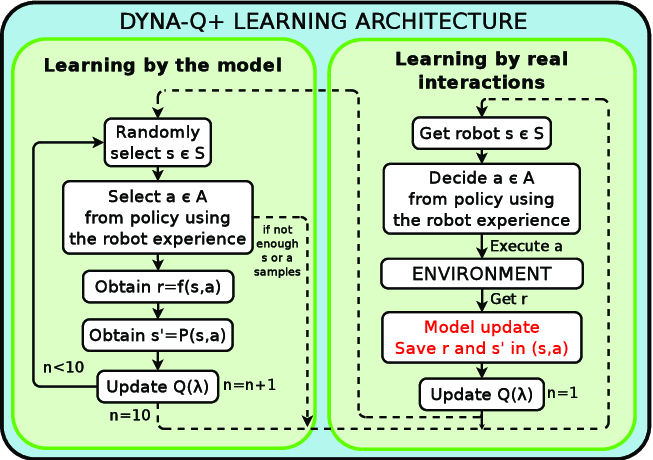
基于Dyna-Q强化学习的智能营销系统:融合贝叶斯生存模型与Transformer注意力机制的电商客户重参与策略优化
本文提出了一个集成三种核心技术的下一代智能优惠券分发系统:基于贝叶斯生存模型的重购概率预测、采用注意力机制的Transformer利润预测模型,以及用于策略持续优化的Dyna-Q强化学习代理。

解决语义搜索痛点,基于对比学习的领域特定文本嵌入模型微调实践
本文深入探讨了基于对比学习的嵌入模型微调技术,并通过AI职位匹配的实际案例验证了该方法的有效性。微调后的模型在测试集上实现了100%的准确率,充分证明了针对特定领域进行模型优化的必要性和可行性。
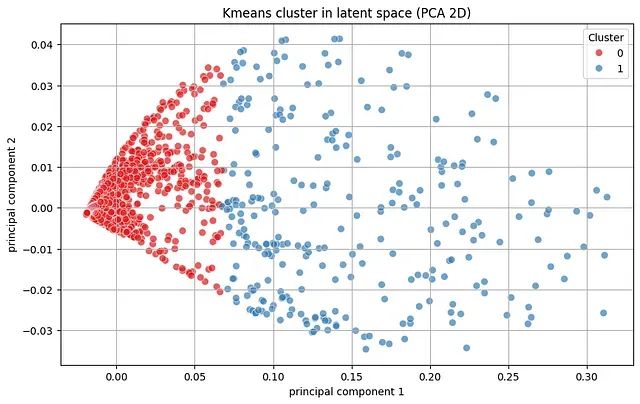
基于LSTM自编码器与KMeans聚类的时间序列无监督异常检测方法
本文提出的基于LSTM自编码器和KMeans聚类的组合方法,通过整合深度学习的序列建模能力与无监督聚类的模式分组优势,实现了对时间序列数据中异常模式的有效检测,且无需依赖标注的异常样本进行监督学习。

Chonkie:面向大语言模型的轻量级文本分块处理库
Chonkie作为一个专业的文本分块处理库,为大语言模型应用提供了全面而高效的解决方案。
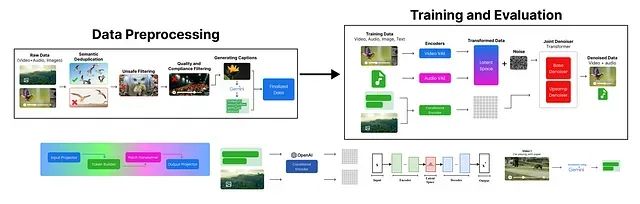
从零复现Google Veo 3:从数据预处理到视频生成的完整Python代码实现指南
