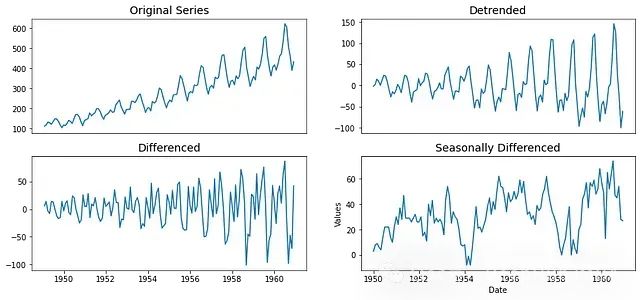
趋势还是噪声?ADF与KPSS检验结果矛盾时的高级时间序列处理方法
当我们遇到ADF检验失败而KPSS检验通过的情况时,这表明我们面对的是一个平稳但具有确定性趋势的时间序列。
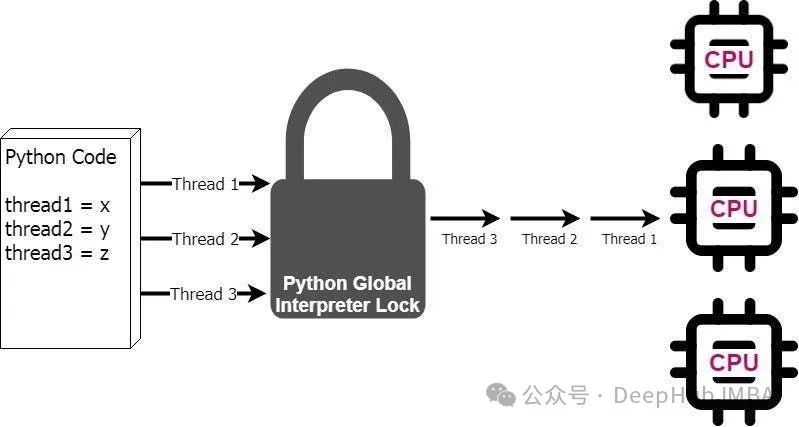
Python GIL(全局解释器锁)机制对多线程性能影响的深度分析
本文将主要基于CPython(用C语言实现的Python解释器,也是目前应用最广泛的Python解释器)展开讨论。
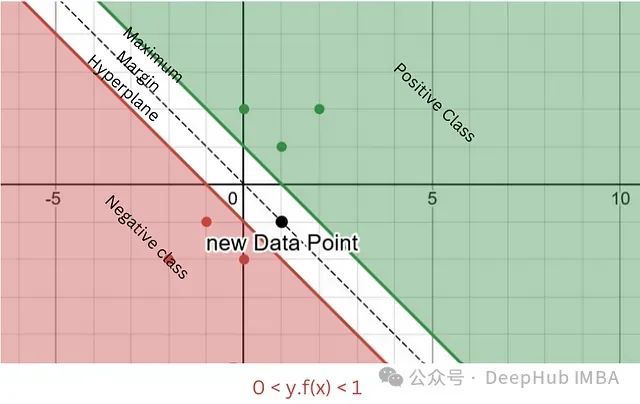
深入剖析SVM核心机制:铰链损失函数的原理与代码实现
铰链损失(Hinge Loss)是支持向量机(Support Vector Machine, SVM)中最为核心的损失函数之一。该损失函数不仅在SVM中发挥着关键作用,也被广泛应用于其他机器学习模型的训练过程中。
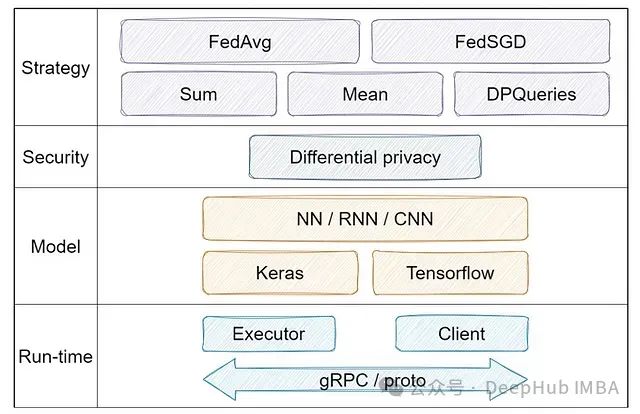
十大主流联邦学习框架:技术特性、架构分析与对比研究
联邦学习领域已发展出多个针对不同技术需求和应用场景的框架工具。这些工具在框架灵活性、使用便捷性和安全特性等方面各具特色。我们这里总结了10个联邦学习具有代表性框架
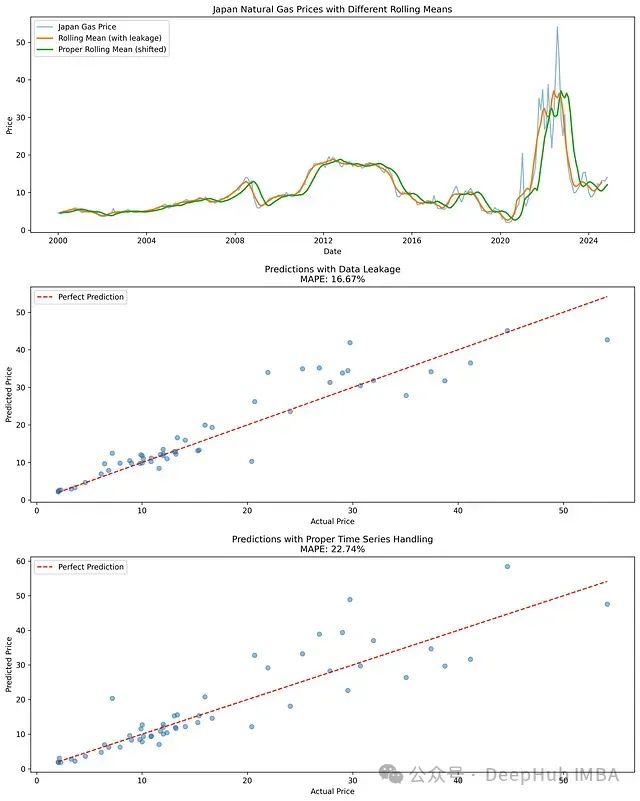
构建可靠的时间序列预测模型:数据泄露检测、前瞻性偏差消除与因果关系验证
在时间序列分析领域中,存在多种可能影响分析结果有效性的技术挑战。其中,数据泄露、前瞻性偏差和因果关系违反是最为常见且具有显著影响的问题。

