
对于二元分类,分类器输出一个实值分数,然后通过对该值进行阈值的区分产生二元的相应。例如,逻辑回归输出一个概率(一个介于0.0和1.0之间的值);得分等于或高于0.5的观察结果产生正输出(许多其他模型默认使用0.5阈值)。
但是使用默认的0.5阈值是不理想的。在本文中,我将展示如何从二元分类器中选择最佳阈值。本文将使用Ploomber并行执行我们的实验,并使用sklearn-evaluation生成图。
这里以训练逻辑回归为例。假设我们正在开发一个内容审核系统,模型标记包含有害内容的帖子(图片、视频等);然后,人工会查看并决定内容是否被删除。
构建简单的二元分类器
下面的代码片段训练我们的分类器:
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn_evaluation.plot import ConfusionMatrix
# matplotlib settings
mpl.rcParams['figure.figsize'] = (4, 4)
mpl.rcParams['figure.dpi'] = 150
# create sample dataset
X, y = datasets.make_classification(1000, 10, n_informative=5, class_sep=0.4)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# fit model
clf = LogisticRegression()
_ = clf.fit(X_train, y_train)
现在让我们对测试集进行预测,并通过混淆矩阵评估性能:
# predict on the test set
y_pred = clf.predict(X_test)
# plot confusion matrix
cm_dot_five = ConfusionMatrix(y_test, y_pred)
cm_dot_five
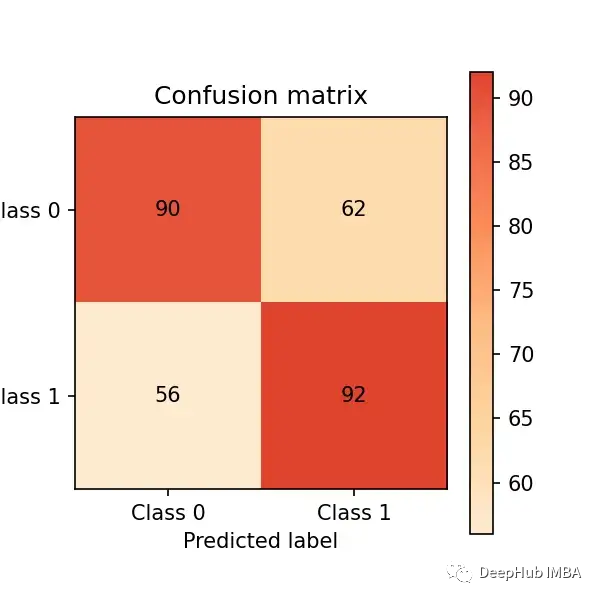
混淆矩阵总结了模型在四个区域的性能:
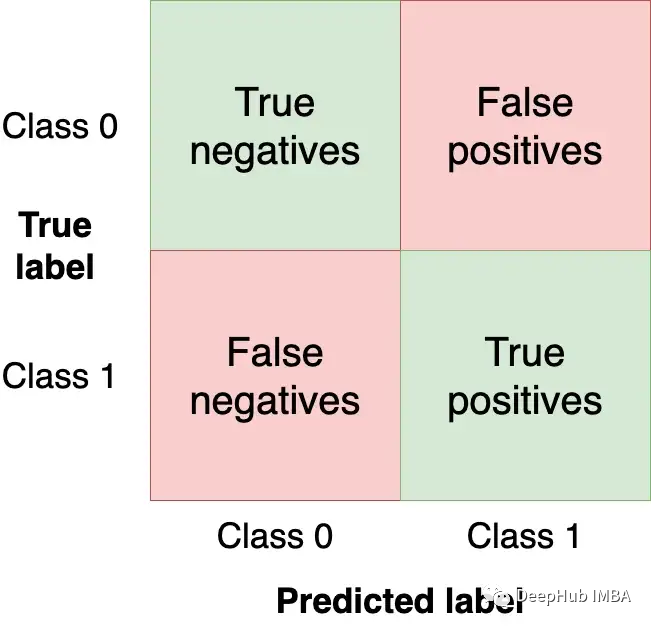
我们希望在左上和右下象限中获得尽可能多的观察值(从测试集),因为这些是我们的模型得到正确的观察值。其他象限是模型错误。
改变模型的阈值将改变混淆矩阵中的值。在前面的示例中,使用clf.predict,返回一个二元响应(即使用0.5作为阈值);但是我们可以使用clf.predict_proba函数获取原始概率并使用自定义阈值:
y_score = clf.predict_proba(X_test)
我们可以通过设置一个较低的阈值(即标记更多的帖子为有害的)来让我们的分类器更具侵略性,并创建一个新的混淆矩阵:
cm_dot_four = ConfusionMatrix(y_score[:, 1] >= 0.4, y_pred)
sklearn-evaluation库可以轻松比较两个矩阵:
cm_dot_five + cm_dot_four
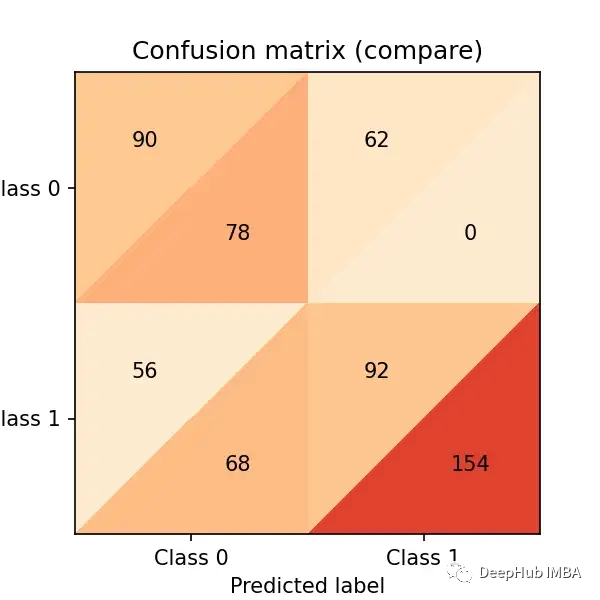
三角形的上面来自0.5的阈值,下面来自0.4的阈值:
- 两个模型对相同数量的观测结果都预测为0(这是一个巧合)。0.5阈值:(90 + 56 = 146)。0.4阈值:(78 + 68 = 146)
- 降低阈值会导致更多的假阴性(从56例降至68例)
- 降低阈值将大大增加真阳性(从92例增加154例)
微小的阈值变化极大地影响了混淆矩阵。我们只分析了两个阈值。那么如果能够分析跨所有值的模型性能,我们就可以好地理解阈值动态。但是在此之前,需要定义用于模型评估的新指标。
