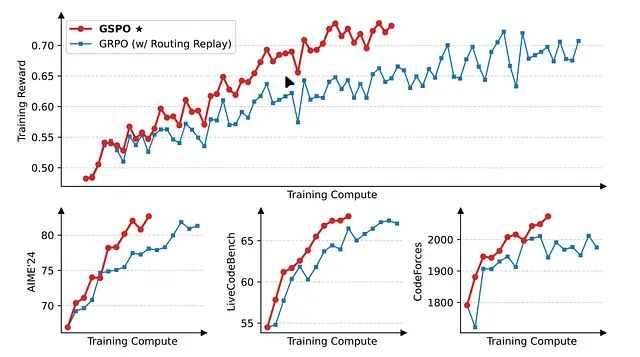
GSPO:Qwen让大模型强化学习训练告别崩溃,解决序列级强化学习中的稳定性问题
这是7月份的一篇论文,Qwen团队提出的群组序列策略优化算法及其在大规模语言模型强化学习训练中的技术突破
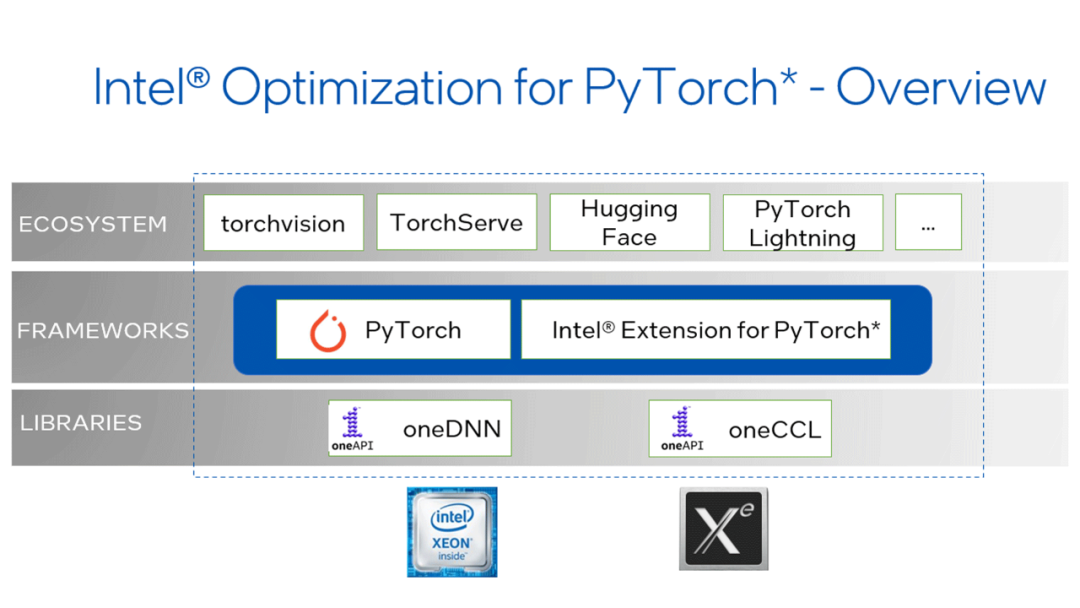
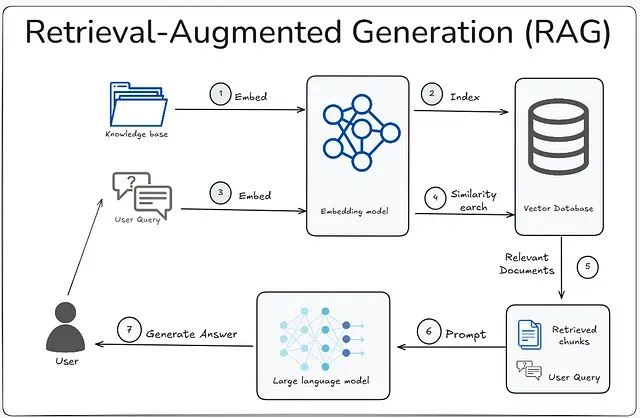
LLM开发者必备:掌握21种分块策略让RAG应用性能翻倍
本文将系统介绍21种文本分块策略,从基础方法到高级技术,并详细分析每种策略的适用场景,以帮助开发者构建更加可靠的RAG系统。