Python高性能编程:五种核心优化技术的原理与Python代码
在性能要求较高的应用场景中,Python常因其执行速度不及C、C++或Rust等编译型语言而受到质疑。然而通过合理运用Python标准库提供的优化特性,我们可以显著提升Python代码的执行效率。
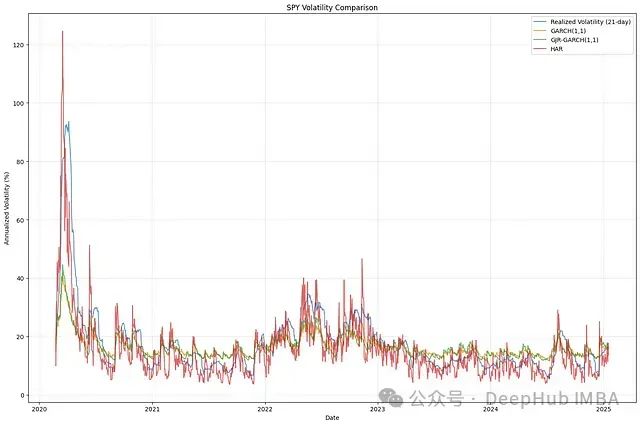
金融波动率的多模型建模研究:GARCH族与HAR模型的Python实现与对比分析
本文着重探讨三种主流波动率建模方法:广义自回归条件异方差模型(GARCH)、Glosten-Jagannathan-Runkle-GARCH模型(GJR-GARCH)以及异质自回归模型(HAR)
Python时间序列分析:使用TSFresh进行自动化特征提取
**TSFresh(基于可扩展假设检验的时间序列特征提取)**是一个专门用于时间序列数据特征自动提取的框架。该框架提取的特征可直接应用于分类、回归和异常检测等机器学习任务。
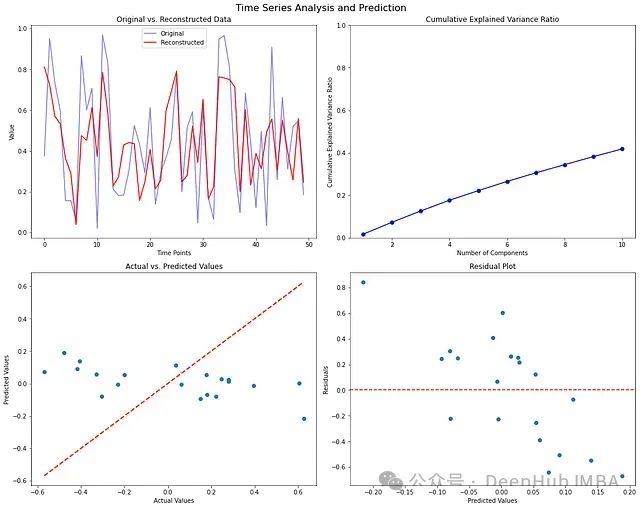
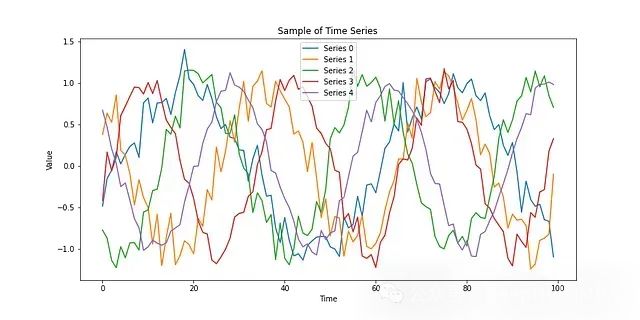
使用Python实现基于矩阵分解的长期事件(MFLEs)时间序列分析
基于矩阵分解的长期事件(Matrix Factorization for Long-term Events, MFLEs)分析技术应运而生。这种方法结合了矩阵分解的降维能力和时间序列分析的特性,为处理大规模时间序列数据提供了一个有效的解决方案。
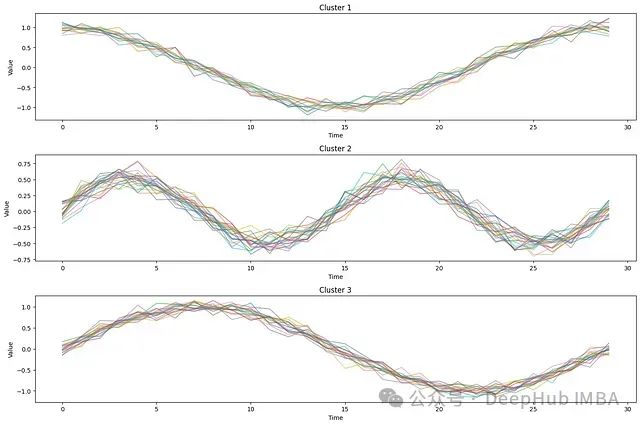
Python时间序列分析工具Aeon使用指南