到目前为止,我们都是用绝对数字来评估我们的模型。为了便于比较和评估,我们现在将定义两个标准化指标(它们的值在0.0和1.0之间)。
精度precision是标记的观察事件的比例(例如,我们的模型认为有害的帖子,它们是有害的)。召回 recall是我们的模型检索到的实际事件的比例(即,从所有有害的帖子中,我们能够检测到它们的哪个比例)。
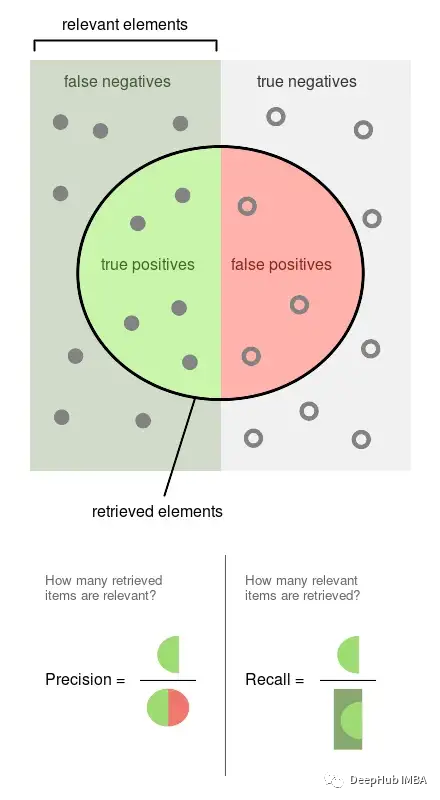
以上图片来自维基百科,可以很好的说明这两个指标是如何计算的,精确度和召回率都是比例关系,所以它们都是0比1的比例。
运行实验
我们将根据几个阈值获得精度、召回率和其他统计信息,以便更好地理解阈值如何影响它们。我们还将多次重复这个实验来测量可变性。
本节中的命令都是bash命令。需要在终端中执行它们,如果使用Jupyter可以使用%%sh魔法命令。
这里使用Ploomber Cloud运行我们的实验。因为它允许我们并行运行实验并快速检索结果。
创建了一个适合一个模型的Notebook,并为几个阈值计算统计数据,并行执行同一个Notebook20次。
curl -O https://raw.githubusercontent.com/ploomber/posts/master/threshold/fit.ipynb?utm_source=medium&utm_medium=blog&utm_campaign=threshold
让执行这个Notebook(文件中的配置会告诉Ploomber Cloud并行运行它20次):
ploomber cloud nb fit.ipynb
几分钟后,我们就会看到的20个实验完成了:
ploomber cloud status @latest --summary
status count
-------- -------
finished 20
Pipeline finished. Check outputs:
$ ploomber cloud products
让我们下载存储在.csv文件中的实验结果:
ploomber cloud download 'threshold-selection/*.csv' --summary
可视化实验结果
将加载所有实验的结果,并一次性将它们绘制出来。
from glob import glob
import pandas as pd
import numpy as np
paths = glob('threshold-selection/**/*.csv')
metrics = [pd.read_csv(path) for path in paths]
for idx, df in enumerate(metrics):
plt.plot(df.threshold, df.precision, color='blue', alpha=0.2,
label='precision' if idx == 0 else None)
plt.plot(df.threshold, df.recall, color='green', alpha=0.2,
label='recall' if idx == 0 else None)
plt.plot(df.threshold, df.f1, color='orange', alpha=0.2,
label='f1' if idx == 0 else None)
plt.grid()
plt.legend()
plt.xlabel('Threshold')
plt.ylabel('Metric value')
for handle in plt.legend().legendHandles:
handle.set_alpha(1)
ax = plt.twinx()
for idx, df in enumerate(metrics):