本文详细介绍了一个简化版 Veo 3 文本到视频生成模型的构建过程。首先进行了数据预处理,涵盖了去重、不安全内容过滤、质量合规性检查以及数据标注等环节。
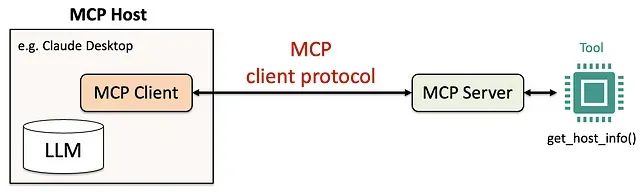
Python构建MCP服务器完整教程:5步打造专属AI工具调用系统
本文通过实际的代码示例和详细的配置步骤,展示了使用Python和Anthropic的mcp库构建MCP服务器的完整过程。我们从工具函数的设计开始,逐步介绍了MCP服务器的构建、AI代理的配置以及功能测试的验证方法。
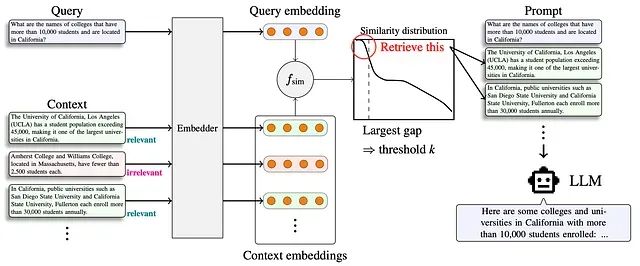
Adaptive-k 检索:RAG 系统中自适应上下文长度选择的新方法
Adaptive-k 代表了 RAG 系统从固定检索向智能化、查询感知检索的技术范式转变。该技术实现了显著的效率提升——在保持或提高准确性的同时,token 减少高达 99%。
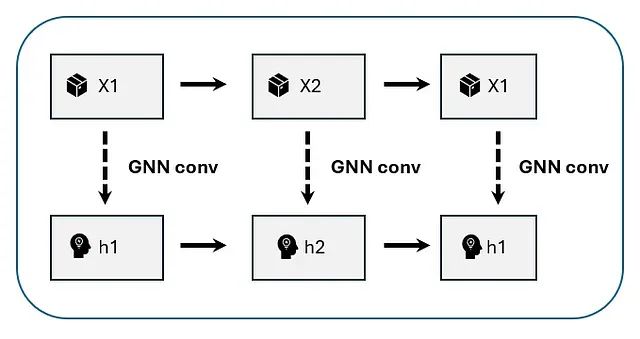
基于时间图神经网络多的产品需求预测:跨序列依赖性建模实战指南
本文展示了如何通过学习稀疏影响图、应用图卷积融合邻居节点信息,并结合时间卷积捕获演化模式的完整技术路径,深入分析每个步骤的机制原理和数学基础。
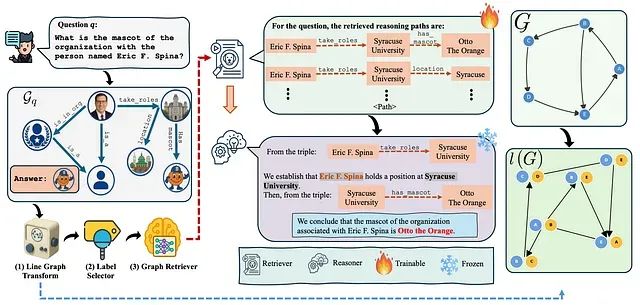
解决RAG检索瓶颈:RAPL线图转换让知识图谱检索准确率提升40%
本文深入探讨RAPL(Retrieval-Augmented Path Learning)框架,这是一个创新的人工智能架构,通过线图转换和合理化监督技术,从根本上改进了知识图谱环境下的检索增强生成系统。

ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
这个研究挑战了强化学习仅能放大现有模型输出能力的传统观点,通过实验证明长期强化学习训练(ProRL)能够使基础模型发现全新的推理策略。

SnapViewer:解决PyTorch官方内存工具卡死问题,实现高效可视化
SnapViewer项目通过重新设计数据处理流水线和渲染架构,成功解决了PyTorch官方内存可视化工具的性能瓶颈问题。
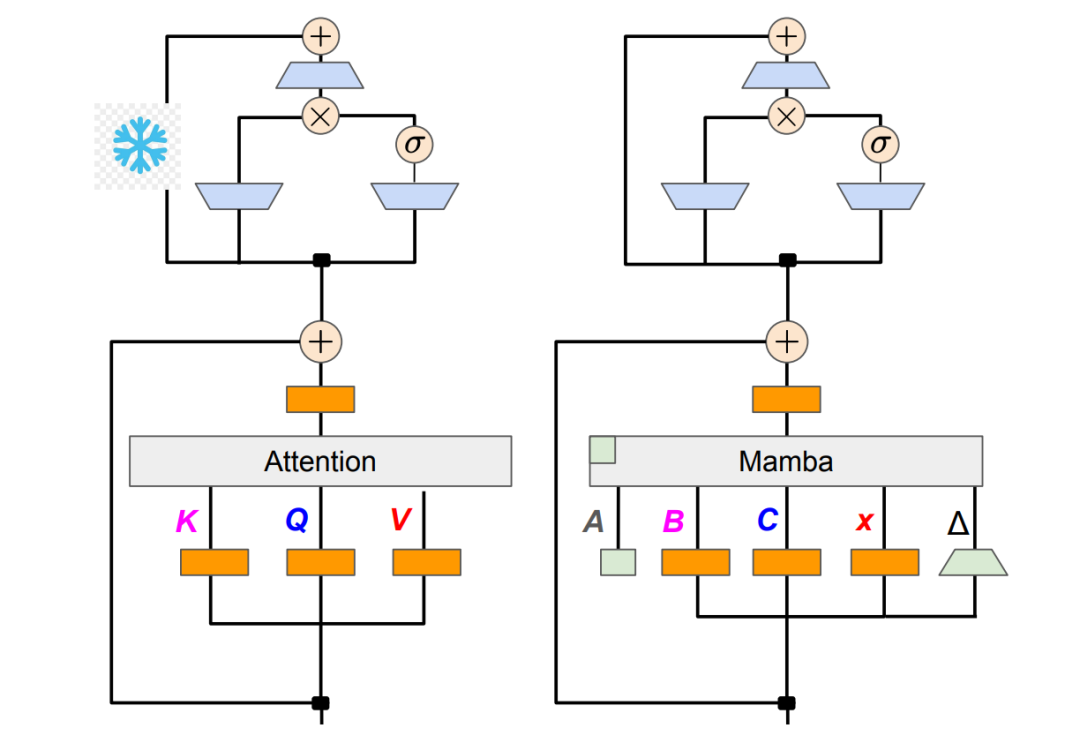
提升长序列建模效率:Mamba+交叉注意力架构完整指南
本文将深入分析Mamba架构中交叉注意力机制的集成方法与技术实现。
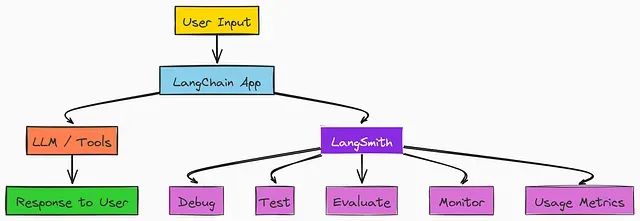
LangGraph实战教程:构建会思考、能记忆、可人工干预的多智能体AI系统
在本文中,我们将使用监督者方法构建一个多智能体系统。在此过程中,我们将介绍基础知识、在创建复杂的 AI 智能体架构时可能面临的挑战,以及如何评估和改进它们。
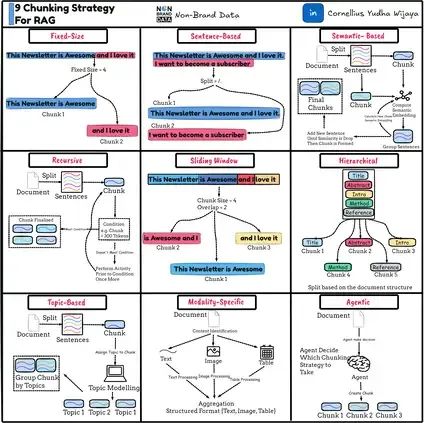
RAG系统文本分块优化指南:9种实用策略让检索精度翻倍
本文将深入分析九种主要的文本分块策略及其具体实现方法。下图概括了我们将要讨论的内容。
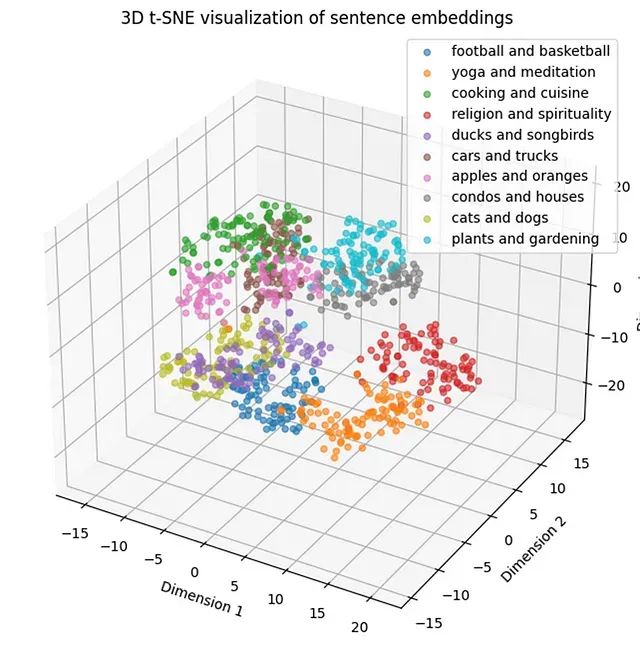
文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。

