【Python】Python寻找多维数组(numpy.array)中最大值的位置(行和列)
最近需要从热力图中找出关键点的坐标,也就是极大值的行和列。搜寻了网上的一些方法,在这里总结一下。使用numpy进行多维数组中最大值的行和列搜寻非常的灵活,有以下几种方法可供参考。二维数组方法一:np.max()函数 + np.where()函数如下图所示,x是一个 3×3 的二维np.array,首
机器学习强基计划0-2:什么是机器学习?和AI有什么关系?
用最通俗的例子和语言解释什么是机器学习,接着介绍机器学习和人工智能的关系,机器学习的用途以及学习路线
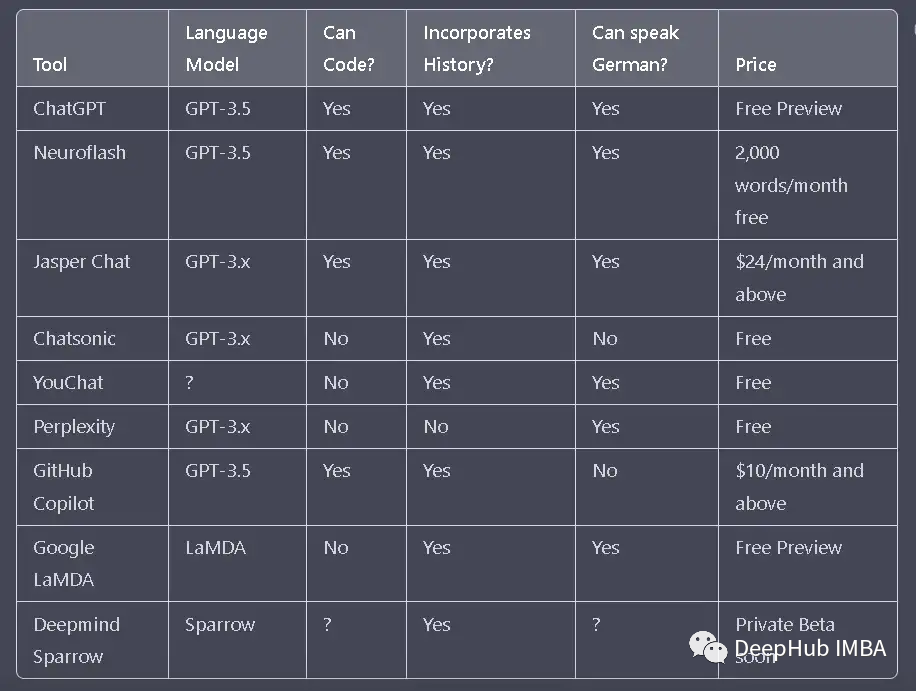
2023 年8个ChatGPT 的替代品
OpenAI 于 2022 年 11 月下旬推出的 ChatGPT 在网络世界引起了不小的轰动。其实还有许多其他的机器人在本文中,我将整理8 个 ChatGPT 替代方案。
写完Numpy100道基础练习题后的错误总结和语法总结
numpy100题错误总结和语法总结!!我都已经踩了无数个雷了!!
8种时间序列分类方法总结
对时间序列进行分类是应用机器和深度学习模型的常见任务之一。本篇文章将涵盖 8 种类型的时间序列分类方法。这包括从简单的基于距离或间隔的方法到使用深度神经网络的方法。这篇文章旨在作为所有时间序列分类算法的参考文章。
Hugging Face快速入门(重点讲解模型(Transformers)和数据集部分(Datasets))
1. Hugging Face是什么,提供了哪些内容2. Hugging Face模型的使用(Transformer类库)3. Hugging Face数据集的使用(Datasets类库)
CUDA error: device-side assert triggered
原因1:模型大小不匹配在定义模型的最终全连接层时,我没有将 196(斯坦福汽车数据集的类总数)作为输出单元的数量,而是使用了 195。错误通常在您执行反向传播的行中识别。您的损失函数将比较模型的输出和数据集中该观察的标签。万一您对标签和输出感到困惑,请参阅下面我如何定义它们:原因2:损失函数输入错误

深度学习中高斯噪声:为什么以及如何使用
在数学上,高斯噪声是一种通过向输入数据添加均值为零和标准差(σ)的正态分布随机值而产生的噪声。

可视化VIT中的注意力
ViT中最主要的就是注意力机制,所以可视化注意力就成为了解ViT的重要步骤,所以我们这里介绍如何可视化ViT中的注意力
一文读懂机器学习分类全流程
🏆在本文中,作者将带你了解机器学习分类的全流程,从问题分析>数据预处理>分类器选择>模型构建>精度评价>模型发布为Web应用。从0带读者入门机器学习分类。
2022年第二届长三角高校数学建模竞赛B题经验、论文、代码展示
2022年第二届长三角高校数学建模竞赛B题经验、论文、代码展示1、题目要求其中数据附件一数据(截图部分):附件二数据(部分截图):在这里插入代码片问题一到问题四的思路:针对问题一,对附件 1 中的 5 个表单的四个传感器数据进行分析,提取相关特征。研究发现 VMD 方法在可以避免模态混叠问题。VMD
wandb不可缺少的机器学习分析工具
wandb是一款优秀的机器学习模型训练分析跟踪工具,通过它我们可以和简洁的分析出训练过程中指标和参数的变化情况,来更好的帮助我对模型进行调优,通过它还能够使得我们进行协同工作,分析我们的训练结果,帮助更好更方便的复现我们的模型...