ax.plot(df.threshold, df.n_flagged,
label='flagged' if idx == 0 else None,
color='red', alpha=0.2)
plt.ylabel('Flagged')
ax.legend(loc=0)
ax.legend().legendHandles[0].set_alpha(1)
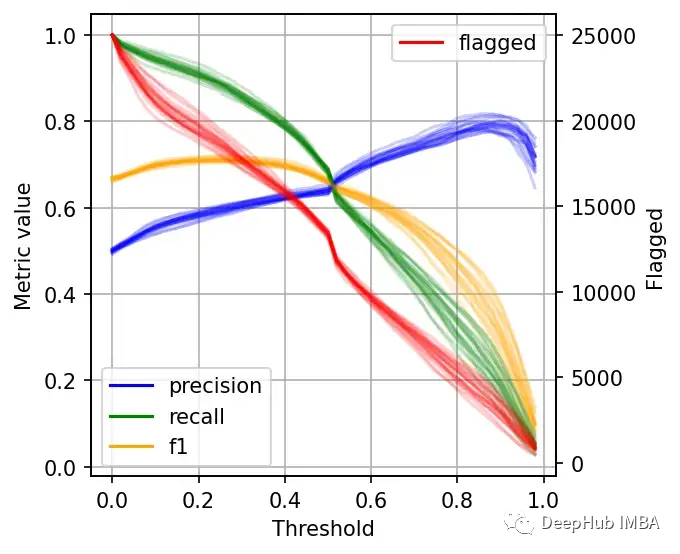
左边的刻度(从0到1)是我们的三个指标:精度、召回率和F1。F1分为精度与查全率的调和平均值,F1分的最佳值为1.0,最差值为0.0;F1对精度和召回率都是相同对待的,所以你可以看到它在两者之间保持平衡。如果你正在处理一个精确度和召回率都很重要的用例,那么最大化F1是一种可以帮助你优化分类器阈值的方法。
这里还包括一条红色曲线(右侧的比例),显示我们的模型标记为有害内容的案例数量。
在这个的内容审核示例中,可能有X个的工作人员来人工审核模型标记的有害帖子,但是他们人数是有限的,因此考虑标记帖子的总数可以帮助我们更好地选择阈值:例如每天只能检查5000个帖子,那么模型找到10,000帖并不会带来任何的提高。如果我人工每天可以处理10000贴,但是模型只标记了100贴,那么显然也是浪费的。
当设置较低的阈值时,有较高的召回率(我们检索了大部分实际上有害的帖子),但精度较低(包含了许多无害的帖子)。如果我们提高阈值,情况就会反转:召回率下降(错过了许多有害的帖子),但精确度很高(大多数标记的帖子都是有害的)。
所以在为我们的二元分类器选择阈值时,我们必须在精度或召回率上妥协,因为没有一个分类器是完美的。我们来讨论一下如何推理选择合适的阈值。
选择最佳阈值
右边的数据会产生噪声(较大的阈值)。需要稍微清理一下,我们将重新创建这个图,我们将绘制2.5%、50%和97.5%的百分位数,而不是绘制所有值。
shape = (df.shape[0], len(metrics))
precision = np.zeros(shape)
recall = np.zeros(shape)
f1 = np.zeros(shape)
n_flagged = np.zeros(shape)
for i, df in enumerate(metrics):
precision[:, i] = df.precision.values
recall[:, i] = df.recall.values
f1[:, i] = df.f1.values
n_flagged[:, i] = df.n_flagged.values
precision_ = np.quantile(precision, q=0.5, axis=1)
recall_ = np.quantile(recall, q=0.5, axis=1)
f1_ = np.quantile(f1, q=0.5, axis=1)
n_flagged_ = np.quantile(n_flagged, q=0.5, axis=1)
plt.plot(df.threshold, precision_, color='blue', label='precision')
plt.plot(df.threshold, recall_, color='green', label='recall')
plt.plot(df.threshold, f1_, color='orange', label='f1')
plt.fill_between(df.threshold, precision_interval[0],
precision_interval[1], color='blue',
alpha=0.2)