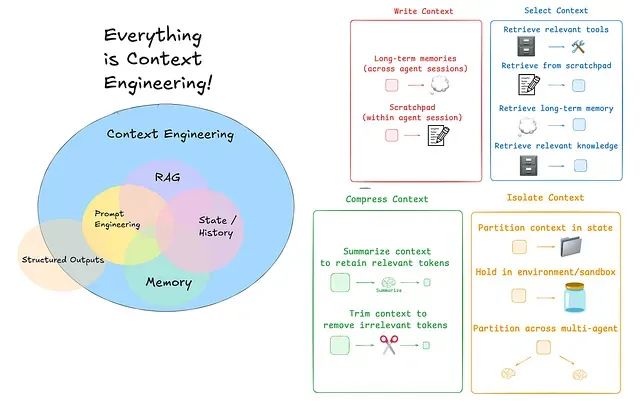
AI代理性能提升实战:LangChain+LangGraph内存管理与上下文优化完整指南
本文将深入探讨如何运用LangChain和LangGraph这两个构建AI代理、RAG应用和LLM应用的核心工具,系统性地实现上下文工程技术,以实现AI代理性能的全面优化。
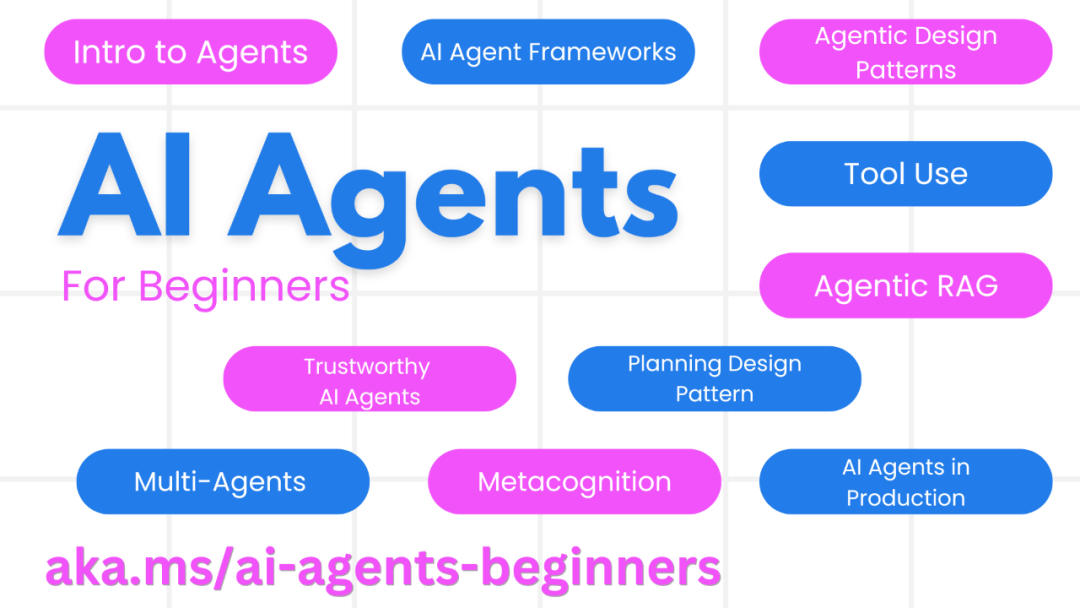
2025年AI智能体开发完全指南:10个GitHub顶级教程资源助你从入门到精通
本文精选了十个高质量的GitHub开源项目,涵盖从基础理论到实践应用的全方位学习路径,为AI开发者提供系统性的技术资源。