Jupyter Lab 的 10 个有用技巧
JupyterLab是 Jupyter Notebook「新」界面。它包含了jupyter notebook的所有功能,并升级增加了很多功能。
吴恩达 - 机器学习课程笔记(持续更新)
吴恩达机器学习

使用Stable Diffusion和Pokedex的描述生成神奇宝贝图片
还记得我们以前使用GAN、Clip、DALL-E生成神奇宝贝的文章吗,现在是时候使用Stable Diffusion了
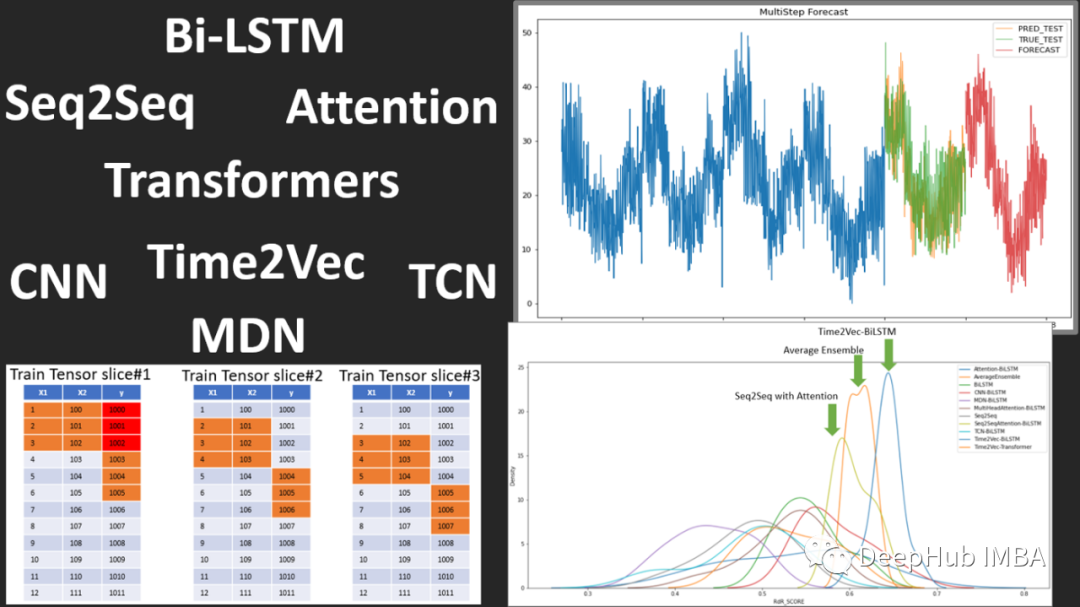
2022年深度学习在时间序列预测和分类中的研究进展综述
2022年时间序列预测中transformers衰落和时间序列嵌入方法的兴起,还有异常检测、分类也取得了进步,本文将尝试介绍一些在过去一年左右的时间里出现的更有前景和关键的论文
常用的优化器合集