plt.fill_between(df.threshold, recall_interval[0],
recall_interval[1], color='green',
alpha=0.2)
plt.fill_between(df.threshold, f1_interval[0],
f1_interval[1], color='orange',
alpha=0.2)
plt.xlabel('Threshold')
plt.ylabel('Metric value')
plt.legend()
ax = plt.twinx()
ax.plot(df.threshold, n_flagged_, color='red', label='flagged')
ax.fill_between(df.threshold, n_flagged_interval[0],
n_flagged_interval[1], color='red',
alpha=0.2)
ax.legend(loc=3)
plt.ylabel('Flagged')
plt.grid()
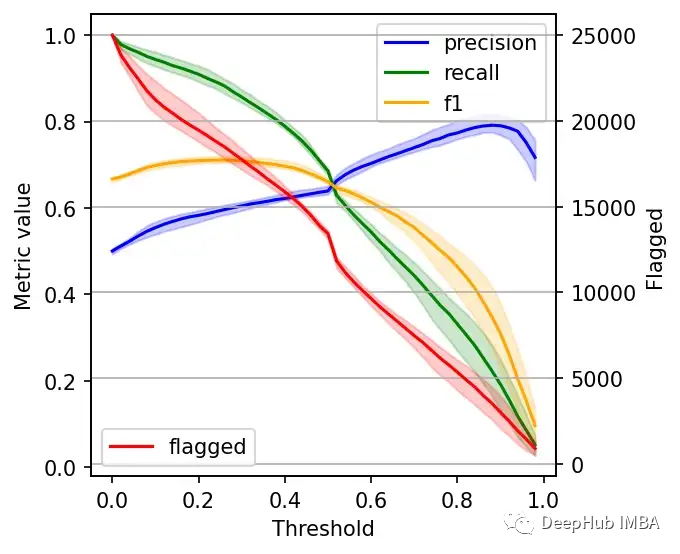
我们可以根据自己的需求选择阈值,例如检索尽可能多的有害帖子(高召回率)是否更重要?还是要有更高的确定性,我们标记的必须是有害的(高精度)?
如果两者都同等重要,那么在这些条件下优化的常用方法就是最大化F-1分数:
idx = np.argmax(f1_)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print(f'Max F1 score: {f1_[idx]:.2f}')
print('Metrics when maximizing F1 score:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
#结果
Max F1 score: 0.71
Metrics when maximizing F1 score:
- Threshold: 0.26
- Precision range: (0.58, 0.61)
- Recall range: (0.86, 0.90)
在很多情况下很难决定这个折中,所以加入一些约束条件会有一些帮助。
假设我们有10个人审查有害的帖子,他们可以一起检查5000个。那么让我们看看指标,如果我们修改了阈值,让它标记了大约5000个帖子:
idx = np.argmax(n_flagged_ <= 5000)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print('Metrics when limiting to a maximum of 5,000 flagged events:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
# 结果
Metrics when limiting to a maximum of 5,000 flagged events:
- Threshold: 0.82
- Precision range: (0.77, 0.81)
- Recall range: (0.25, 0.36)
如果需要进行汇报,我们可以在在展示结果时展示一些替代方案:比如在当前约束条件下(5000个帖子)的模型性能,以及如果我们增加团队(比如通过增加一倍的规模),我们可以做得更好。
总结
二元分类器的最佳阈值是针对业务结果进行优化并考虑到流程限制的阈值。通过本文中描述的过程,你可以更好地为用例决定最佳阈值。
如果你对这篇文章有任何问题,请随时留言。
另外,Ploomber Cloud!提供一些免费的算力!如果你需要一些免费的服务可以试试它。
作者:Eduardo Blancas