**Aeon** 是一个专注于时间序列处理的开源Python库,其设计理念遵循scikit-learn的API风格,为数据科学家和研究人员提供了一套完整的时间序列分析工具。该项目保持活跃开发,截至2024年仍持续更新。
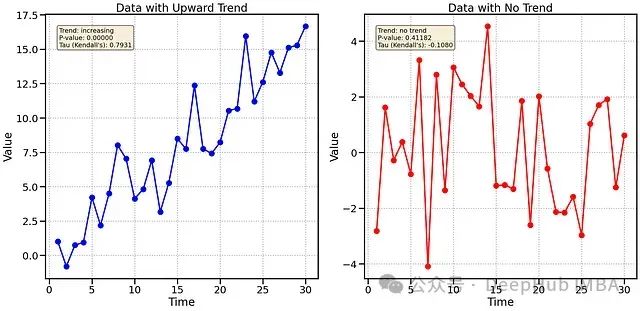
五种被低估的非常规统计检验方法:数学原理剖析与多领域应用价值研究
本文将详细介绍五种具有重要应用价值的统计检验方法,并探讨它们在免疫学(TCR/BCR库分析)、金融数据分析和运动科学等领域的具体应用。
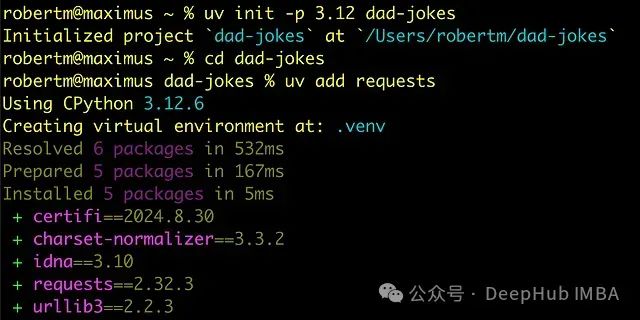
Python环境管理的新选择:UV和Pixi,高性能Python环境管理方案
UV和Pixi代表了Python环境管理工具的两种不同技术路线。UV专注于提供高性能的原生PyPI包管理解决方案,而Pixi则致力于桥接Conda生态系统和PyPI。

10个必备Python调试技巧:从pdb到单元测试的开发效率提升指南
本文将介绍10个实用的调试方法,帮助开发者更有效地定位和解决问题。
智谱AI批量文章生成工具:Python + PyCharm从安装到实战
批量生成:支持同时生成多个高质量文章,内容符合SEO需求。自动保存:生成的文章按主题保存在本地,文件名即主题名称。实时进度显示:在生成过程中,输出标题名称、线程编号和时间戳。内容去重:避免重复生成内容,确保文件唯一性。本文从安装 Python 和 PyCharm 开始,详细介绍了如何注册智谱AI账号
AI高清数字人wav2lip 256泛化模型,数字人本地部署完整源码,分享参考