总结了常用的优化器(SGD、Adagrad、Adadelta、RMSprop、Adam、Adamax、Nadam等等。),其中包括梯度下降法、动量优化法和自适应学习率优化算法三种,分别从原理、公式、优缺点以及pytorch及tensorflow2的官方代码展示这几个方面进行演示,最后可视化对比了各个
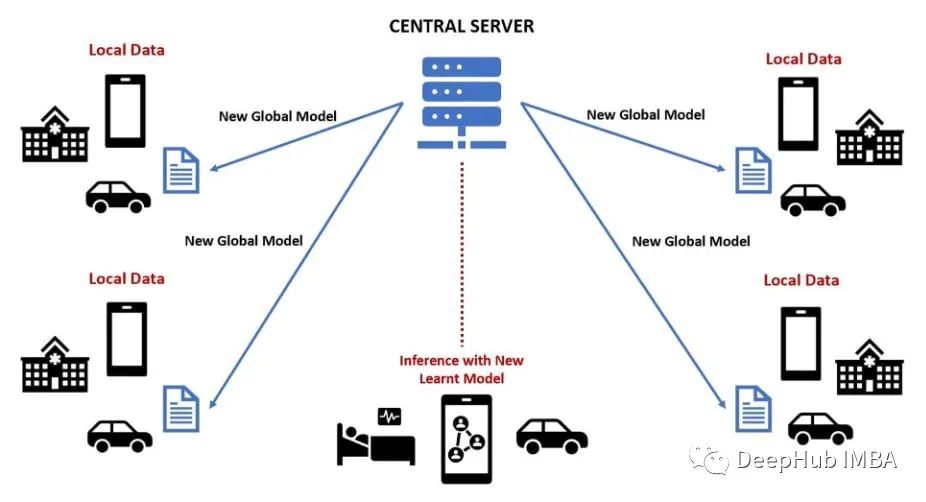
联邦学习 (FL) 中常见的3种模型聚合方法的 Tensorflow 示例
联合学习 (FL) 是一种出色的 ML 方法,它使多个设备(例如物联网 (IoT) 设备)或计算机能够在模型训练完成时进行协作,而无需共享它们的数据。
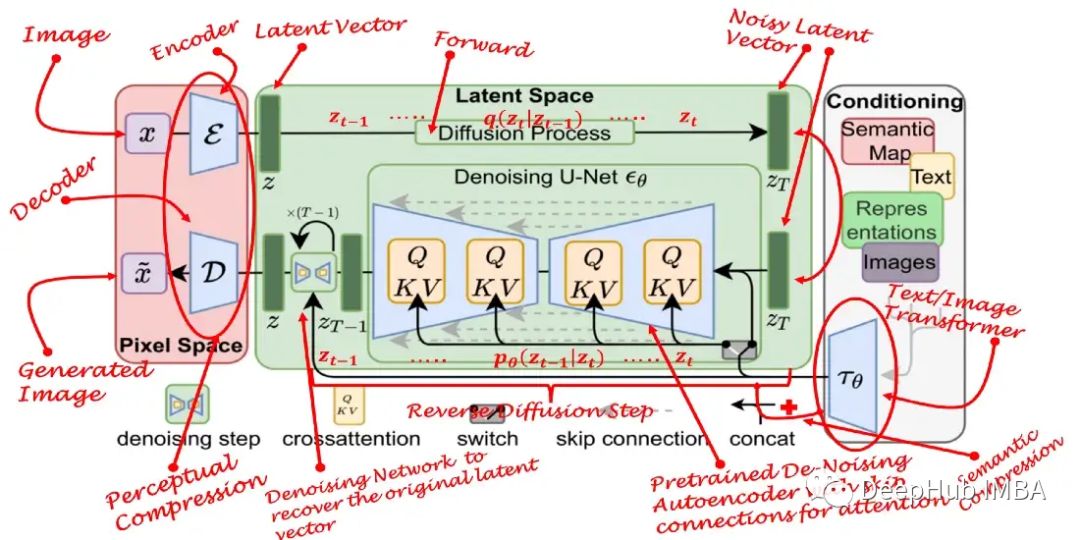
Diffusion 和Stable Diffusion的数学和工作原理详细解释
扩散模型的兴起可以被视为人工智能生成艺术领域最近取得突破的主要因素。而稳定扩散模型的发展使得我们可以通过一个文本提示轻松地创建美妙的艺术插图。所以在本文中,我将解释它们是如何工作的。
西瓜书习题 - 10.机器学习初步考试
西瓜书前9章内容考试题目



