李宏毅机器学习 hw2 boss baseline 解析
李宏毅机器学习 hw2 boss baseline
【ERNIE Bot】百度 | 文心一言初体验
文心一言(英文名:ERNIE Bot)是百度推出的最新一代大型语言模型,属于文心模型家族的新成员。它可以与人进行对话互动,回答问题,协助创作,并且能够高效便捷地帮助人们获取信息、知识和灵感。该模型基于飞桨深度学习平台和文心知识增强大模型,不断从海量数据和大规模知识中进行融合学习,具备知识增强、检索增
深度学习 简介
在介绍深度学习之前,我们先看下人工智能,机器学习和深度学习之间的关系:机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示:传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法
决策树(Decision Tree)
决策树算法原理及其应用介绍
tf-idf原理 & TfidfVectorizer参数详解及实战
tf-idf作为文体特征提取的常用统计方法之一,适合用于文本分类任务,本文从原理、参数详解及实战全方位详解tf-idf,掌握本篇即可轻松上手并用于文本数据分类。tf 表示(某单词在某文本中的出现次数/该文本中所有词的词数),idf表示(语料库中包含某单词的文本数、的倒数、取log),tf-idf则表
吴恩达机器学习课程资源(笔记、中英文字幕视频、课后作业,提供百度云镜像!)
课程,可以说是机器学习入门的第一课和最热门课程,作者在github开源了吴恩达机器学习个人笔记,用python复现了课程作业,成为热门项目,star数达到11671+。由于某种原因,国内用户访问github非常慢,下载资源经常失败,于是,为方便读者,我们把github内容做成镜像文件予以发布,针对非
注意力机制(Attention)原理详解
文章结构1. 为什么需要Attention2. Attention的基本原理3. Attention存在的问题总结1. 为什么需要Attention在了解Attention之前,首先应该了解为什么我们需要注意力机制。我们以传统的机器翻译为例子来说明为什么我们需要Attention。传统的机器翻译,也
Kaggle实战入门:泰坦尼克号生还预测(基础版)
泰坦尼克号生还预测是机器学习领域著名的数据科学竞赛平台kaggle的入门经典。本文对该数据的处理、分析、训练、预测进行了全流程介绍。
【联邦学习(Federated Learning)】- 从基本分布式思想开始理解联邦学习
机器学习和人工智能的成功离不开大量的数据,但随着人工智能在各行各业的应用落地,人们对于用户隐私数据保安全的关注度也在不断提高。如何在遵守更加严格的、新的隐私保护条例的前提下,解决数据碎片化和数据隔离的问题,是当前人工智能研究者必须解决的问题。在以上的背景基础下,人们开始寻求一种不必将所有数据集中到一
猿创征文 | re:Invent 朝圣之路:“云“行业风向标
猿创征文 | re:Invent 朝圣之路:“云“行业风向标
GPT-4技术报告
本技术报告介绍了GPT-4,一种能够处理图像和文本输入并产生文本输出的大型多模态模型。这些模型是一个重要的研究领域,因为它们具有广泛应用的潜力,如对话系统、文本摘要和机器翻译。因此,近年来,它们一直是人们感兴趣和取得进展的主题[1-34]。开发此类模型的主要目标之一是提高它们理解和生成自然语言文本的
数据挖掘(2.2)--数据预处理
描述数据的中心趋势、数据发散、数据清洗
Pytorch深度学习实战3-5:详解计算图与自动微分机(附实例)
本文详细介绍Pytorch中计算图的底层原理,讲解基于计算图的前向传播和反向传播,Pytorch自动微分原理以及梯度缓存、参数冻结等技巧
一文速学-GBDT模型算法原理以及实现+Python项目实战
上篇文章内容已经将Adaboost模型算法原理以及实现详细讲述实践了一遍,但是只是将了Adaboost模型分类功能,还有回归模型没有展示,下一篇我将展示如何使用Adaboost模型进行回归算法训练。首先还是先回到梯度提升决策树GBDT算法模型上面来,GBDT模型衍生的模型在其他论文研究以及数学建模比
机器学习中的数学原理——过拟合、正则化与惩罚函数
通过这篇博客,你将清晰的明白什么是过拟合、正则化、惩罚函数。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《 白话机器学习中的数学——过拟合、正则化与惩罚函数》
用chatgpt写insar地质灾害的论文,重复率只有1.8%,chatgpt4.0写论文不是梦
例如,长江三峡地区位于构造活跃带,地震活动频繁,同时地区地质构造多样,加之大规模水库建设和人类活动等因素,导致了地下水位变化、土体物理力学性质变化等,加剧了地质灾害的风险。近年来,多个地区的科学家们使用InSAR技术监测了不同规模的地面沉降,如华北平原、广东沿海、长江三角洲等地,以实现对地质灾害的实
机器学习:基于主成分分析(PCA)对数据降维
主成分分析算法(Principal Component Analysis, PCA)的目的是找到能用较少信息描述数据集的特征组合。它意在发现彼此之间没有相关性、能够描述数据集的特征,确切说这些特征的方差跟整体方差没有多大差距,这样的特征也被称为主成分。这也就意味着,借助这种方法,就能通过更少的特征捕
AI绘画进军三次元,有人用它打造赛博女友?(diffusion)
AI绘画大模型从学术界走入公众视野,对此你怎么看?欢迎大家体验
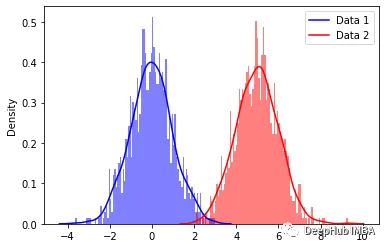
高斯混合模型 GMM 的详细解释
高斯混合模型(后面本文中将使用他的缩写 GMM)听起来很复杂,其实他的工作原理和 KMeans 非常相似,你甚至可以认为它是 KMeans 的概率版本。 这种概率特征使 GMM 可以应用于 KMeans 无法解决的许多复杂问题。
机器学习:基于KNN对葡萄酒质量进行分类
KNN对葡萄酒质量进行分类。该数据集采集于葡萄牙北部“Vinho Verde”葡萄酒,由于隐私和物流问题,只有理化变量特征是可以进行使用的(例如,数据集中没有关于葡萄品种、葡萄酒品牌、葡萄酒销售价格等的数据)。本篇notebook使用了红葡萄酒质量的数据集,并用KNN进行分类模型的训练。