AI高清数字人本地部署的源码分享,wav2lip泛化模型
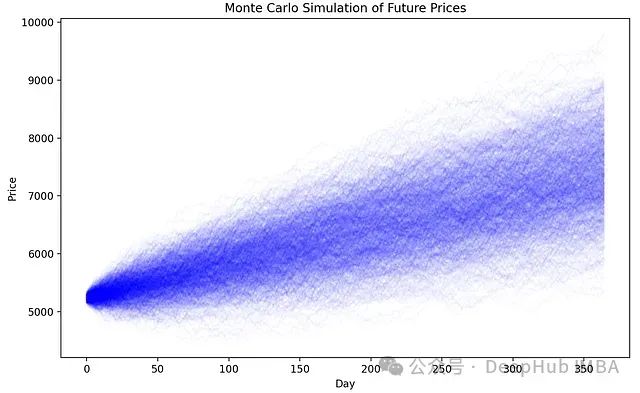
Python量化投资实践:基于蒙特卡洛模拟的投资组合风险建模与分析
蒙特卡洛模拟是一种基于重复随机抽样获取数值结果的计算算法。在金融应用领域,蒙特卡洛模拟主要用于股票和加密货币市场的分析。
【人工智能】基于PyTorch的深度强化学习入门:从DQN到PPO的实现与解析
深度强化学习(Deep Reinforcement Learning)是一种结合深度学习和强化学习的技术,适用于解决复杂的决策问题。深度Q网络(DQN)和近端策略优化(PPO)是其中两种经典的算法,被广泛应用于游戏、机器人控制等任务中。本文将从零讲解深度强化学习的基础概念,深入探讨DQN和PPO的核
AI:paddlepaddle2.6,paddleorc2.8,cuda12,cudnn,nccl,python10环境
1.安装英伟达显卡驱动首先需要到NAVIDIA官网去查自己的电脑是不是支持GPU运算。。打开后的界面大致如下,只要里边有对应的型号就可以用GPU运算,并且每一款设备都列出来相关的计算能力(Compute Capability)。如果是ubuntu系统:明确了显卡性能后,接下来就开始在ubuntu系统
【人工智能学习之STGCN训练自己的数据集】
注意这里的默认的layout如果符合自己定义的姿态就不用修改,否则需要自定义一个,本文采用的openpose即默认的openpose的18个关键点,不需要修改。得到了每个视频的json文件之后,需要我们手动将data目录下的json文件分配到train和val下,一般按照9:1划分。如果你的open



