
前言
送什么礼物才能让女人满意,男人苦不堪言。像我这种有选择恐惧症的,每当节日来临一堆东西摆在面前都不知道挑啥(bushi,确实我还没有女友,落泪)。干脆就整个AHP帮咱挑选一个适合送给对象或者自己(也要爱自己喔~)的礼物,AHP原理其实都不需要理解,咱们会实际运用就贴切了,想要理解更多的欢迎看看我的博客有详解喔:层次分析法(AHP)原理以及应用。废话不多说了咱们开始吧!
一、建立层次结构模型
1.确定目标层
第一步我们需要确定我们的目标是什么,是选择个高端大气上档次的礼物呢,还是选择个低调奢华有内涵的礼物。 确定了我们需要挑选啥礼物的目标,会影响后续挑选礼物品质的打分。所以我们需要确定要挑选哪种品质的礼物。像我这种纯纯码农来说一般喜欢那种不贵且看上去很有内涵也上档次的礼物(是不是要求太高了)。当然大家可以自己决定想要什么,这里我先根据本人的目标来,大家看会一遍后自己就能做出来了:

2.确定准则层
第二步我们需要思考一些礼物的属性,也就是我们一般衡量礼物的价值要考虑到的东西。比如贵不贵啊、颜值咋样、精准小巧、实用性高啊等等。这些将属性影响到我们最终选择什么礼物,当然就是建立在各个因素对比之上。首先我们确定要选择礼物的考虑品质:

当然大家也可以自行选择不同的考虑因素。
3.确定方案层
第三步也就是供我们选择具体送的哪种类型的礼物,如巧克力、鲜花、口红、化妆品、游戏(、手表包包等等。

这几个礼物应该是目前最热门的吧,现在鲜花都不能当面送了有点可惜,当然大家可以根据自己想送的礼物来衡量。
这样一来我们就建立了层次模型了:

二、构造判断(成对比较)矩阵
1.构建对比矩阵
咱们提出了考虑因素和礼物当然要进行对比了,这里我们不是把所有因素加起来一起比较,而是两两进行比较:
- 不把所有因素放在一起比较,而是两两相互比较。
- 对此时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。
这里我们需要用到两两因素对比之间衡量二者重要性的标度:

现在我们要根据考虑因素来衡量一些各个因素之间到底哪个对于我们最终选择的目标最值得考虑:
价格实用性颜值精致数目价格11/41/223实用性41525颜值21/5112精致1/21/2115数目1/31/51/21/51
这里需要自己主观对比打分。
2.获取权向量
接下来我们需要通过列向量归一化和行向量归一化获取权向量,过程其实很简单并不复杂:
(1).列向量归一化
我们依据矩阵来看:矩阵为行
列,这第一行第一列就是
,那么列向量归一化运算就是把第一行第一个元素进行:
.
根据此运算我们把上述矩阵进行列向量归一化:
import numpy as np
a=np.array([1,4,2,0.5,1/3])
b=np.array([1/4,1,0.2,0.5,0.2])
c=np.array([1/2,5,1,1,0.5])
d=np.array([2,2,1,1,0.2])
e=np.array([3,6,2,5,1])
a/a.sum()
b/b.sum()
c/c.sum()
d/d.sum()
e/e.sum()
价格实用性颜值精致数目价格
0.1276
0.1162
0.0625
0.3225
0.1764
实用性
0.5106
0.4651
0.625
0.3225
0.3529
颜值
0.2553
0.0930
0.125
0.1612
0.1176
精致
0.0638
0.2325
0.125
0.1612
0.2941
数目
0.1276
0.0930
0.0625
0.0322
0.0588
(2).行和归一化
行和归一化为每行的数相加除以每行的个数,这里进行降维转为i行1列的矩阵,计算公式为:
ep=np.array([a,b,c,d,e]).T
np.sum(ep,axis=1)/5
array([0.16109798, 0.45525528, 0.15045596, 0.17535918, 0.05783161])
这便得到了我们的权向量。
3.计算特征值
我们假设特征值为,则线性代数特征公式为
,其中
为权向量。
计算
a=np.array([1,4,2,0.5,1/3])
b=np.array([1/4,1,0.2,0.5,0.2])
c=np.array([1/2,5,1,1,0.5])
d=np.array([2,2,1,1,0.2])
e=np.array([3,6,2,5,1])
em=np.array([a,b,c,d,e])
a=a/a.sum()
b=b/b.sum()
c=c/c.sum()
d=d/d.sum()
e=e/e.sum()
ep=np.array([a,b,c,d,e]).T
ex=np.sum(ep,axis=1)/5
lamda=np.matmul(ex,em)/ex
lamda.sum()*1/5
得到最大特征根:
5.476674227382576
三、一致性检验
现在我们需要巩固计算出来的成果,是否具有科学性和可靠性。这时候我们需要进行一致性检验,验证我们的模型是否具有说服力。
一致性检验原理: 检验我们构造的判断矩阵和一致矩阵是否有太大的差别。
1.第一步计算
我们需要计算衡量一致性的指标:
,有完全的一致性;
接近于0,有满意的一致性;
为了衡量的大小,引入随机一致性指标
2.第二步计
的值根据n的大小来决定:

3.第三步计算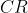
一般,当一致性比率时,认为A的不一致程度在容许范围之内,有满意的一致性,通过一致性检验。可用其归一化特征向量作为权向量,否则要重新构造成对比较矩阵A,对
加以调整。
这里我们的判断矩阵计算结果为:
最大特征根CIRICR结果5.47660.11161.120.0996通过,通过一次性检验。
四、填充权重矩阵
接下来我们要根据三种选择方案:口红、巧克力和手工DIY礼品来进行逐个影响因素对比。计算方法是和计算准则层方法一样的,这里便不再逐步进行计算:
价格口红巧克力DIY口红133巧克力1/311DIY1/311价格口红巧克力DIY权重(权向量)0.60.20.2最大特征根CIRICR结果300.520通过实用性口红巧克力DIY口红157巧克力1/513DIY1/71/31实用性口红巧克力DIY权重(权向量)0.73060.18840.0810最大特征根CIRICR结果3.06490.3240.520.0624通过
接下来大家可自行对比打分,这里不逐个演示了,直接进行填充权重矩阵:
指标权重口红巧克力DIY价格0.16100.60.20.2实用性0.45520.73060.18840.0810礼物颜值0.15040.10470.25830.6370小巧精致0.17530.25830.10470.6370礼物数量0.05780.14290.71430.1429
最终计算各个方案的得分:
口红:
巧克力:
DIY:0.2848
什么!!!!!!!为什么是口红??当场昏倒
总结
不管是男码,女码友,都应该收到一份示爱,也希望各位单身码友今年脱单,不单身的码友和另一半感情越来越好,不管在什么地方都有人爱你,我爱你们。


版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。