
通过这篇博客,你将清晰的明白什么是F值、交叉验证。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《 白话机器学习中的数学——F值与交叉验证》
文章目录
一、F值
在之前的学习中,我们已经学习了精确率Precision和召回率Recall,有没有这样一个值能够综合得考虑这两个值呢?如果只是简单地计算平均值并不算很好的方法。假设现在有两个模型,它们的精确率和召回率是这样的: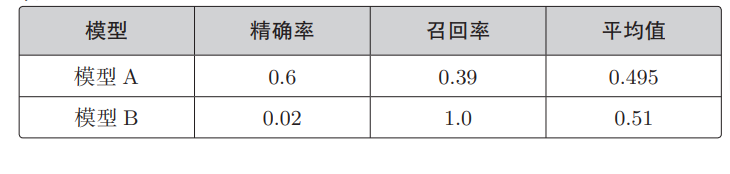
模型 B 的召回率是 1.0,也就是说所有的 Positive 数据都被分类为 Positive 了,但是精确率也实在是太低了。如果将所有的数据都分类为 Positive,那么召回率就是 1.0。但是这样一来,Negative 数据也会被分类为 Positive,所以精确率会变得很低。看一下两个模型的平均值,会发现模型 B 的更高。但它是把所有数据都分类为 Positive 的模型,精确率极低,仅为 0.02,并不能说它是好模型。
所以就出现了评定综合性能的指标 F 值。下面表达式中的 Fmeasure就是 F 值,Precision 是前面说的精确率,Recall 是召回率。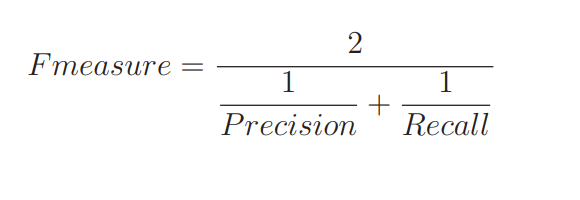

精确率和召回率只要有一个低,就会拉低 F 值,该指标考虑到了精确率和召回率的平衡。计算一下前面两个模型的 F 值就知道了:
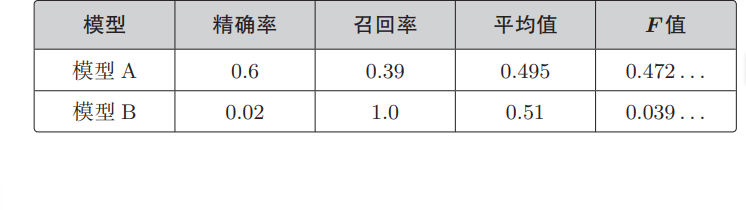
除 F1 值之外,还有一个带权重的 F 值指标: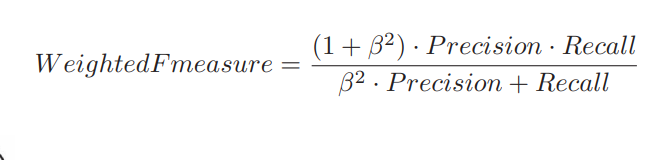
β 指的是权重,我们可以认为 F 值指的是带权重的 F 值,当权重为 1 时才是刚才介绍的 F1 值。带权重的 F 值更通用。F1 值在数学上是精确率和召回率的调和平均值。关于调和平均值,不需要太深入地了解。
二、交叉验证
把全部训练数据分为测试数据和训练数据的做法称为交叉验证。这是非常重要的方法,一定要记住哦。交叉验证的方法中,尤为有名的是 K 折交叉验证,掌握这种方法很有好处。
K 折交叉验证步骤如下:
- 把全部训练数据分为 K 份
- 将 K − 1 份数据用作训练数据,剩下的 1 份用作测试数据
- 每次更换训练数据和测试数据,重复进行 K 次交叉验证
- 最后计算 K 个精度的平均值,把它作为最终的精度
假如我们要进行 4 折交叉验证,那么就会这样测量精度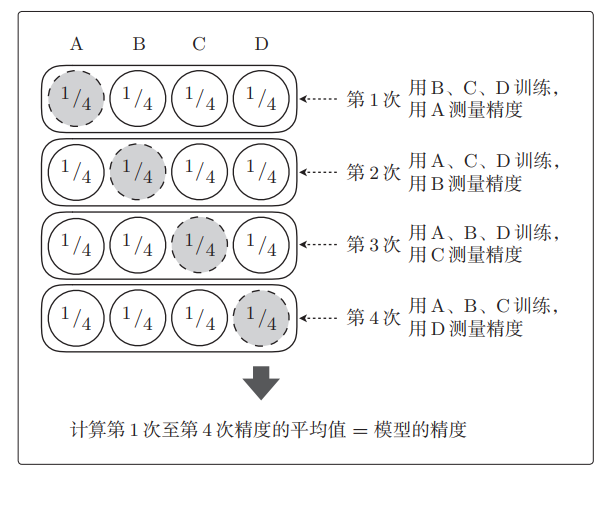
如果全部训练数据的量较大,这种方法必须训练多次,会比较花时间,不切实际地增加 K 值会非常耗费时间,所以我们必须要确
定一个合适的 K 值。
版权归原作者 爱睡觉的咋 所有, 如有侵权,请联系我们删除。