BayesFlow:基于神经网络的摊销贝叶斯推断框架
**BayesFlow** 是一个开源 Python 库,专门设计用于通过**摊销(Amortization)神经网络**来**加速和扩展贝叶斯推断**的能力。该框架通过训练神经网络来学习逆问题(从观测数据推断模型参数)或正向模型(从参数生成观测数据)的映射关系,
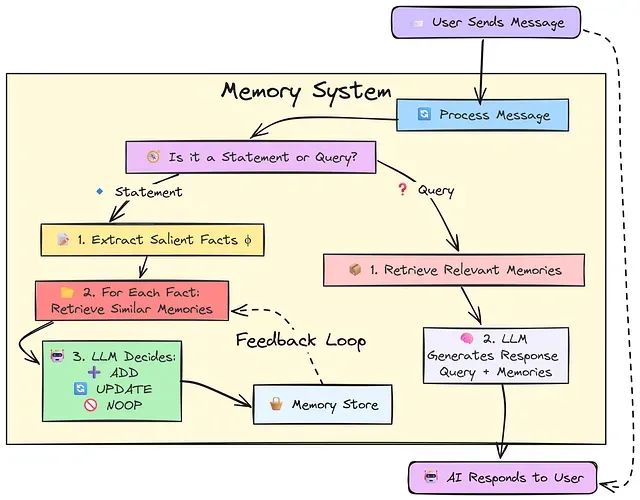
基于内存高效算法的 LLM Token 优化:一个有效降低 API 成本的技术方案
该方法的核心原理基于一个关键洞察:LLM 并非需要对每次用户输入都生成回复,而应当区分用户的信息陈述和实际查询请求,仅在后者情况下生成响应。
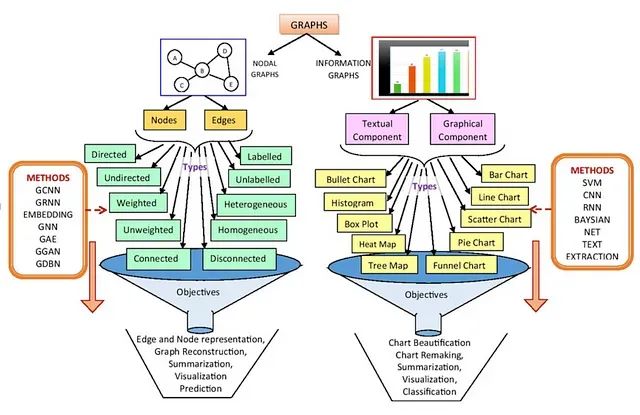
基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
大型概念模型(Large Concept Models, LCMs)与图神经网络的融合为这一挑战提供了创新解决方案,通过构建基于LangGraph的混合符号-语义处理管道,实现了更精准的情感分析、实体识别和主题建模能力。
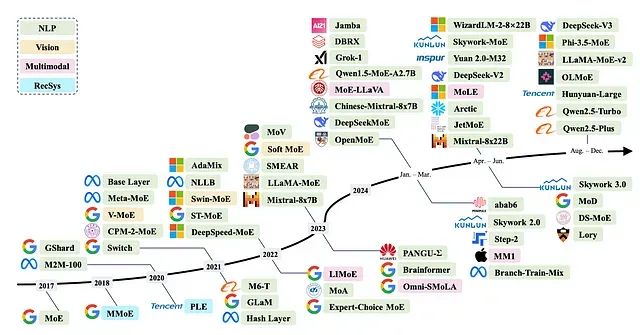
为什么混合专家模型(MoE)如此高效:从架构原理到技术实现全解析
本文将深入分析MoE架构的技术原理,探讨其在大型语言模型中被视为未来发展方向的原因,并详细介绍该架构在当前主要模型中的具体应用实现。



